





The Guts n’ Glory of Database InternalsSeeing the forest for the trees
In my previous post, I talked about B+Trees and how they work. Unfortunately, just having a B+Tree isn’t enough. A B+Tree allows you to do queries (including range queries) over a single dimension. In other words, in the case of our users’ data, we can easily use the B+Tree to find a particular entry by the user’s id.
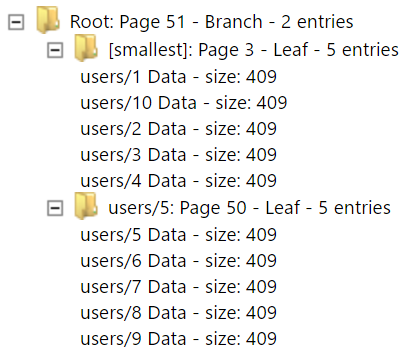
However, if we wanted to find a user by email, or by name, a B+Tree of the users’ ids isn’t very helpful. That means that if we wanted to do a query based on the user’s email, we would need to do a table scan, run over all the records in the database and match each of them to the email we are looking for. That has a pretty significant cost to it, and it is generally something that you want to avoid at all costs.
This is where we introduce another B+Tree, this one using the users’ email as the key, and whose value is the users’ id. It looks something like this:
- bar@funyun.org –> users/12
- foo@example.com –> users/1
So finding a user by their email is going to involve:
- Searching for the relevant email in the emails B+Tree.
- Once found, searching for the user’s id in the documents B+Tree.
In other words, we have to do 2 B+Tree lookups (at a cost of O(logN) each) to do this lookup.
Congratulation, you just used an index. You have probably heard of indexes, and how they can dramatically improve performance (and kill it). At the most basic level, an index is just another B+Tree in the system that has some of the records’ data indexed. The email B+Tree is what happens when you index an email column, for example.
And it is also the reason why indexes are expensive. Consider what happens when you insert new users into such a system. The database is going to update the two B+Trees. One for the actual data, and the other for the email that has the key of the data. And while we can arrange for the user’s id to be sequential, it is very unlikely that the emails will be sequential, so it is likely to be a bit more fragmented. That said, the index isn’t going to be as big as the actual data, so more entries are going to fit per page. In particular, while we can fit 5 entries per leaf page in the data B+Tree, the email index B+Tree is going to be around 70 entries per leaf page. So that should help keep it shallower than the data B+Tree (thus cheaper).
Note that in database terms, both B+Trees are actually indexes. The data B+Tree is an clustered index on the user id, and the email B+Tree is a non clustered index on the email. What is the difference between the two? A non clustered index contains as its value the key to find the relevant record. A clustered index contain the actual record data. In other words, after looking up a non clustered index, we need to go to the clustered index to find the actual data, while if we are using a clustered index, we are done with just one lookup.
This is also the reason that you often have to do a balancing act, you have to chose what fields you’ll index, because the more fields you have indexes, the faster your queries can be (O(logN) vs. O(N)), but on the other hand, that means that you need to update more B+Tree.
Finally, I’ll invite you think what happens if we have an index (B+Tree) on a date field. For example, LastLogin field, and we wanted say “Gimme all the users who haven’t logged in for the past 30 days”. How would you do that, and what would the cost be, using the system I outlined in this post?
More posts in "The Guts n’ Glory of Database Internals" series:
- (08 Aug 2016) Early lock release
- (05 Aug 2016) Merging transactions
- (03 Aug 2016) Log shipping and point in time recovery
- (02 Aug 2016) What goes inside the transaction journal
- (18 Jul 2016) What the disk can do for you
- (15 Jul 2016) The curse of old age…
- (14 Jul 2016) Backup, restore and the environment…
- (11 Jul 2016) The communication protocol
- (08 Jul 2016) The enemy of thy database is…
- (07 Jul 2016) Writing to a data file
- (06 Jul 2016) Getting durable, faster
- (01 Jul 2016) Durability in the real world
- (30 Jun 2016) Understanding durability with hard disks
- (29 Jun 2016) Managing concurrency
- (28 Jun 2016) Managing records
- (16 Jun 2016) Seeing the forest for the trees
- (14 Jun 2016) B+Tree
- (09 Jun 2016) The LSM option
- (08 Jun 2016) Searching information and file format
- (07 Jun 2016) Persisting information
Comments
Comment preview