The Uber Engineering group have posted a really great blog post about their move from Postgres to MySQL. I mean that quite literally, it is a pleasure to read, especially since they went into such details as the on-disk format and the implications of that on their performance.
For fun, there is another great post from Uber, about moving from MySQL to Postgres, which also has interesting content.
Go ahead and read both, and we’ll talk when you are done. I want to compare their discussion to what we have been doing.
In general, Uber’s issue fall into several broad categories:
- Secondary indexes cost on write
- Replication format
- The page cache vs. buffer pool
- Connection handling
Secondary indexes
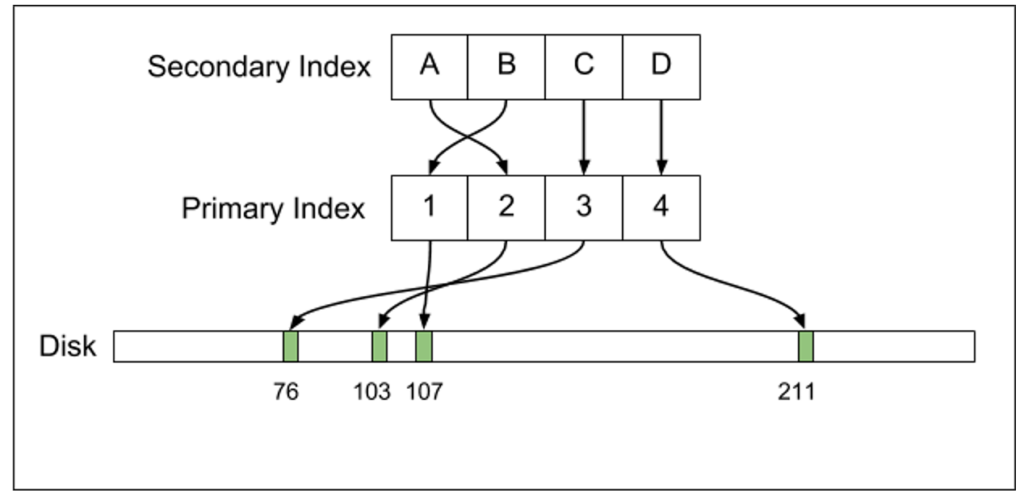
Postgres maintain a secondary index that points directly to the data on disk, while MySQL has a secondary index that has another level of indirection. The images show the difference quite clearly:
| Postgres | MySQL |
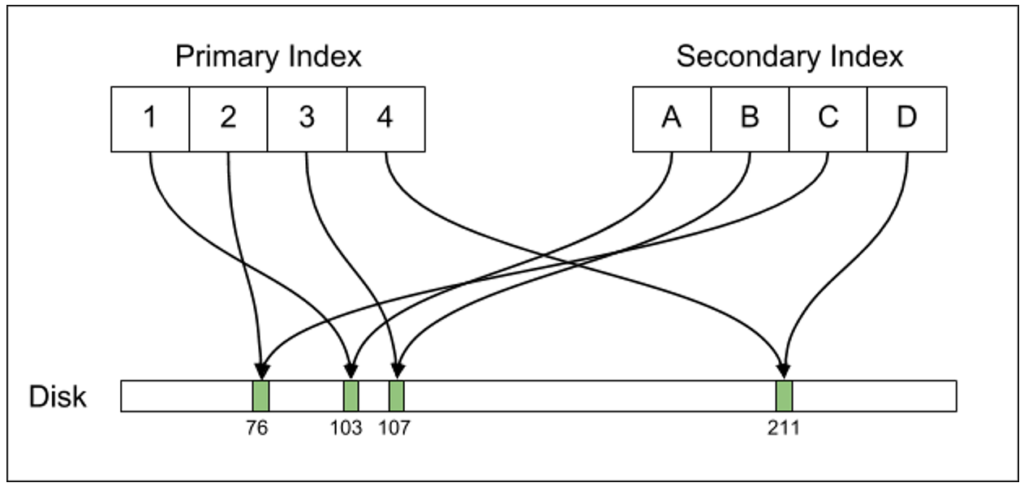 | 
|
I have to admit that this is the first time that I ever considered the fact that the indirection’s manner might have any advantage. In most scenarios, it will turn any scan on a secondary index into an O(N * logN) cost, and that can really hurt performance. With Voron, we have actually moved in 4.0 from keeping the primary key in the secondary index to keeping the on disk position, because the performance benefit was so high.
That said, a lot of the pain the Uber is feeling has to do with the way Postgres has implemented MVCC. Because they write new records all the time, they need to update all indexes, all the time, and after a while, they will need to do more work to remove the old version(s) of the record. In contrast, with Voron we don’t need to move the record (unless its size changed), and all other indexes can remain unchanged. We do that by having a copy on write and a page translation table, so while we have multiple copies of the same record, they are all in the same “place”, logically, it is just the point of view that changes.
From my perspective, that was the simplest thing to implement, and we get to reap the benefit on multiple fronts because of this.
Replication format
Postgres send the WAL over the wire (simplified, but easier to explain) while MySQL send commands. When we had to choose how to implement over the wire replication with Voron, we also sent the WAL. It is simple to understand, extremely robust and we already had to write the code to do that. Doing replication using it also allows us to exercise this code routinely, instead of it only running during rare crash recovery.
However, sending the WAL has issues, because it modify the data on disk directly, and issue there can cause severe problems (data corruption, including taking down the whole database). It is also extremely sensitive to versioning issues, and it would be hard if not impossible to make sure that we can support multiple versions replicating to one another. It also means that any change to the on disk format needs to be considered with distributed versioning in mind.
But what killed it for us was the fact that it is almost impossible to handle the scenario of replacing the master server automatically. In order to handle that, you need to be able to deterministically let the old server know that it is demoted and should accept no writes, and the new server that it can now accept writes and send its WAL onward. But if there is a period of time in which both can accept write, then you can’t really merge the WAL, and trying to is going to be really hard. You can try using distributed consensus to run the WAL, but that is really expensive (about 400 writes / second in our benchmark, which is fine, but not great, and impose a high latency requirement).
So it is better to have a replication format that is more resilient to concurrent divergent work.
OS Page Cache vs Buffer Pool
From the post:
Postgres allows the kernel to automatically cache recently accessed disk data via the page cache. … The problem with this design is that accessing data via the page cache is actually somewhat expensive compared to accessing RSS memory. To look up data from disk, the Postgres process issues lseek(2) and read(2) system calls to locate the data. Each of these system calls incurs a context switch, which is more expensive than accessing data from main memory. … By comparison, the InnoDB storage engine implements its own LRU in something it calls the InnoDB buffer pool. This is logically similar to the Linux page cache but implemented in userspace. While significantly more complicated than Postgres’s design…
So Postgres is relying on the OS Page Cache, while InnoDB implements its own. But the problem isn’t with relying on the OS Page Cache, the problem is how you rely on it. And the way Postgres is doing that is by issuing (quite a lot, it seems) system calls to read the memory. And yes, that would be expensive.
On the other hand, InnoDB needs to do the same work as the OS, with less information, and quite a bit of complex code, but it means that it doesn’t need to do so many system calls, and can be faster.
Voron, on the gripping hand, relies on the OS Page Cache to do the heavy lifting, but generally issues very few system calls. That is because Voron memory map the data, so access it is usually a matter of just pointer dereference, the OS Page Cache make sure that the relevant data is in memory and everyone is happy. In fact, because we memory map the data, we don’t have to manage buffers for the system calls, or to do data copies, we can just serve the data directly. This ends up being the cheapest option by far.
Connection handling
Spawning a process per connection is something that I haven’t really seen since the CGI days. It seems pretty harsh to me, but it is probably nice to be able to kill a connection with a kill –9, I guess. Thread per connection is also something that you don’t generally see. The common situation today, and what we do with RavenDB, is to have a pool of threads that all manage multiple connections at the same time, often interleaving execution of different connections using async/await on the same thread for better performance.







 Occasionally, one of our tests hangs. Everything seems to be honky dory, but it just freezes and does not complete. This is a new piece of code, and thus is it suspicious unless proven otherwise, but an exhaustive review of it looked fine. It took over two days of effort to narrow it down, but eventually we managed to point the finger directly at this line of code:
Occasionally, one of our tests hangs. Everything seems to be honky dory, but it just freezes and does not complete. This is a new piece of code, and thus is it suspicious unless proven otherwise, but an exhaustive review of it looked fine. It took over two days of effort to narrow it down, but eventually we managed to point the finger directly at this line of code:

