




time to read 1 min | 19 words
The first part of a two parts article about NHibernate and Rhino Service bus in now on MSDN.

The first part of a two parts article about NHibernate and Rhino Service bus in now on MSDN.
A long time ago, I needed to implement a security subsystem for an application. I figured that it was best to make the entire security subsystem transparent to the developer, under the assumption that if the infrastructure would take care of security, it would make a lot more sense than relying on the developer to remember to add the security calls.
It took me a long while to realize how wrong that decision was. Security is certainly important, but security doesn’t apply to the system itself. In other words, while a specific user may not be allowed to read/write to the audit log, actions that the user made should be written to that log. That is probably the simplest case, but that are a lot of similar ones.
Ever since then, I favored using an explicit approach:
var books = session.CreateQuery("from Books")
.ThatUserIsAllowedToRead(CurrentUser)
.List<Book>();
This also help you implement more interesting features, such as “on behalf of”. And yes, it does put the onus of security on the developer, but considering the alternative, that is a plus.
The following code contains a bug that would only occur under rare situations, can you figure out what is the bug?

Note: I am not feeling very well for the past week or so, which is why I am posting so rarely.
NHibernate is meant to be used in an OLTP system, as such, it is usually used in cases where we want to load a relatively small amount of data from the database, work with it and save it back. For reporting scenarios, there are better alternatives, usually (and before you ask, any reporting package will do. Right tool for the job, etc).
But there are cases where you want to do use NHibernate in reporting scenarios nonetheless. Maybe because the reporting requirements aren’t enough to justify going to a separate tool, or because you want to use what you already know. It is in those cases where you tend to run into problems, because you violate the assumptions that were made while building NHibernate.
Let us imagine the following use case, we want to print a list of book names to the user:
using (ISession s = OpenSession()) { var books = s.CreateQuery("from Book") .List<Book>(); foreach (var book in books) { Console.WriteLine(book.Name); } }
There are several problems here:
What I would like to see is something like this:
while(dataReader.Read()) { Console.WriteLine(dataReader.GetString("Name")); }
This still suffer from the problem of reading a large result set, but we will consider this a part of our requirements, so we’ll just have to live with it. The data reader code has two major advantages, it uses very little memory, and we can start processing the data as soon as the first row loads from the database.
How can we replicate that with NHibernate?
Well, as usual with NHibernate, it is only a matter of finding the right extension point. In this case, the List method on the query also has an overload that accepts an IList parameter:

That make it as simple as implementing our own IList implementation:
public class ActionableList<T> : IList { private Action<T> action; public ActionableList(Action<T> action) { this.action = action; } public int Add(object value) { action((T)value); return -1; } public bool Contains(object value) { throw new NotImplementedException(); } // ... }
And now we can call it:
using (ISession s = OpenSession()) { var books = new ActionableList<Book>(book => Console.WriteLine(book.Name)); s.CreateQuery("from Book") .List(books); }
This will have the exact same effect as the pervious NHibernate code, but it will start printing the results as soon as the first result loads from the database. We still have the problem of memory consumption, though. The session will keep track of all the loaded objects, and if we load a lot of data, it will eventually blow out with an out of memory exception.
Luckily, NHibernate has a ready made solution for this, the stateless session. The code now looks like this:
using (IStatelessSession s = sessionFactory.OpenStatelessSession()) { var books = new ActionableList<Book>(book => Console.WriteLine(book.Name)); s.CreateQuery("from Book") .List(books); }
The stateless session, unlike the normal NHibernate session, doesn’t keep track of loaded objects, so the code here and the data reader code are essentially the same thing.
Can you figure out a way to write the following code without using a try/catch?
class Program { static void Main(string[] args) { dynamic e = new ExpandoObject(); e.Name = "Ayende"; Console.WriteLine(HasProperty("Name", e)); Console.WriteLine(HasProperty("Id", e)); } private static bool HasProperty(string name, IDynamicMetaObjectProvider dyn) { try { var callSite = CallSite<Func<CallSite, object, object>>.Create( Binder.GetMember(CSharpBinderFlags.None, name, typeof (Program), new[] { CSharpArgumentInfo.Create( CSharpArgumentInfoFlags.None, null) })); callSite.Target(callSite, dyn); return true; } catch (RuntimeBinderException) { return false; } } }
The HasProperty method should accept any IDynamicMetaObjectProvider implementation, not just ExpandoObject.
The question pops up frequently enough and is interesting enough for a post. How do you store a data structure like this in Raven?
The problem here is that we don’t have enough information about the problem to actually give an answer. That is because when we think of how we should model the data, we also need to consider how it is going to be accessed. In more precise terms, we need to define what is the aggregate root of the data in question.
Let us take the following two examples:


As you can imagine, a Person is an aggregate root. It can stand on its own. I would typically store a Person in Raven using one of two approaches:
| Bare references | Denormalized References |
{
"Name": "Ayende",
"Email": "Ayende@ayende.com",
"Parent": "people/18",
"Children": [
"people/59",
"people/29"
]
}
|
{
"Name": "Ayende",
"Email": "Ayende@ayende.com",
"Parent": { "Name": "Oren", "Id": "people/18"},
"Children": [
{ "Name": "Raven", "Id": "people/59"},
{ "Name": "Rhino", "Id": "people/29"}
]
}
|
The first option is bare references, just holding the id of the associated document. This is useful if I only need to reference the data very rarely. If, however, (as is common), I need to also show some data from the associated documents, it is generally better to use denormalized references, which keep the data that we need to deal with from the associated document embedded inside the aggregate.
But the same approach wouldn’t work for Questions. In the Question model, we have utilized the same data structure to hold both the question and the answer. This sort of double utilization is pretty common, unfortunately. For example, you can see it being used in StackOverflow, where both Questions & Answers are stored as posts.
The problem from a design perspective is that in this case a Question is not a root aggregate in the same sense that a Person is. A Question is a root aggregate if it is an actual question, not if it is a Question instance that holds the answer to another question. I would model this using:
{
"Content": "How to model relations in RavenDB?",
"User": "users/1738",
"Answers" : [
{"Content": "You can use.. ", "User": "users/92" },
{"Content": "Or you might...", "User": "users/94" },
]
}
In this case, we are embedding the children directly inside the root document.
So I am afraid that the answer to that question is: it depends.
This is just some rambling about the way the economy works, it has nothing to do with tech or programming. I just had to sit down recently and do the math, and I am pretty annoyed by it.
The best description of how the economy works that I ever heard was in a Terry Prachett’s book, it is called Captain Vimes’ Boots’ Theory of Money. Stated simply, it goes like this.
A good pair of boots costs 50$, and they last for 10 years and keep your feet warm. A bad pair of boots costs 10$ and last only a year or two. After 10 years, the poor boots cost twice as much as the good boots, and your feet are still cold!
The sad part about that is that this theory is quite true. Let me outline two real world examples (from Israel, numbers are in Shekels).
Buying a car is expensive, so a lot of people opts for a leasing option. Here are the numbers associated with this (real world numbers):
| Buying car outright | Leasing | |
| Upfront payment | 120,000 | 42,094.31 |
| Monthly payment (36 payments) | 0 | 1,435.32 |
| Buying the car (after 3 yrs) [optional] | 0 | 52,039.67 |
The nice part of going with a leasing contract is that you need so much less upfront money, and the payments are pretty low. The problem starts when you try to compare costs on more than just how much money you are paying out of pocket. We only have to spent a third.
Let us see what is going to happen in three years time, when we wan to switch to a new car.
| Buying car outright | Leasing | |
| Upfront payment | 120,000.00 | 42,094.31 |
| Total payments | 0.00 | 51,671.52 |
| Selling the car | -80,000.00 | 0.00 |
| Total cost | 40,000.00 | 93,765.83 |
With the upfront payment, we can actually sell the car to recoup some of our initial investment. With the leasing option, at the end of the three years, you are out 93,765.83 and have nothing to show for it.
Total cost of ownership for the leasing option is over twice as much as the upfront payment option.
Buying an apartment is usually one of the biggest expenses that most people do in their life. The cost of an apartment/house in Israel is typically over a decade of a person’ salary. Israel’s real estate is in a funky state at the moment, being one of the only places in the world where the prices keep going up. Here are some real numbers:
It isn’t surprising that most people requires a mortgage to buy a place to live.
Let us say that we are talking about a 1,000,000 price, just to make the math simpler, and that we have 400,000 available for the down payment. Let us further say that we got a good interest rate of the 600,000 mortgage of 2% (if you take more than 60% of the money you are penalized with higher interest rate in Israel).
Assuming fixed interest rate and no inflation, you will need to pay 3,035 for 20 years. But a 2% interest rate looks pretty good, right? It sounds pretty low.
Except over 20 years, you’ll actually pay: 728,400 back on your 600,000 loan, which means that the bank get 128,400 more than it gave you.
The bank gets back 21.4% more money. With a more realistic 3% interest rate, you’ll pay back 33% more over the lifetime of the loan. And that is ignoring inflation. Assume (pretty low) 2% per year, you would pay 49% more to the bank in 2% interest rate and 65% more in 3% interest rate.
Just for the fun factor, let us say that you rent, instead. And assume further that you rent for the same price of the monthly mortgage payment. We get:
| Mortgage | Rent | |
| Upfront payment | 400,000.00 | 0.00 |
| Monthly payment | 3,000.00 | 3,000.00 |
| Total payments (20 years) | 720,000.00 | 720,000.00 |
| Total money out | 1,120,000.00 | 720,000.00 |
| House value | 1,000,000.00 | 0.00 |
| Total cost | 120,000.00 | 720,000.00 |
After 20 years, renting cost 720,000. Buying a house costs 120,000. And yes, I am ignoring a lot of factors here, that is intentional. This isn’t a buy vs. rent column, it is a cost of money post.
But after spending all this time doing the numbers, it all comes back to Vimes’ Boots theory of money.
In general, when you break it down to the fundamentals, a data base is just a fancy linked list + some btrees. Yes, I am ignoring a lot, but if you push aside a lot of the abstraction, that is what is actually going on.
If you ever dealt with database optimizations you are familiar with query plans, like the following (from NHProf):
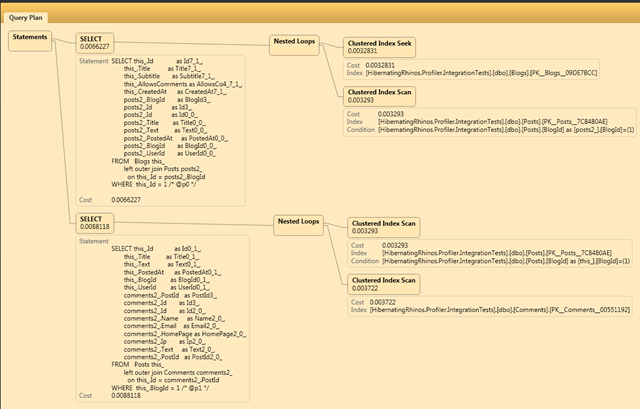
You can see that we have some interesting stuff going on here:
And if you are unlucky, you are probably familiar with the dreaded “your !@&!@ query is causing a table scan!” scream from the DBA. But most of the time, people just know that table scan is slow, index scan is fast and index seek is fastest. I am ignoring things like clustered vs. unclustered indexes, since they aren’t really important for what I want to do.
For simplicity sake, I’ll use the following in memory data structure:
public class DocumentDatabase { public List<JObject> Documents = new ...; public IDictionary<string, IDictionary<JToken, JObject>> Indexes = new ...; }
To keep things simple, we will only bother with the case of exact matching. For example, I might store the following document:
{ "User": "ayende", "Name": "Ayende Rahien", "Email": "Ayende@ayende.com" }
And define an index on Name & Email. What would happen if I wanted to make a query by the user name?
Well, we don’t really have any other option, we have to do what amounts to a full table scan:
foreach (var doc in Documents) { if(doc.User == "ayende") yield return doc; }
As you can imagine, this is an O(N) operation, which can get pretty expensive if we are querying a large table.
What happen if I want to find data by name & email? We have an index that is perfectly suited for that, so we might as well use it:
Indexes["NameAndEmail"][new{Name="Ayende Rahien", Email = “Ayende@ayende.com”}];
Note that what we are doing here is accessing the NameAndEmail index, and then making a query on that. This is essentially an index seek.
What happens if I want to query just by email? There isn’t an index just for emails, but we do have an index that contains emails. We have two options, use a table scan, or and index scan. We already saw what a table scan is, so let us look at what is an index scan:
var nameAndEmailIndex = Indexes["NameAndEmail"]; foreach (var indexed in nameAndEmailIndex) { if(indexed.Email == "ayende@ayende.com") yield return indexed; }
All in all, it is very similar to the table scan, and when using in memory data structures, it is probably not worth doing index scans (at least, not if the index is over the entire data set).
Where index scans prove to be very useful is when we are talking about persistent data sets, where reading the data from the index may be more efficient than reading it from the table. That is usually because the index is much smaller than the actual table. In certain databases, the format of the data on the disk may make it as efficient to do a table scan in some situations as it to do an index scan.
Another thing to note is that while I am using hashes to demonstrate the principal, in practice, most persistent data stores are going to use some variant of trees.
I run into an interestingly annoying problem recently. Basically, I am trying to write the following code:
tree.Add(new { One = 1, Two = 2 }, 13);
tree.Add(new { One = 2, Two = 3 }, 14); tree.Add(new { One = 3, Two = 1 }, 15); var docPos = tree.Find(new { One = 1, Two = 2 }); Assert.Equal(13, docPos); docPos = tree.Find(new { Two = 2 }); Assert.Equal(13, docPos); docPos = tree.Find(new { Two = 1 }); Assert.Equal(14, docPos);
As you can imagine, this is part of an indexing approach, the details of which aren’t really important. What is important is that I am trying to figure out how to support partial searches. In the example, we index by One & Two, and we can search on both of them. The problem begins when we want to make a search on just Two.
While the tree can compare between partial results just fine, the problem is how to avoid traversing the entire tree for a partial result. The BTree is structured like this:

The problem when doing a partial search is that at the root, I have no idea if I should turn right or left.
What I am thinking now is that since I can’t do a binary search, I’ll have to use a BTree+ instead. Since BTree+ also have the property that the leaf nodes are a linked list, it means that I can scan it effectively. I am hoping for a better option, though.
Any ideas?
One of the interesting aspects in building a data store is that you run head on into things that you would generally leave to the infrastructure. By far, most developers deal with concurrency by relegating that responsibility to a database.
When you write your own database, you have to build this sort of thing. In essence, we have two separate issues here:
As I mentioned in my previous post, there are two major options when building a data store, Transaction Log & Append Only. There are probably a better name for each, but that is how I know them.
This post is going to focus on append only. An append only store is very simple idea in both concept and implementation. It requires that you will always append to the file. It makes things a bit finicky with the type of data structures that you have to use, since typical persistent data structures rely on being able to modify data on the disk. But once you get over that issue, it is actually very simple.
An append only store works in the following manner:
The last one is a natural fallout from the fact that we use the append only model. Only one thread can write to the end of the file at a given point in time. That is actually a performance boost, and not something that would slow the database down, as you might expect.
The reason for that is pretty obvious, once you start thinking about it. Writing to disk is a physical action, and the head can be only in a single place at any given point in time. By ensuring that all writes go to the end of the file, we gain a big perf advantage since we don’t do any seeks.
No future posts left, oh my!