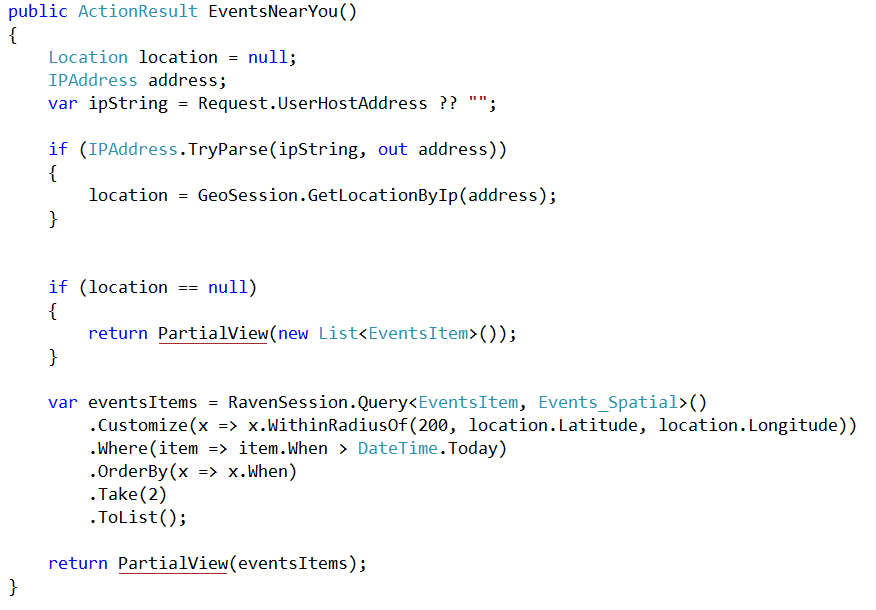
I got word about a port of Nerd Dinner to RavenDB, Dinner Party (source, live demo), and I just had to check the code.
I reviewed Nerd Dinner itself in the past: Part I, Part II, so it is extra fun to see what happens when you move this to RavenDB. Note that at this point, I haven’t even looked at the code yet.
Here is the actual project (Just one project, I wholeheartedly approve):

Hm… where is the controllers folder?
Oh, wait, this isn’t an ASP.NET MVC application, it is a NancyFX application. I never actually look into that, so this should be interesting. Let us see if I can find something interesting, and I think we should look at the bootstrapper first.
There are several interesting things happening here. First, the application uses something called TinyIoC, which I am again, not familiar with. But it seems reasonable, and here is how it is initialized:
protected override void ApplicationStartup(TinyIoC.TinyIoCContainer container, Nancy.Bootstrapper.IPipelines pipelines)
{
base.ApplicationStartup(container, pipelines);
DataAnnotationsValidator.RegisterAdapter(typeof(MatchAttribute), (v, d) => new CustomDataAdapter((MatchAttribute)v));
Func<TinyIoCContainer, NamedParameterOverloads, IDocumentSession> factory = (ioccontainer, namedparams) => { return new RavenSessionProvider().GetSession(); };
container.Register<IDocumentSession>(factory);
CleanUpDB(container.Resolve<IDocumentSession>());
Raven.Client.Indexes.IndexCreation.CreateIndexes(typeof(IndexEventDate).Assembly, RavenSessionProvider.DocumentStore);
Raven.Client.Indexes.IndexCreation.CreateIndexes(typeof(IndexUserLogin).Assembly, RavenSessionProvider.DocumentStore);
Raven.Client.Indexes.IndexCreation.CreateIndexes(typeof(IndexMostPopularDinners).Assembly, RavenSessionProvider.DocumentStore);
Raven.Client.Indexes.IndexCreation.CreateIndexes(typeof(IndexMyDinners).Assembly, RavenSessionProvider.DocumentStore);
pipelines.OnError += (context, exception) =>
{
Elmah.ErrorSignal.FromCurrentContext().Raise(exception);
return null;
};
}
All of which looks fine to me, except that I seriously don’t like the injection of the session. Why?
Because it means that if you have two components in the same request that needs a session, each will get his own session, instead of having a session per request. It also means that you can’t implement the “call SaveChanges() when the request is done without error” pattern, but that is more of a pet peeve than anything else.
Another thing to note is the multiple calls to IndexCreation.CreateIndexes. Remember, we have just one assembly here, and CreateIndexes operate on the assembly level, not on the individual index level. All of those can be removed but one (and it doesn’t matter which).
Lastly, we have the CleanupDB part. Dinner Party runs on Azure, and make use of RavenHQ. In order to stay within the limit of the RavenHQ free database, Dinner Party will do cleanups and delete old events if the db size goes over some threshold.
Okay, let us see where the real stuff is happening, and it seems to be happening in the Modules directory. I checked the HomeModule first, and I got:
public class HomeModule : BaseModule
{
public HomeModule()
{
Get["/"] = parameters =>
{
base.Page.Title = "Home";
return View["Index", base.Model];
};
Get["/about"] = parameters =>
{
base.Page.Title = "About";
return View["About", base.Model];
};
}
}
I was worried at first about Page.Title (reminded me of ASPX pages), but it is just a default model that is defined in BaseModule. It is actually quite neat, if you think about it, check it out:
Before += ctx =>
{
Page = new PageModel()
{
IsAuthenticated = ctx.CurrentUser != null,
PreFixTitle = "Dinner Party - ",
CurrentUser = ctx.CurrentUser != null ? ctx.CurrentUser.UserName : "",
Errors = new List<ErrorModel>()
};
Model.Page = Page;
return null;
};
I assume that Model is shared between Module and View, but I will check it shortly. I like how you can expose it to the view dynamically and have a strongly typed version in your code.
And yes, confirmed, the views are just Razor code, and they look like this:

Okay, enough with playing around, I’ll need to investigate NancyFX more deeply later on (especially since it can do self hosting), but right now, let us see how this is using RavenDB.
Let us start with the DinnerModule, a small snippet of it can be found here (this is from the ctor):
const string basePath = "/dinners";
Get[basePath + Route.AnyIntOptional("page")] = parameters =>
{
base.Page.Title = "Upcoming Nerd Dinners";
IQueryable<Dinner> dinners = null;
//Searching?
if (this.Request.Query.q.HasValue)
{
string query = this.Request.Query.q;
dinners = DocumentSession.Query<Dinner>().Where(d => d.Title.Contains(query)
|| d.Description.Contains(query)
|| d.HostedBy.Contains(query)).OrderBy(d => d.EventDate);
}
else
{
dinners = DocumentSession.Query<Dinner, IndexEventDate>().Where(d => d.EventDate > DateTime.Now.Date)
.OrderBy(x => x.EventDate);
}
int pageIndex = parameters.page.HasValue && !String.IsNullOrWhiteSpace(parameters.page) ? parameters.page : 1;
base.Model.Dinners = dinners.ToPagedList(pageIndex, PageSize);
return View["Dinners/Index", base.Model];
};
I am not sure that I really like this when you effectively have methods within methods, and many non trivial ones.
The code itself seems to be pretty nice, and I like the fact that it makes use of dynamic in many cases to make things easier (for Query or to get the page parameter).
But where does DocumentSession comes from? Well, it comes from PersistentModule, the base class for DinnerModule, let us take a look at that:
public class PersistModule : BaseModule
{
public IDocumentSession DocumentSession
{
get { return Context.Items["RavenSession"] as IDocumentSession; }
}
public PersistModule()
{
}
public PersistModule(string modulepath)
: base(modulepath)
{
}
}
And now I am confused, so we do have session per request here? It appears that we do, there is a RavenAwareModuleBuilder, which has the following code:
if (module is DinnerParty.Modules.PersistModule)
{
context.Items.Add("RavenSession", _ravenSessionProvider.GetSession());
//module.After.AddItemToStartOfPipeline(ctx =>
//{
// var session =
// ctx.Items["RavenSession"] as IDocumentSession;
// session.SaveChanges();
// session.Dispose();
//});
}
I withdraw my earlier objection. Although note that the code had at one point automatic session SaveChanges(), and now it no longer does.
Another common pet issue in the code base, there is a lot of code that is commented.
Okay, so now I have a pretty good idea how this works, let us see how they handle writes, in the Dinner case, we have another class, called DinnerModuleAuth, which is used to handle all writes.
Here is how it looks like (I chose the simplest, mind):
Post["/delete/" + Route.AnyIntAtLeastOnce("id")] = parameters =>
{
Dinner dinner = DocumentSession.Load<Dinner>((int)parameters.id);
if (dinner == null)
{
base.Page.Title = "Nerd Dinner Not Found";
return View["NotFound", base.Model];
}
if (!dinner.IsHostedBy(this.Context.CurrentUser.UserName))
{
base.Page.Title = "You Don't Own This Dinner";
return View["InvalidOwner", base.Model];
}
DocumentSession.Delete(dinner);
DocumentSession.SaveChanges();
base.Page.Title = "Deleted";
return View["Deleted", base.Model];
};
My only critique is that I don’t understand why we would need to explicitly call SaveChanges instead.
Finally, a bit of a critique on the RavenDB usage, the application currently uses several static indexes: IndexEventDate, IndexMostPopularDinners, IndexMyDinners and IndexUserLogin.
The first three can be merged without any ill effects, I would create this, instead:
public class Dinners_Index : AbstractIndexCreationTask<Dinner>
{
public Dinners_Index()
{
this.Map = dinners =>
from dinner in dinners
select new
{
RSVPs_AttendeeName = dinner.RSVPs.Select(x => x.AttendeeName),
RSVPs_AttendeeNameId = dinner.RSVPs.Select(x => x.AttendeeNameId),
HostedById = dinner.HostedById,
HostedBy = dinner.HostedBy,
DinnerID = int.Parse(dinner.Id.Substring(dinner.Id.LastIndexOf("/") + 1)),
Title = dinner.Title,
Latitude = dinner.Latitude,
Longitude = dinner.Longitude,
Description = dinner.Description,
EventDate = dinner.EventDate,
RSVPCount = dinner.RSVPs.Count,
};
}
}
This serve the same exact function, but it only has one index. In general, we prefer to have bigger and fewer indexes than smaller and more numerous indexes.