I talked with my daughter recently about an old babysitter, and then I pulled out my phone and searched for a picture using “Hadera, beach”. I could then show my daughter a picture of her and the babysitter at the beach from about a decade ago.
I have been working in the realm of databases and search for literally decades now. The image I showed my daughter was taken while I was taking some time off from thinking about what ended up being Corax, RavenDB’s indexing and querying engine 🙂.
It feels natural as a user to be able to search the content of images, but as a developer who is intimately familiar with how this works? That is just a big mountain of black magic. Except… I do know how to make it work. It isn’t black magic, it's just the natural consequence of a bunch of different things coming together.
TLDR: you can see the sample application here: https://github.com/ayende/samples.imgs-embeddings
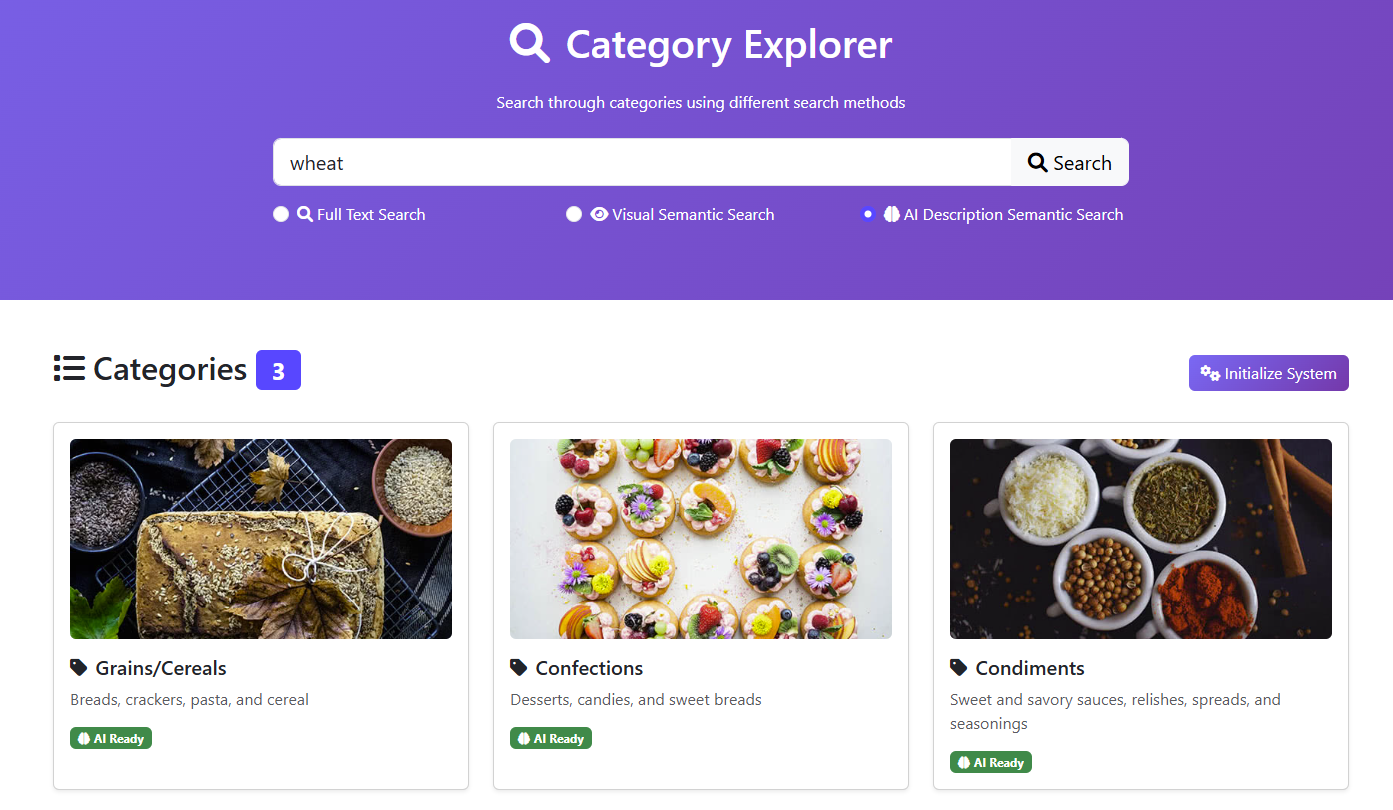
And here is what the application itself looks like:
Let’s talk for a bit about how that actually works, shall we? To be able to search the content of an image, we first need to understand it. That requires a model capable of visual reasoning.
If you are a fan of the old classics, you may recall this XKCD comic from about a decade ago. Luckily, we don’t need a full research team and five years to do that. We can do it with off-the-shelf models.
A small reminder - semantic search is based on the notion of embeddings, a vector that the model returns from a piece of data, which can then be compared to other vectors from the same model to find how close together two pieces of data are in the eyes of the model.
For image search, that means we need to be able to deal with a pretty challenging task. We need a model that can accept both images and text as input, and generate embeddings for both in the same vector space.
There are dedicated models for doing just that, called CLIP models (further reading). Unfortunately, they seem to be far less popular than normal embedding models, probably because they are harder to train and more expensive to run. You can run it locally or via the cloud using Cohere, for example.
Here is an example of the codeyou need to generate an embedding from an image. And here you have the code for generating an embedding from text using the same model. The beauty here is that because they are using the same vector space, you can then simply apply both of them together using RavenDB’s vector search.
Here is the code to use a CLIP model to perform textual search on images using RavenDB:
// For visual search, we use the same vector search but with more candidates
// to find visually similar categories based on image embeddings
var embedding = await _clipEmbeddingCohere.GetTextEmbeddingAsync(query);
var categories = await session.Query<CategoriesIdx.Result, CategoriesIdx>()
.VectorSearch(x => x.WithField(c => c.Embedding),
x => x.ByEmbedding(embedding),
numberOfCandidates: 3)
.OfType<Category>()
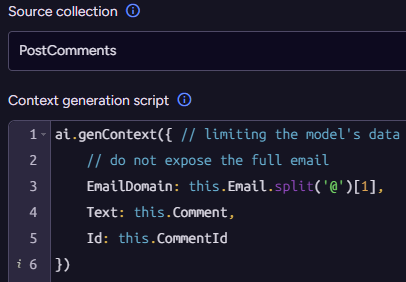
.ToListAsync();Another option, and one that I consider a far better one, is to not generate embeddings directly from the image. Instead, you can ask the model to describe the image as text, and then run semantic search on the image description.
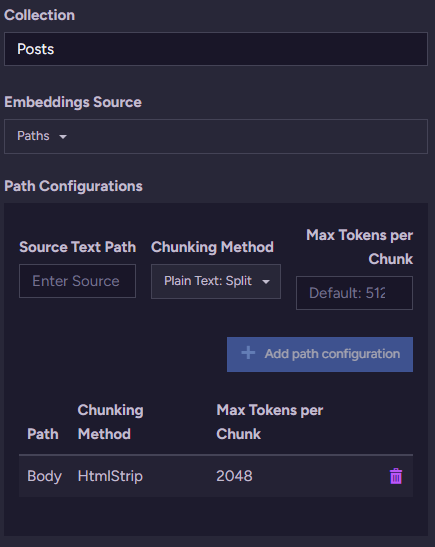
Here is a simple example of asking Ollama to generate a description for an image using the llava:13b visual model. Once we have that description, we can ask RavenDB to generate an embedding for it (using the Embedding Generation integration) and allow semantic searches from users’ queries using normal text embedding methods.
Here is the code to do so:
var categories = await session.Query<Category>()
.VectorSearch(
field => {
field.WithText(c => c.ImageDescription)
.UsingTask("categories-image-description");
},
v => v.ByText(query),
numberOfCandidates: 3)
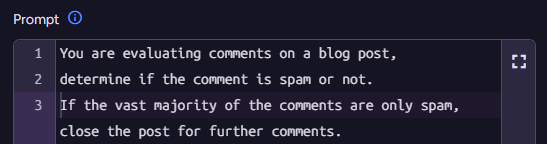
.ToListAsync();We send the user’s query to RavenDB, and the AI Task categories-image-description handles how everything works under the covers.
In both cases, by the way, you are going to get a pretty magical result, as you can see in the top image of this post. You have the ability to search over the content of images and can quite easily implement features that, a very short time ago, would have been simply impossible.
You can look at the full sample application here, and as usual, I would love your feedback.