





TLDR: Check out the new Cluster Debug View announcement
If you had asked me twenty years ago what is hard about building a database, I would have told you that it is how to persist and retrieve data efficiently. Then I actually built RavenDB, which is not only a database, but a distributed database, and I changed my mind.
The hardest thing about building a distributed database is the distribution aspect. RavenDB actually has two separate tiers of distribution: the cluster is managed by the Raft algorithm, and the databases can choose to use a gossip algorithm (based on vector clocks) for maximum availability or Raft for maximum consistency.
The reason distributed systems are hard to build is that they are hard to reason about, especially in the myriad of ways that they can subtly fail. Here is an example of one such problem, completely obvious in retrospect once you understand what conditions will trigger it. And it lay hidden there for literally years, with no one being the wiser.
Because distributed systems are complex, distributed debugging is crazy complex. To manage that complexity, we spent a lot of time trying to make it easier to understand. Today I want to show you the Cluster Debug page.
You can see one such production system here, showing a healthy cluster at work:
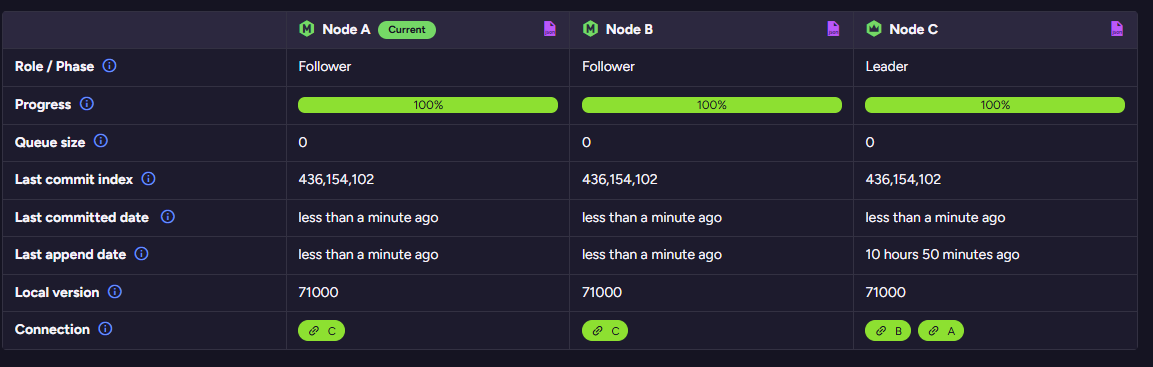
You can also inspect the actual Raft log to see what the cluster is actually doing:
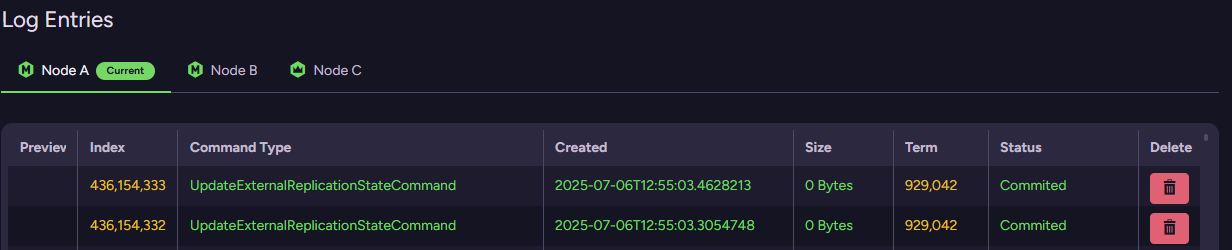
This is the sort of feature that you will hopefully never have an opportunity to use, but when it is required, it can be a lifesaver to understand exactly what is going on.
Beyond debugging, it is also an amazing tool for us to explore and understand how the distributed aspects of RavenDB actually work, especially when we need to explain that to people who aren’t already familiar with it.
You can read the full announcement here.