





 5 years ago, we introduced bulk insert support to RavenDB. The idea was to let users to have a good way to insert data into RavenDB as fast as possible. In order to do that, we created special code paths that were super optimized for loading large amount of data into the database as fast as possible.
5 years ago, we introduced bulk insert support to RavenDB. The idea was to let users to have a good way to insert data into RavenDB as fast as possible. In order to do that, we created special code paths that were super optimized for loading large amount of data into the database as fast as possible.
Basically, we bypassed a lot of the stuff along the way, put some constraint on the user when calling this and smoothed everything we could. Internally, this was implemented using a pretty complex system which split work among multiple threads to handle serializing, sending over the network, parsing and writing to disk.
When we start working on 4.0, one of the very first things we did was to build bulk insert from scratch. We built it on top of TCP, instead of HTTP, and we decided that for the sake of performance, we can throw pretty much anything at this problem. The overall design looked something like this:
- One thread at the client side, getting entities and serializing them to our blittable binary format.
- One thread at the client side for sending the data over the network.
In order to save memory, those two threads have a common buffer pool that they reuse all the time.
- On the server side, we have a dedicated thread reading from the network, constructing our blittable instances and validating their format and putting them in a queue.
- On the server side, we have a dedicated thread pooling from the queue and batching requests, then saving them in a single transaction.
Like the client, we are saving memory by having a common shared buffer pool.
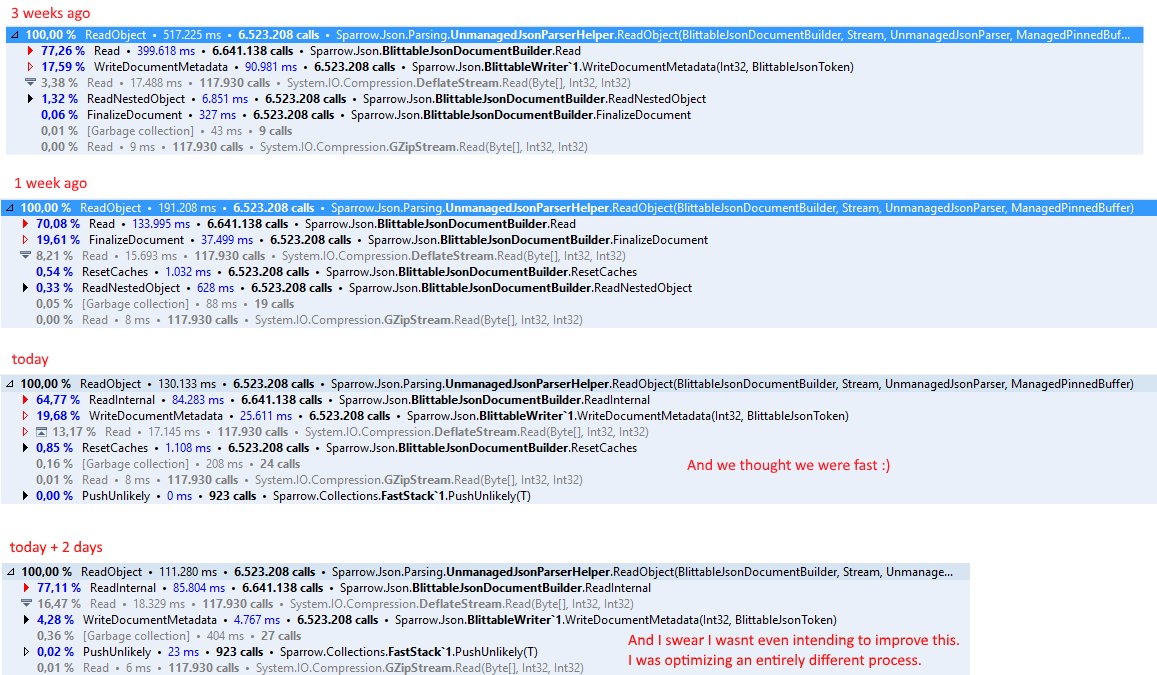
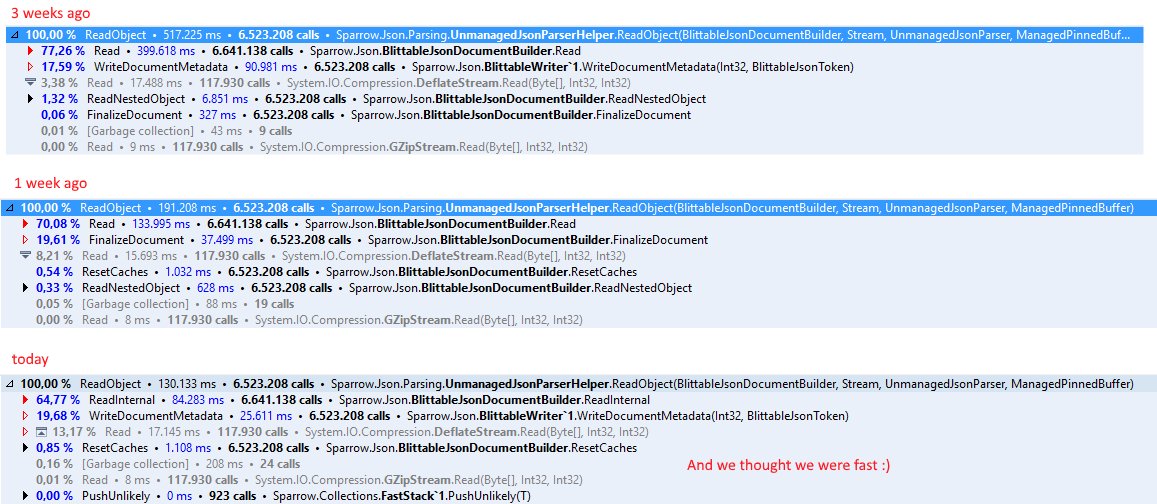
Initially, having a dedicated code path for bulk insert was awesome, because we could get really high performance from it. But it also introduced problems. Consider the scenario above, the server thread reading from the network is reading as fast as it can, and send the data to the queue. If the consuming thread isn’t fast enough (for example, we just hit an I/O bump), we might start accumulating stuff in the queue, and if this goes for long enough, we might run out of usable memory.
We had to implement our own backpressure and congestion control because of that, and that led to more interesting issues. Because we were starting to read very quickly, and only run into the I/O problem later, we had incidents in which we weren’t fast enough with the “let me catch my breath” notification and overloaded the TCP connection, resulting in timeouts on the client. This sounds all very complicated, and it was, but we managed to solve all of those issues and this piece of code had very few changes for a long time.
And this week we deleted all of it in favor of a radically different implementation. Basically, the new implementation will just open a standard HTTP request and write JSON strings to the network. This is about as simple an implementation as we can get. And we delete all this high performance, extremely tuned and carefully crafted code.
Why?
You might have noticed that we are putting a major emphasis on performance, so why would we throw all that code away?
There are several reasons:
- Back pressure, congestions control and other fun factors are not things that we want to deal with, instead, we want to deal with them at the network layer, where there is a lot more information about it.
- Complex code is costly, and it requires us to modify other pieces of code to ensure that this still works.
- We used to getting impressive numbers from this special casing, but we are seeing similar numbers without all the hoopla.
The trigger for this was a set of optimization we did for optimizing standard write patterns. Your usual OLTP workload, basically. As we made that faster & faster, we started to think whatever it made sense to allow the bulk insert code to still remain a special snowflake. For example, the bulk insert code didn’t use our transaction merging capabilities, instead, it would directly talk to the storage. But that meant that it lost out on a lot of the benefits we made to the transaction merging code. It would also cause bulk inserts to fight concurrent write loads (including other bulk inserts), instead of cooperating.
The decision to go with TCP connection directly was made because we wanted absolute performance & control, but we have taken too much upon ourselves, and we were concerned about firewall issues. Forcing admins to open another port can be tricky, and we want to reduce the cost of deploying RavenDB instances as much as possible.
Finally, we needed something that was a lot more approachable. While using our own binary format over the wire meant that we could do a lot less work, it also put a major stumbling block if you wanted to do bulk insert via anything but our .NET code. If we wanted to do bulk insert from node.js, that would require… non trivial amount of effort, to say the least.
The new wire format looks like this:
This is trivial to integrate with regardless of platform. The reason we use this particular format? This is actually identical to the format we use for SaveChanges, and that piece of code has been through multiple optimization rounds. Here is a small example from that code path:
This is pretty fast (and gnarly) code, so we get to reuse that and benefit from any future optimizations.
The major difference here is that this is a a streaming format, that is, we are going to read from the stream and process this immediately. With SaveChanges, we have to read the whole thing to memory, and apply it as a single transaction. In the case of our new bulk insert code, we’re not going to do the whole thing as a single transaction, but a series of them, based on the actual workload.
The fun thing here is that we can dramatically reduce the overall complexity while maintaining a lot of the desired behavior. In fact, the entire bulk insert implementation is under 50 lines of code now. Small enough that I can just include it in this post in its entirety.
Note that this code rely on a lot of other code, but none of this other code is Bulk Insert specific. There are a few interesting bits here that are worth exploring.
BatchRequestParser.ReadMany allow us to stream read the data, it read each individual command and return it. The code in line 17 ( var task = await parser.MoveNext() ) is pretty strange. MoveNext is returning a Task<Task>. The idea is that we are going to read a command from the network and parse it immediately. However, if there isn’t a full command already buffered, we’ll return an async task for completing it. (The Task<Task> is here because we might need to wait for the initial command, or for the final ] of the array. We’ll probably optimize that once we are done with all the taxes on this feature, to avoid the Task allocation.).
The basic idea is that we’ll read & parse from the network as long as there is information available, and when we start waiting for the network, we’ll go into the if statement and send it to the transaction merger. That gives us three very important properties.
- We parallelize the work, while we are waiting for the next document to arrive over the network, we are concurrently writing the current batch to disk. Note that we don’t have any such things as batch size defined. This is all controlled by the network speed. We do have the 16 MB limitation, to prevent a really fast network from causing excess memory utilization on the server side.
- We are only buffering a relatively small amount of data (by default, however much the network can give us without waiting), so we get pretty consistent read experience. “Read a buffered document” –> “Write to disk”. This has the effect of being able to teach the connection how fast we can read & process the results, giving us much better behavior as far as the network stack is concerned.
- We play well with the rest of the system. By utilizing the transaction merger, we’ll work well with concurrent work on the server, instead of fighting for the same resources.
The code still need some work (resource handling, better error management, etc), but it is a new win in terms of simplicity and manageability.
But what about performance? Previously we have spread the load across many threads, on both client & server ends. That gave us faster overall performance at the cost of much higher complexity.
As it turns out, quite a lot of the benefit of bulk insert is related to the fact that we have just a single network connection going on, and we have that. We get some parallelism between writing the documents and reading from the network, but that is intentionally limited (to avoid fooling the other side that we can keep up with that rate of reads if we have an I/O stall).
But let us assume that you have really need to be able to insert a lot of data into the database? Fast enough and large enough that you want us to be even faster?
That is actually quite easy. Remember how many times I said that this new system play well with other operations? This is important, because if you want to have faster performance for bulk insert… just run parallel bulk inserts. This way, you’ll have multiple threads on the server side reading & parsing, and all of that work will go (together) to the transaction merger), giving us a much better overall performance.
In our benchmarks, we actually had issues with data generation on the client side causing a major slowdown. We had to pre-generate all the data upfront, and only then start the bulk insert process, otherwise the call to Random to generate the data would have enough of an impact on the overall benchmark test. I don’t think that you’ll be able to generate the data fast enough to saturate a single bulk insert connection easily, but given how easy concurrency has became, if you can, the scale up option is incredibly easy.






![image[10]](https://ayende.com/blog/Images/Open-Live-Writer/GoTo-based-optimizations_927A/image[10]_1.png "image[10]")


