





Why we aren’t publishing benchmarks for RavenDB 4.0 yet
You might have noticed something very strange in all my posts about performance work. I’m always talking about performance of either specific small pieces, or showing the difference between old and new code in percentages.
This is quite intentional, we are not ready yet to publish benchmark results. But the reason isn’t that we are too slow. Across the board, we are looking at a minimum of an order of magnitude improvement, and in many cases, several orders of magnitude improvements. The reason that we don’t publish benchmark it actually very simple, we aren’t done yet.
A few days ago I published some of the changes that we were doing around JSON parsing. As you can imagine for a JSON Document Database, JSON parsing is a crucial part of our workload, and any miniscule difference there can have a widespread impact on the whole system.
When we started with RavenDB 4.0, one of the first things we did was write our own unmanaged JSON parser. In Jan 2016, we run a benchmark that gave us a parsing cost of 170 μs per document parse using JSON.Net, while our code code parse it in 120 μs, giving us 40% benefit over JSON.NET. Those numbers actually lie, because JSON.Net also does managed allocations, while our parser don’t, giving us far reduced actual cost overall.
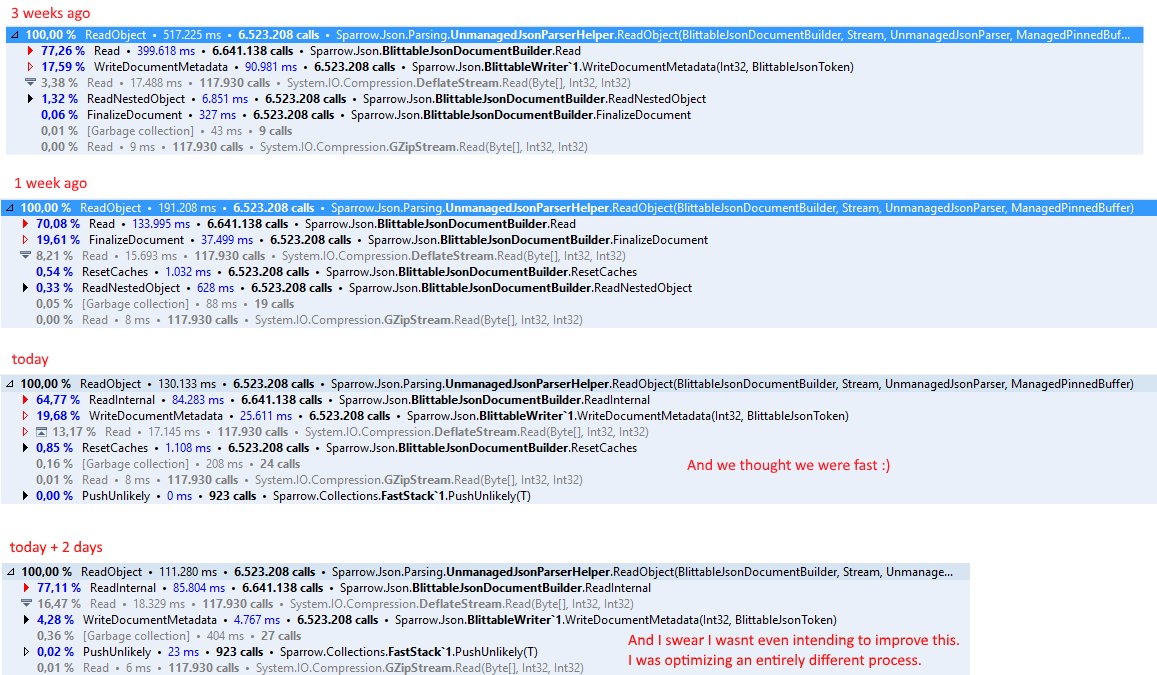
Getting 40% performance increase (and no future GC debt) is amazing, but in the year since, we have made a lot more changes. Here are some numbers from the performance team for the recent spate of work in that area. You can also see the details on the image on the right.
- T – 3 weeks (our current baseline, with a lot of performance work since Jan 2016): 80 μs per document, and this time, the documents are much bigger than the previous benchmark we run.
- T – 1 week: 30 μs per document.
- T: 20 μs per document.
And at that point, we were done, and moved on to optimize other parts.
- T + 2 days: 17 μs per document.
We weren’t even looking at that part, but optimizations in different areas meant that we were able to be even more efficient. That is about 17% higher.
And we still have about a month before we go into code freeze for the beta release.
Once that is done, we already have a plan to do a few round of benchmark / optimization / benchmark, and then publish the full results. I’m really excited about this.
Comments
I love your top top down approach for performance optimizations. It is something I've been advocating and doing since always.
What I mean, it was clearly visible process: At very high level you started with Voron and architectural changes in the pipeline, Then at mid level you started replacing components like the json parser, then at last at micro level, tight loop optimizations.
Even though I've followed all the blog posts closely, I'd love it if you could someday write a summary of the performance work done. It would become a reference article for sure.
Pop Catalin,
When we are done, I'm certainly going to do a full write up. Not sure if will fit into an article, we have done quite a lot of stuff there.
RavenDb is amazing. After getting into proper mindset and learning proper way of doing things, our workflow has improved and simplified enormously. Such dedication to details, simplicity and performance is inspiring. Thank you for great work. Cant wait for 4.0. Best Regards.
Zvjezdan,
Thanks!
Comment preview