About twenty years ago, I was working on what would eventually become RavenDB, and I needed an engine to handle queries. Writing a query engine from scratch is its own very large project, quite separate from writing a database engine. I made a decision that I still consider one of the smartest I made in those early days: I built on top of Lucene as my indexing and query engine.
That let me stand on a firm foundation while I dealt with the problems I actually cared about: building a NoSQL solution that didn't feel like juggling knives. Lucene gave me a mature, battle-tested way to index and query data, and I got to spend my time on the parts that made RavenDB RavenDB.
It was a good decision. But like a lot of good decisions, it came with a bill attached, and the bill arrived about a decade later.
Making use of features that are already there…
Here is a query that every developer has written a thousand times: give me the ten most recent posts on my blog. You write those sorts of queries in every kind of application you write, after all. And there is the natural follow-up: tell me the total number of posts, so I can render the pagination.
In most databases, you need to make two separate queries for this, and those two queries usually mean two separate database roundtrips. One to fetch the page, one to count the total.
In RavenDB, it's one query. You ask for the page, and you get the total count back in the same response.
This matters a lot more than you may initially think. In most systems, the cost of the network round-trip to the database dwarfs the cost of the query itself. The query runs in microseconds; the round-trip is the expensive part. So folding the count into the same response that carries the results eliminates an entire round-trip. When you run a paged query in RavenDB, you get the total number of matching results for free, and that is genuinely a wonderful feature.
The important word in that paragraph is free. I did not design this feature. I did not sit down and decide that paged queries should return a total count. Lucene already computed it, for reasons of its own, as a side effect of how it processes a query. I got it for nothing, exposed it through the API, and it became one of those small touches that made RavenDB pleasant to use and made your application run faster.
A free feature that adds real value, give me more of that!
Fifteen years later
Imagine a time skip of a decade and a half: we start building Corax, the next-generation query engine for RavenDB. Remember when I said that building a querying engine is a Big Project? I meant it.
It turns out that most databases do not give you the total result count for free for a very good reason: It isn't free. Consider the following queries and their internal representation in the database:
from Posts
where IsPublished = true
limit 10
from Posts
where IsPublished = true and PublishedAt <= $today
limit 10
from Posts
where IsPublished = true and PublishedAt <= $today and Tags in ($tags)
limit 10It is easy enough to check the number of posts that are published. A range query on a date field is more complex, especially if you have a lot of posts. Getting the total number of posts in a set of tags is more complex, since a post can have multiple tags and you need to deduplicate.
The intersection of three clauses, of course, is distinct from the count of each.
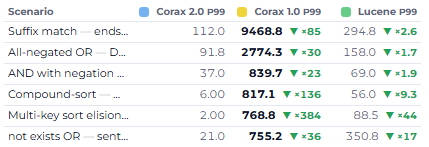
The queries above can stop further processing once they have 10 results, after all. But when you need an exact count for the query, you need to actually evaluate it.
Lucene happens to produce it as a byproduct of its execution model, but in the general case, computing the total number of results for a query can be enormously expensive.
Imagine a physical phone book, and I ask you to get me the first ten people whose family name is Smith. You flip to the S section, find Smith, read off the first ten entries, and hand them back. Notice what you didn't do: you never counted how many Smiths there are.
Now I ask you for the total number of Smiths. Suddenly, you have to go through every single Smith in the book and tally them. Smith is a common name. The cost of counting all of them can be far higher than the cost of just grabbing the first ten.
If you want a count, you have to actually count, which means touching every matching result, even the ones you're about to throw away. For large queries, getting the count can be the most expensive part of the query.
The feature is still meaningful, to be clear. There are plenty of cases where you genuinely need the total so you can build proper pagination. And in those cases, going to the database twice and paying for two network round-trips is wildly wasteful, so bundling the count in is exactly the right thing to do.
How would I design this today?
I would approach this very differently. You often don’t need an exact count; you just need to show something so the application can render the paging controls and maybe show a rough count to the user.
I would probably expose an
EstimatedCountproperty for the queries, which is cheap, as well as a way to ask for an exact count in a single roundtrip. The key is that we would be clear in the contract that this is an estimation only.
But because this was a basic, baked-in behavior of RavenDB, something we'd done "for free" from day one, Corax inherited an expectation that it had to provide an exact count. We were doing work on every query, only to end up discarding the result of that work, because the original engine had made it cost nothing, and so everyone assumed it cost nothing.
How we dealt with it
We solved this with a combination of approaches.
First, it turns out you don't always need the count. Since the count is requested through the API, we made it explicit: the client can say "I care about the total count" or "I don't care about the total count." When the client opts out, we get to skip all that work. That alone recovers a lot of wasted effort.
Second, queries in RavenDB request the count far more often than they do in other databases, precisely because it used to be free. Years of RavenDB code were written assuming the count was always there, so there was enormous pressure to make counting itself fast rather than just optional. We did a significant amount of work to optimize how counting happens.
And this turns out to be a genuinely deep area. There is a whole body of research on how to count query results with as little work as possible. People have earned PhDs on this problem. What looked, from the application developer's seat, like a single integer that just shows up in the response is an entire field of study once you're the one who has to produce it.
Hyrum's Law sends its regards
There's a principle called Hyrum's Law that captures exactly what happened here:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
The actual lesson
When you get something for free from a dependency, you are not just accepting a feature. You are accepting an obligation. The behavior becomes observable, the observable becomes relied upon, and the relied-upon becomes a promise you have to keep, possibly long after the dependency that gave it to you is gone.
The real price of a dependency is the behavior that you need to carry forward down the line, because it became part of your contract and your users rely on it. And that requires very careful consideration.
I want to be careful here, because the lesson is not "don't take free things" or "don't depend on Lucene." Building on Lucene was the right call, and exposing the count was the right call. I'd probably make both decisions again (although I would weaken the promise about the accuracy of the count).
To be more accurate, I don’t think that the person who took that dependency twenty years ago was even able to properly understand the impact of that feature or its future complications. On the other hand, that specific feature was something that I frequently demoed, and it always got a great reaction. This touched a pain point that many people had.
Hyrum wins again 🙂.