




time to read 1 min | 20 words
My podcast interview with Wesley Reisz from InfoQ has been published. I think it was a very interesting discussion.

My podcast interview with Wesley Reisz from InfoQ has been published. I think it was a very interesting discussion.
I’m teaching a college class about Cloud Computing and part of that is giving various assignments to build stuff on the cloud. That part is pretty routine.
One of my requests for the tasks is to identify failure mode in the system, and one of the students that I’m currently grading had this doozy scenario:
If you’ll run this code you may have to deal with this problem. Just nuke the system and try again, it only fails because of this once in a while.
The underlying issue is that he is setting up a Redis instance that is publicly accessible to the Internet with no password. On a regular basis, automated hacking tools will scan, find and ransom the relevant system. To the point where the student included a note on that in the exercise.
A great reminder that the Network is Hostile. And yes, I’m aware of Redis security model, but I don’t agree with it.
I’m honestly not sure how I should grade such an assignment. On the one hand, I don’t think that a “properly” secured system is reasonable to ask from a student. On the other hand, they actually got hacked during their development process.
I tried setting up a Redis honeypot to see how long it would take to get hacked, but no one bit during the ~10 minutes or so that I waited.
I do wonder if the fact that such attacks are so prevalent, immediate and destructive means that through the process of evolution, you’ll end up with a secured system (since unsecured isn’t going to be working).
A few weeks ago I wrote about the Hare language and its lack of generic data structures. I don’t want to talk about this topic again, instead I want to discuss something more generic (pun intended). In my view, any modern programming language that aims for high performance should have some form of generics in it. To not have that in place is a major mistake and a huge cause for additional complexity and loss of performance. One aspect of that is the fact that generic data structures get a lot more optimizations than one-off implementations. But I already talked about that in the previous post.
The other issue is that by not having generics, there is a huge barrier for optimizations in front of you. You lack the ability to build certain facilities at all. Case in point, let us take a topic that is near and dear to my heart, sorting. Working on sorted data is pretty much the one thing that makes databases work. Everything else is just details on top of that, nothing more. Let’s consider how you sort data (in memory) using a few programming languages, using their definitions
Using C:
void qsort (void *array, size_t count, size_t size, comparison_fn_t compare);
int comparison_fn_t (const void *, const void *);
Using C++:
template <class RandomAccessIterator>
void sort (RandomAccessIterator first, RandomAccessIterator last);
Using Java:
public static void sort(int [] a);
public static void sort(long[] a);
public static void sort(Object[] a);
Using C#:
public static void Sort<T> (T[] array);
Using Hare:
type cmpfunc = fn(a: const *void , b: const *void ) int ;
fn sort([]void , size, *cmpfunc) void ;
Using Rust:
impl<T> [T] {
pub fn sort(&mut self)
where
T: Ord,}
Using Zig:
pub fn sort(
comptime T: type,
items: []T,
context: anytype,
comptime lessThan: fn (context: @TypeOf(context), lhs: T, rhs: T) bool,
) void
I’m looking only at the method declaration, not the implementation. In fact, I don’t care about how this is implemented at this point. Let’s assume that I want to sort an array of integers, what would be the result in all of those languages?
Well, they generally fall into one of a few groups:
C & Hare – will require you to write something like this:
In other words, we are passing a function pointer to the sorting routine and we’ll invoke that on each comparison.
C++, C#, Rust, Zig – will specialize the routine for the call. On invocation, this will look like this:
The idea is that the compiler is able to emit code specifically for the invocation we use. Instead of having to emit a function call on each invocation, the compare call will usually be inlined and the cost of invocation is completely eliminated.
Java is the only one on this list that has a different approach. Instead of using generics at compile time, it is actually doing a dispatch of the code to optimized routines based on runtime types. That does mean that they had to write the same sort code multiple times, of course.
Note that this isn’t anything new or novel. Here is a discussion on the topic when Go got generics, in the benchmark there, there is a 20% performance improvement from moving to the generics version. That results from avoiding the call overhead as well as giving the compiler more optimization opportunities.
Going back to the premise of this post, you can see how a relatively straightforward decision (having generics in the language) can have a huge impact on the performance of what is one of the most common scenarios in computer science.
The counter to this argument is that we can always specialize the code for our needs, right? Except… that this isn’t something that happens. If you have generics, you get this behavior for free. If you don’t, well, this isn’t being done.
I write databases for a living, and the performance of our sorting code is something that we analyze at the assembly level. Pretty much every database developer will have the same behavior, I believe. The performance of sorting is pretty key to everything a database does. I run into this post, talking about performance optimizations in Postgres, and one of the interesting ones there was exactly this topic. Changing the implementation of sorting from using function pointers to direct calls. You can see the commit here. Here is what the code looks like:

Postgres is 25 years old(!) and this is a very well known weakness of C vs. C++. Postgres is also making a lot of sorting calls, and this is the sort of thing that is a low hanging fruit for performance optimization.
As for the effect, this blog post shows 4% – 6% improvement in overall performance as a result of this change. That means that for those particular routines, the effect is pretty amazing.
I can think of very few scenarios where a relatively simple change can bring about 6% performance improvement on a well-maintained and actively worked-on 25-year-old codebase.
Why am I calling it out in this manner, however?
Because when I ran into this blog post and the optimization, it very strongly resonated with the previous discussion on generics. It is a great case study for the issue. Because the language (C, in the case of Postgres) isn’t supporting generics in any meaningful way, those sorts of changes aren’t happening, and they are very costly.
A modern language that is aiming for performance should take this very important aspect of language design into account. To not do so means that your users will have to do something similar to what Postgres is doing. And as we just saw, that sort of stuff isn’t done.
Not having generics means that you are forcing your users to leave performance on the table.
Indeed, pretty much all the modern languages that care for high performance have generics. The one exception that I can think of is Java, and that is because it chose backward compatibility when it added generics.
Adding this conclusion to the previous post about generics data structure, I think that the final result is glaringly obvious. If you want high-performance system, you should choose a language that allows you to express it easily and succinctly. And generics are mandatory tooling in the box for that.
I had a great discussion with Trevor, the CTO of Rakuten Kobo about their use of RavenDB, you can watch it here:
Consider an eCommerce system where customers can buy stuff. Part of handling commerce is handling faults. Those range from “I bought the wrong thing” to “my kid just bought a Ferrari”. Any such system will need some mechanism to handle fixing those faults.
The simplest option we have is the notion of refunds. “You bought by mistake, we can undo that”.
In many systems, the question is then “how do we manage the process of refunds”? You can do something like this:

So a customer requests a refund, it is processed by the Help Desk and is sent for approval by Finance, who is then consulting Fraud and then get sign off by the vice –CFO.
There are about 12 refunds a quarter, however. Just the task of writing down the rules for processing refunds costs more than that.
Instead, a refund policy can state that anyone can request a refund within a certain time frame. At which point, the act of processing a refund becomes:

Is there a potential for abuse? Probably, but it is going to be caught naturally as we see the number of refunds spike over historical levels. We don’t need to do anything.
In fact, the whole idea relies on two important assumptions:
Trying to create a process to handle this is a bad idea if the number of refunds is negligible. It costs too much, and making refunds easy is actually a goal (since that increases trust in the company as a whole).
You can register for the webinar here.
In my previous post, I asked why this change would result in a better performing system, since the total amount of work that is done is the same:
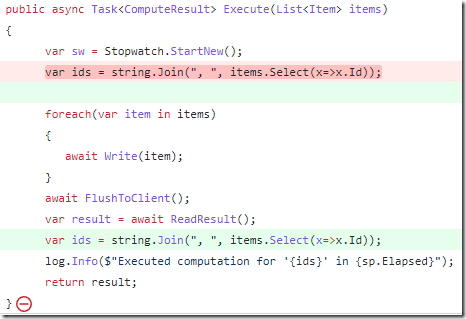
The answer is quite simple. The amount of work that our code is doing is the same, sure, but that isn’t all the code that runs.
In the first version, we would allocate the string, and then we’ll start a bunch of async operations. Those operations are likely to take some time and involve I/O (otherwise, they wouldn’t be async).
It is very likely that in the meantime, we’ll get a GC run. At that point, the string pointed to be the ids variable will be promoted (since it survived a GC). That means that it would be collected much later.
Using the new code, the scope of the ids string is far shorter. That means that the GC is more likely to catch it very early and significantly reduce the cost of releasing the memory.
Take a look at the following code:
If we move line 4 to line 11, we can improve the performance of this code significantly. Here is what this looks like:

The question is, why?
The exact same amount of work is being done in both cases, after all. How can this cause a big difference?
I run into this blog post about the Hare language and its approach to generic data structures. From the blog post, we have this quote:
…it’s likely that the application of a higher-level data structure will provide a meaningful impact to your program. Instead of providing such data structures in the standard library (or even, through generics, in third-party libraries), Hare leaves this work to you.
And this one, at the end:
Hare doesn’t provide us with a generic hash map, but we were able to build one ourselves in just a few lines of code. A hash map is one of the simpler data structures we could have shown here, but even for more complex ones, you’ll generally find that it’s not too difficult to implement them yourself in Hare.
I… don’t really know where to begin. The relevant code is here, by the way, and you can see how this works.
A hash table is not a simple data structure, let’s start with that. It is the subject of much research and a ton of effort was spent on optimizing them. They are not the sort of things that you roll out yourself. To give some context, here are some talks from CppCon that talks about this:
Abseil's Open Source Hashtables: 2 Years In - Matt Kulukundis - CppCon 2019
C++Now 2018: You Can Do Better than std::unordered_map: New Improvements to Hash Table Performance
CppCon 2017: Matt Kulukundis “Designing a Fast, Efficient, Cache-friendly Hash Table, Step by Step”
CppCon 2017 Designing a Fast, Efficient, Cache friendly Hash Table, Step by Step
So in a quick search, we can see that there is a lot to discuss here. For that matter, here are some benchmark results, which compare:
Why are there so many of those?
Well, because that matters. Each of those implementations is optimizing for something specific in different ways. There isn’t just a hash table algorithm, the details matter. A lot.
The fact that Hare believes that a Hashtable or a map does not have to have a solution is pure insanity in my opinion. Let’s look at the example that is provided in the post, shall we? You can see the raw code here.

Let’s take a look to understand what is going on here. There is a static array with 64 buckets that are used as the module cache. In each one of those buckets, you have an array of entries that match that bucket. The hash key here is the FNV32 of the AST node in question.
Let’s see how many things just pop to mind immediately in here as issues. Let’s start with the fact that this is a statically sized hash table, which may be appropriate for this scenario, but won’t fit many others. If we need to handle growing the underlying array, the level of complexity will shoot up significantly.
The code is also not handling deletes (another complicated topic), and the hash collision mode is chaining (via growing the array). In other words, for many other scenarios, you’ll need to roll your own hash table (and see above about the complexities involved).
But let’s take it a bit further. The code is using FNV to compute the hash key. It is also making an assumption here, that the keys will never collide. Let’s see how well that holds up, shall we?
In other words, it took me a few minutes and under 130 ms to find a hash collision for this scenario. The code above does not handle it. For example, here are a couple of collisions:
Those are going to be counted as the same value by the Hare code above. Fixing this requires non trivial amount of code changes.
For that matter, let’s talk for a second about the manner in which I found it. If I were trying to write the same code in Hare, what would I have to do?
Well, the answer to that is to write a lot of code, of course. Because I would have to re-implement a hash table from scratch.
And the design of the Hare language doesn’t even allow me to provide that as a library. I have to fall down to code generation at best.
These sorts of things matter. In C, you don’t have a hash table, and the most natural data structure is some form of a linked list. So that gets used a lot. You can bring in a hash table, of course, but adapting it for use is non trivial, so they are used a lot less often. Try writing the same in Hare, and then compare the cost in time to run (and time to execute).
In modern languages, the inclusion of a hash table in the base language is a basic requirement. Languages like C++, Rust or Zig have that in the base class library and have the facilities to allow you to write your own generic data structure. That means that good data structures exist. That it make sense to spend the time writing them because they’ll be broadly applicable. Languages like C# or Java took this further and make sure that all objects have GetHashCode() and Equals() methods, specifically to support the hash table scenario. It is that important.
Even Go, before it had generics, had a dedicated syntax carved out in the language to allow you to use maps natively. And now that Go has generics, that is actually far faster.
In many systems, a hash table is one of the core data structures. It is used everywhere, and it lack make the ecosystem a lot more painful. Take a look at how Hare handles query string parameters:

I mean, I guess it would be nice to have a way to do streaming on query strings? But the most natural way to do that is to use a hash table directly. The same applies for things like headers in web requests, how would you even model that in Hare?
I couldn’t disagree more with the premise of the original post. A hashtable is not something that you should punt, the consequences for your users are dire.
No future posts left, oh my!