





Table scans, index scans and index seeks, on my!
In general, when you break it down to the fundamentals, a data base is just a fancy linked list + some btrees. Yes, I am ignoring a lot, but if you push aside a lot of the abstraction, that is what is actually going on.
If you ever dealt with database optimizations you are familiar with query plans, like the following (from NHProf):
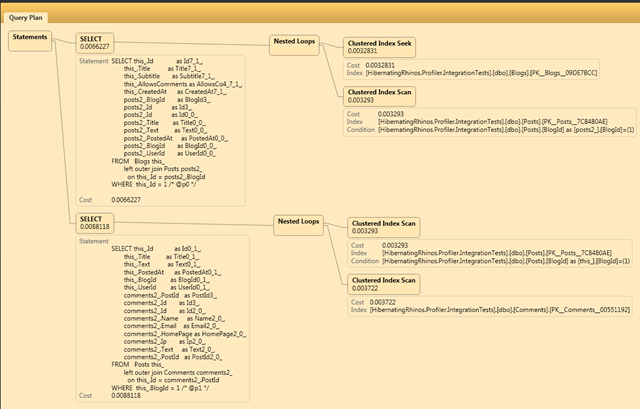
You can see that we have some interesting stuff going on here:
- Index Seek
- Index Scan
And if you are unlucky, you are probably familiar with the dreaded “your !@&!@ query is causing a table scan!” scream from the DBA. But most of the time, people just know that table scan is slow, index scan is fast and index seek is fastest. I am ignoring things like clustered vs. unclustered indexes, since they aren’t really important for what I want to do.
For simplicity sake, I’ll use the following in memory data structure:
public class DocumentDatabase { public List<JObject> Documents = new ...; public IDictionary<string, IDictionary<JToken, JObject>> Indexes = new ...; }
To keep things simple, we will only bother with the case of exact matching. For example, I might store the following document:
{ "User": "ayende", "Name": "Ayende Rahien", "Email": "Ayende@ayende.com" }
And define an index on Name & Email. What would happen if I wanted to make a query by the user name?
Well, we don’t really have any other option, we have to do what amounts to a full table scan:
foreach (var doc in Documents) { if(doc.User == "ayende") yield return doc; }
As you can imagine, this is an O(N) operation, which can get pretty expensive if we are querying a large table.
What happen if I want to find data by name & email? We have an index that is perfectly suited for that, so we might as well use it:
Indexes["NameAndEmail"][new{Name="Ayende Rahien", Email = “Ayende@ayende.com”}];
Note that what we are doing here is accessing the NameAndEmail index, and then making a query on that. This is essentially an index seek.
What happens if I want to query just by email? There isn’t an index just for emails, but we do have an index that contains emails. We have two options, use a table scan, or and index scan. We already saw what a table scan is, so let us look at what is an index scan:
var nameAndEmailIndex = Indexes["NameAndEmail"]; foreach (var indexed in nameAndEmailIndex) { if(indexed.Email == "ayende@ayende.com") yield return indexed; }
All in all, it is very similar to the table scan, and when using in memory data structures, it is probably not worth doing index scans (at least, not if the index is over the entire data set).
Where index scans prove to be very useful is when we are talking about persistent data sets, where reading the data from the index may be more efficient than reading it from the table. That is usually because the index is much smaller than the actual table. In certain databases, the format of the data on the disk may make it as efficient to do a table scan in some situations as it to do an index scan.
Another thing to note is that while I am using hashes to demonstrate the principal, in practice, most persistent data stores are going to use some variant of trees.
Comments
You seem thinking only about finding one entity, but I'll tell you what else the index scans are useful for: to be able to enumerate entities in a pre-sorted way. Either to extract a pre-sorted sublist of the entire list, or to retrieve the entire list presorted. This could be useful as is (because for example the query has an ORDER BY) or because another part of the query could benefit from presorting (e.g. a merge join).
Zvolkov,
This is pretty much because I am focusing on just internal details on what this actually matter.
I am using index scans quite often, actually. Good point
Did you evaluate keeping Lucene as the index engine with your new Transactional Storage? If so, maybe you could write a post about that, explaining why (it seems) you chose to write your own indexing engine on top of your storage instead of just optimising the storage.
Simon,
Indexing is a bit more complex than a binary choice between Lucene or not.
For example, when implementing the managed storage for Raven, I need to store documents in the disk, and then I need to read them back.
How do you find document "users/ayende" ? That is what I refer to as Index Seek.
How do you find all the documents that were changed after a certain point in time? That is an Index Scan.
Those aren't tasks that I can shell to Lucene.
Ayende,
"How do you find all the documents that were changed after a certain point in time"
Just thinking out loud, but if your Storage had that knowledge (ie, LastUpdated) and Lucene was hooked deeply to it, then Lucene would know about it, wouldn't it?
Just to make it clear, I find it VERY interesting that you are implementing your own indexing engine, I'm just wondering what could be done with Lucene in this particular case.
Simon,
Theoretically, yes, you could.
The problem is that I am updating Lucene in the background, and that are some questions that I have to have a transactional answer to
The last update one, for example, is important for replication
Where can I find the query plans window in NHProf? Can't find it.
Martin,
It is right next to show query results, in the bottom of the screen.
Comment preview