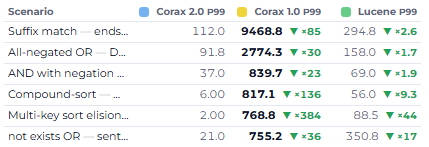
I've written before about why I think the “modern” approach of solving every problem by adding agents is a doomed path. The current instinct is to add more layers of agents, judges, reviewers, etc. - and hope the model will be smart enough to do the right thing and actually get something done.
The issue is that we already have a well-understood way to coordinate independent contributors working on a complex system. It's called software design & architecture, and we've been refining it for decades. The instinct to solve a coordination problem by adding a smarter message bus between your agents is exactly backwards.
When talking about multi-agent support in RavenDB, I want to be clear about what we did not build. We didn't build an orchestration framework. We didn't build a swarm. What we built is much more boring, and I mean that as the highest compliment I know how to give.
We built a way for you to solve problems in a predictable manner and without a lot of hassle.
If you haven't looked at RavenDB's AI Agents yet, the short version is this: an agent is a system prompt, a connection to an LLM, and a set of Query tools, which let the agent read specific data through RQL you define, and Action tools, which let it do something in your application, but only through the specific doors you've opened.
The note on “specific” is the whole point. Instead of giving the model the freedom to access any data it wants and execute anything it feels like, we place careful guardrails that it cannot escape.
The agent can only pull the levers you gave it, using the data you explicitly handed it. The database takes care of the tedious, error-prone plumbing (such as conversation state, message history, talking to the model provider, etc.) and stores every conversation as a real document in the @conversations collection. You define capabilities, and RavenDB takes care of all the rest.
Where one agent starts to hurt
A single agent like this will take you a genuinely long way. Right up until it doesn't. The issue is the slow creep of complexity. Let’s say that you start with a simple agent to deal with answering employee questions in the context of the HR department.
The next feature is to assist them in filing expense reports. Then someone wants it to handle time-off requests, and then to look up the org chart, and six months later you have one prompt trying to be an entire company, with thirty tools competing for the model's attention and a context window stuffed with things that have nothing to do with the question being asked.
That situation is problematic on multiple levels:
- Your context window is full of a huge prompt (usually not relevant to the task at hand), a lot of tool descriptions and capabilities meant to cover every possible scenario under the sun.
- Users’ questions are either squeezed into the remaining context window or you have to move to models with larger context windows, which also cost more.
- You are also stuck with a single model for everything, instead of being able to pick the right model for each scenario. You overpay to run trivial chit-chat on your best model, or you cripple the hard tasks by forcing them onto a cheap one.
This is not a new problem. Scope is how you manage complexity, and it works exactly the same whether the thing on the other end is a compiler or a language model.
Multi-agents are just agents that talk to each other
A multi-agent system in RavenDB is not a special kind of agent. It's several ordinary agents, each built exactly the way you already know how to build one, where one of them happens to know that another exists and can hand work to it.
The way you connect them is almost anticlimactic. You add a SubAgents entry to the parent agent: an identifier and a description. That's the entire wiring job. The description matters because that's what the parent reads to decide whether a given request belongs to the specialist. There is no router you write, no dispatch table, no orchestration layer.
You made the subagent available to the root, and RavenDB will invoke it for you when it is needed. RavenDB will also handle all the logistical minutiae needed to accomplish this successfully.
Those include ensuring that the scope for the root agent is shared with the called subagents, managing memory and conversation history, allowing the subagent to invoke its own queries and actions, etc.
We ship a demo for this — an HR chatbot, samples-hr on GitHub if you want to run it yourself. An employee comes back from a conference, uploads the receipt, and types "submit this expense." From their side, it's one smooth conversation.
Behind the scenes, it's two agents. The HR Assistant faces the user and handles benefits, policies, and general questions. It does not know the first thing about filing an expense. What it does know is that there's an Expense Manager specialist, and — from that one-line description — that receipts belong to it. It hands the task over, the specialist analyzes the receipt and creates the BusinessTripBills document, and the answer flows back up.
Go look in the database afterward and you'll find two conversation documents, not one — the HR Manager's log and the Expense Manager's log, each with its own scoped history. That's not an implementation detail I'm mentioning for trivia's sake. It means you can open either conversation and see exactly what that agent received and how it responded. The audit trail falls out of the design for free.
Here's the parent agent, trimmed down to the part that matters:
public static Task Create(IDocumentStore store)
{
return store.AI.CreateAgentAsync(
new AiAgentConfiguration
{
Name = "HR Assistant",
Identifier = AgentIdentifier,
ConnectionStringName = ConnectionStringName,
SystemPrompt = @"You are an HR assistant.
Provide info on benefits, policies, and departments.
Do not suggest actions that are not explicitly allowed by the tools available to you.
Do NOT discuss non-HR topics. Answer only for the current employee.",
Parameters =
[
new AiAgentParameter(EmployeeIdParameter,
"Employee ID; answer only for this employee")
],
// The HR agent has no idea how to file an expense.
// It just knows a specialist exists, and when to call it.
SubAgents =
[
new AiAgentToolSubAgent
{
Identifier = ExpenseAgentIdentifier,
Description = "Manages business trip expenses: analyzing " +
"receipts/bills, reporting expenses, and retrieving " +
"monthly expense summaries."
}
],
// Its own capabilities cover only HR concerns.
Queries =
[
new AiAgentToolQuery
{
Name = "GetEmployeeInfo",
Description = "Retrieve employee details",
Query = $"from Employees where id() = ${EmployeeIdParameter}",
ParametersSampleObject = "{}"
}
]
});
}The Expense Manager, for its part, is defined in exactly the same way as any other agent. There is nothing special about it. It's a normal agent that happens to be pointed at by a SubAgents entry.
Notice what this buys you. The HR agent never sees the finance tooling. It doesn't integrate the expense system, doesn't swallow that domain, or deal with a BusinessTripBills document. It shells the call out to the specialist and stays in its lane. If tomorrow finance wants their own policy-checking agent in the loop, you add another SubAgents entry to the Expense Manager and the HR agent is none the wiser. Each piece keeps a small & independent scope.
Each of those agents is isolated from the others, so we can have the HR Agent use a pure textual model, maybe with high levels of reasoning. The Expense Manager agent, on the other hand, needs to be multimodal (to be able to read receipt images), but it doesn’t need to be smart. You can customize each for its own needs, without having to find the lowest common denominator.
The fact that each of those agents (even if they both participate in the same conversation) will use separate @conversations documents also means their contexts are isolated from one another. The fact that you just pushed the entire set of receipts from a two-week business trip to the Expense Manager agent doesn’t weigh down the HR agent when you ask about your remaining holiday balance.
When you should not do this
This shouldn’t be your default architecture. Like any advanced technique, you need a sufficient level of complexity to justify it. If the work fits in one sentence, it probably fits in one agent.
Answering from a knowledge base, generating a document from a template, running a linear sequence with no branching — a single well-built agent handles all of that, and reaching for sub-agents just to keep things tidy or to mirror your org chart is perfectionism. It's the same mistake as premature abstraction, and it costs you real latency and real tokens for the privilege.
Multi-agents earn their keep when one of the following is true:
- You need to independently develop the agents (different teams are handling different agents).
- You will use different models for different parts of the system.
- You want to explicitly limit the sharing of context between different parts of the system.
For example, keeping with the HR agent theme, let’s say that we want to allow users to ask questions about our policies (an example of such an agent). The problem here is that we may have a lot of policies, and even when we limit ourselves to the right one, that is a lot of text.
Shoving all of the work of finding the right policy and extracting the specific elements to match the user’s question into an isolated agent can massively reduce the number of tokens that your agents will burn.
Summary
RavenDB’s multi-agents aren’t about orchestrating a robot army or an independent swarm of self-coordinating agents. It is far more prosaic than that. You're composing independent components with clear boundaries and letting each one own a scoped conversation, its own tools, and the model that fits its job.
That's not a new idea we invented for the age of AI. It’s bringing back the notion of independent components that are greater than the sum of their parts, in a way that is manageable, consistent, and hassle-free.
If you want to try it, grab a free Developer license or spin up a free Cloud database, and the multi-agent guide walks through the demo end to end.