I am working a bit with sparse files, and I need to output the list of holes in my file.
To my great surprise, I found that my file had more holes than I put into it. This probably deserves a bit of explanation.
If you know what sparse files are, feel free to skip this explanation:
A sparse filereduces disk space usage by storing only the non-zero data blocks.Zero-filled regions ("holes") are recorded as file system metadata only.
The file still has the same “size”, but we don’t need to dedicate actual disk space for ranges that are filled with zeros, we can just remember that there are zeros there. This is a natural consequence of the fact that files aren’t actually composed of linear space on disk.
Filesystems grow files using extents (contiguous disk chunks).A file initially gets a single extent (e.g., 1MB).Fast I/O is maintained as sequential data fills this contiguous block.Once the extent is full, the filesystem allocates a new, separate extent (which will not reside next to the previous one, most likely).The file's logical size grows continuously, but physical allocation occurs in discrete bursts as new extents are dynamically added.
If you are old enough to remember running defrag, that was essentially what it did. Ensured that the whole file was a single continuous allocation on disk. Because of this, it is very simple for a file system to just record holes, and the only file system that you’ll find in common use today that doesn’t support it is FAT.
At any rate, I had a problem. My file has more holes than expected, and that is not a good thing. This is the sort of thing that calls for a “Stop, investigate, blog” reaction. Hence, this post.
If you run this code, you’ll see this surprising result:
Start: 0.00 MB,End: 1024.00 MB
In other words, even though we just use fallocate() to ensure that we reserved the disk space, as far as lseek() is concerned, it is just one big hole. What is going on here?
Let’s dig a little deeper, using filefrag:
$ filefrag -b1048576 -v test-sparse-file.dat
Filesystem type is: ef53
File size of test-sparse-file.dat is 1073741824 (1024 blocks of 1048576 bytes)
ext:logical_offset:physical_offset:length:expected:flags:0:0.. 23:165608.. 165631:24: unwritten
1:24.. 151:165376.. 165503:128:165632: unwritten
2:152.. 279:165248.. 165375:128:165504: unwritten
3:280.. 407:165120.. 165247:128:165376: unwritten
4:408.. 535:164992.. 165119:128:165248: unwritten
5:536.. 663:164864.. 164991:128:165120: unwritten
6:664.. 791:164736.. 164863:128:164992: unwritten
7:792.. 919:164608.. 164735:128:164864: unwritten
8:920.. 1023:164480.. 164583:104:164736: last,unwritten,eof
test-sparse-file.dat: 9 extents found
You can see that the file is made of 9 separate extents. The first one is 24MB in size, then 7 extents that are 128MB each, and the final one is 104MB.
Amusingly enough, the physical layout of the file is in reverse order to the logical layout of the file. That is just the allocation pattern of the file system, since there is no relation between the two.
Now, let’s try to figure out what is going on here. Do you see the flags on those extents? It says unwritten. That means this is physical space that was allocated to the file, but the file system is aware that it never wrote to that space. Therefore, that space must be zero.
In other words, conceptually, this unwritten space is no different from a sparse region in the file. In both cases, the file system can just hand me a block of zeros when I try to access it.
The question is, why is the file system behaving in this manner? And the answer is that this is an optimization. Instead of reading the data (which we know to be zeros) from the disk, we can just hand it over to the application directly. That saves on I/O, which is quite nice.
Consider the typical scenario of allocating a file and then writing to it. Without this optimization, we would literally double the amount of I/O we have to do.
It turns out that this optimization also applies to Windows and Mac, but the reason I ran into that on Linux is that I used the lseek(SEEK_HOLE), which considers the unwritten portion as a sparse hole as well. This makes sense, since if I want to copy data and I am aware of sparse regions, I should treat the unwritten portions as holes as well.
You can use the ioctl(FS_IOC_FIEMAP) to inspect the actual file extents (this is what filefrag does) if you actually care about the difference.
I don’t like this code because the API is trying to guess the intent of the caller. We are making some reasonable inferences here, for sure, but we are also ensuring that any future progress will require us to change our code, instead of letting the caller do that.
In fact, the caller probably knows a lot more than we do about what is going on. They know if they are uploading an image, and probably in what format too. They know that they just uploaded a CSV file (and that we need to classify it as plain text, etc.).
This is one of those cases where the best option is not to try to be smart. I recommended that we write the function to let the caller deal with it.
It is important to note that this is meant to be a public API in a library that is shipped to external customers, so changing something in the library is not easy (change, release, deploy, update - that can take a while). We need to make sure that we aren’t blocking the caller from doing things they may want to.
This is a case of trying to help the user, but instead ending up crippling what they can do with the API.
RavenDB has recently introduced its dedicated Kubernetes Operator, a big improvement over the Helm charts that teams have been using. This is meant to streamline database orchestration and management, essentially giving you an automated "SRE-in-a-box."
The Operator shifts the management paradigm from manual configuration to a declarative model. Simply applying a RavenDBCluster custom resource definition (CRD) allows developers to automate the heavy lifting of cluster formation, storage binding, and external networking, removing the operational friction typically associated with running stateful distributed systems on K8s.
Most importantly, it isn’t a one-time thing. The RavenDB Kubernetes Operator is all about "Day 2" operational intelligence. It handles complex lifecycle tasks with high precision, such as executing safe rolling upgrades with built-in validation gates to prevent breaking changes.
From dealing with the intricacies of certificate rotation—supporting both Let’s Encrypt and private PKI—to providing real-time health insights directly via kubectl, the automation of these critical maintenance tasks lets the Operator ensure that your RavenDB clusters remain resilient, secure, and performant with minimal manual intervention.
For example, you can push an upgrade from RavenDB 7.0 to RavenDB 7.2, and the Operator will automatically handle performing a rolling upgrade for you, ensuring there is no downtime during deployment. There is no need for complex orchestration playbooks, you just push the update, and it happens for you.
I’m looking for a key technical voice to join the team: a Sales Engineer who will be based in a GMT to GMT+3 time zone to best support our growing European and international customer base.
We want someone who is passionate about solving complex technical challenges who can have fun talking to people and building relationships.You’ll bridge the gap between our technology and our customers' business needs.
The Technical Chops:We need a technical champion for the sales process.That means diving deep into solution architecture, designing and executing proof-of-concepts, and helping customers architect reliable, scalable, and ridiculously fast systems using RavenDB.You need to understand databases (SQL, NoSQL, and the cloud), and be ready to learn RavenDB's powerful features inside and out.If you have a background in development (C#, Java, Python—it all helps!) and enjoy thinking about things like indexing strategies, data modeling, and performance tuning, you’ll love this.
People Person: You need to be able to walk into a room (virtual or physical), quickly identify a customer's pain points, and articulate a clear, compelling vision for how RavenDB solves them.This role requires excellent communication skills—you’ll be giving engaging demos, leading technical presentations, and collaborating directly with high-level technical teams.If you can discuss a multi-region deployment strategy one minute and explain the ROI to a business executive the next, you’ve got the commercial savviness we’re looking for.
You should have 3+ years of experience in a pre-sales or solution architecture role. A strong general database background is required, experience with NoSQL databases is a big plus.
Please ping us either via commenting here or submit your details to jobs@ravendb.net
You may have heard about a recent security vulnerability in MongoDB (MongoBleed). The gist is that you can (as an unauthenticated user) remotely read the contents of MongoDB’s memory (including things like secrets, document data, and PII). You can read the details about the actual technical issue in the link above.
The root cause of the problem is that the authentication process for MongoDB uses MongoDB’s own code. That sounds like a very strange statement, no? Consider the layer at which authentication happens. MongoDB handles authentication at the application level.
Let me skip ahead a bit to talk about how RavenDB handles the problem of authentication. We thought long and hard about that problem when we redesigned RavenDB for the 4.0 release. One of the key design decisions we made was to not handle authentication ourselves.
Authentication in RavenDB is based on X.509 certificates. That is usually the highest level of security you’re asked for by enterprises anyway, so RavenDB’s minimum security level is already at the high end. That decision, however, had a lot of other implications.
RavenDB doesn’t have any code to actually authenticate a user. Instead, authentication happens at the infrastructure layer, before any application-level code runs. That means that at a very fundamental level, we don’t deal with unauthenticated input. That is rejected very early in the process.
It isn’t a theoretical issue, by the way. A recent CVE was released for .NET-based applications (of which RavenDB is one) that could lead to exactly this issue, an authentication bypass problem.RavenDB is not vulnerable as a result of this issue because the authentication mechanism it relies on is much lower in the stack.
By the same token, the code that actually performs the authentication for RavenDB is the same code that validates that your connection to your bank is secure from hackers. On Linux - OpenSSL, on Windows - SChannel. These are already very carefully scrutinized and security-critical infrastructure for pretty much everyone.
This design decision also leads to an interesting division inside RavenDB. There is a very strict separation between authentication-related code (provided by the platform) and RavenDB’s.
The problem for MongoDB is that they reused the same code for reading BSON documents from the network as part of their authentication mechanism.
That means that any aspect of BSON in MongoDB needs to be analyzed with an eye toward unauthenticated user input, as this CVE shows.
An attempt to add compression support to reduce network traffic resulted in size confusion, which then led to this problem. To be clear, that is a very reasonable set of steps that happened. For RavenDB, something similar is plausible, but not for unauthorized users.
What about Heartbleed?
The name Mongobleed is an intentional reference to a very similar bug in OpenSSL from over a decade ago, with similar disastrous consequences. Wouldn’t RavenDB then be vulnerable in the same manner as MongoDB?
That is where the choice to use the platform infrastructure comes to our aid. Yes, in such a scenario, RavenDB would be vulnerable. But so would pretty much everything else. For example, MongoDB itself, even though it isn’t using OpenSSL for authentication, would also be vulnerable to such a bug in OpenSSL.
The good thing about OpenSSL’s Heartbleed bug is that it shined a huge spotlight on such bugs, and it means that a lot of time, money, and effort has been dedicated to rooting out similar issues, to the point where trust in OpenSSL has been restored.
Summary
One of the key decisions that we made when we built RavenDB was to look at how we could use the underlying (battle-tested) infrastructure to do things for us.
For security purposes, that means we have reduced the risk of vulnerabilities. A bug in RavenDB code isn’t a security vulnerability, you have to target the (much more closely scrutinized) infrastructure to actually get to a vulnerable state. That is part of our Zero Trust policy.
RavenDB has a far simpler security footprint, we use the enterprise-level TLS & X.509 for authentication instead of implementing six different protocols (and carrying the liability of each). This both simplifies the process of setting up RavenDB securely and reduces the effort required to achieve proper security compliance.
You cannot underestimate the power of checking the “X.509 client authentication” box and dropping whole sections of the security audit when deploying a new system.
What is actually going on here? This small interaction showcases a number of RavenDB features, all at once. Let’s first focus on how Telegram hands us images. This is done using Photoor Document messages (depending on exactly how you send the message to Telegram).
The following code shows how we receive and store a photo from Telegram:
// Download the largest version of the photo from Telegram:var ms =newMemoryStream();var fileId =message.Photo.MaxBy(ps =>ps.FileSize).FileId;var file =awaitbotClient.GetInfoAndDownloadFile(fileId, ms, cancellationToken);// Create a Photo document to store metadata:var photo =newPhoto{ConversationId=GetConversationId(chatId),Id="photos/"+Guid.NewGuid().ToString("N"),RenterId=renter.Id,Caption=message.Caption??message.Text};// Store the image as an attachment on the document:awaitsession.StoreAsync(photo, cancellationToken);ms.Position=0;session.Advanced.Attachments.Store(photo,"image.jpg", ms);awaitsession.SaveChangesAsync(cancellationToken);// Notify the user that we're processing the image:awaitbotClient.SendMessage(
chatId,"Looking at the photo you sent..., may take me a moment...",
cancellationToken
);
A Photo message in Telegram may contain multiple versions of the image in various resolutions. Here I’m simply selecting the best one by file size, downloading the image from Telegram’s servers to a memory stream, then I create a Photo document and add the image stream to it as an attachment.
We also tell the client to wait while we process the image, but there is no further code that does anything with it.
Gen AI & Attachment processing
We use a Gen AI task to actually process the image, handling it in the background since it may take a while and we want to keep the chat with the user open. That said, if you look at the actual screenshots, the entire conversation took under a minute.
Here is the actual Gen AI task definition for processing these photos:
var genAiTask =newGenAiConfiguration{Name="Image Description Generator",Identifier=TaskIdentifier,Collection="Photos",Prompt="""
You are an AI Assistant looking at photos from renters in
rental property management, usually about some issue they have.
Your task is to generate a concise and accurate description of what
is depicted in the photo provided, so maintenance can help them.
""",// Expected structure of the model's response:SampleObject="""
{
"Description": "Description of the image"
}
""",// Apply the generated description to the document:UpdateScript="this.Description = $output.Description;",// Pass the caption and image to the model for processing:GenAiTransformation=newGenAiTransformation{Script="""
ai.genContext({
Caption: this.Caption
}).withJpeg(loadAttachment("image.jpg"));
"""},ConnectionStringName="Property Management AI Model"};
What we are doing here is asking RavenDB to send the caption and image contents from each document in the Photos collection to the AI model, along with the given prompt. Then we ask it to explain in detail what is in the picture.
Here is an example of the results of this task after it completed. For reference, here is the full description of the image from the model:
A leaking metal pipe under a sink is dripping water into a bucket. There is water and stains on the wooden surface beneath the pipe, indicating ongoing leakage and potential water damage.
What model is required for this?
I’m using the gpt-4.1-mini model here; there is no need for anything beyond that. It is a multimodal model capable of handling both text and images, so it works great for our needs.
We still need to close the loop, of course. The Gen AI task that processes the images is actually running in the background. How do we get the output of that from the database and into the chat?
To process that, we create a RavenDB Subscription to the Photos collection, which looks like this:
store.Subscriptions.Create(new SubscriptionCreationOptions
{
Name = SubscriptionName,
Query = """
from "Photos"
where Description != null"""
});
This subscription is called by RavenDB whenever a document in the Photos collection is created or updated with the Description having a value. In other words, this will be triggered when the GenAI task updates the photo after it runs.
The actual handling of the subscription is done using the following code:
_documentStore.Subscriptions.GetSubscriptionWorker<Photo>("After Photos Analysis").Run(asyncbatch=>{
using var session = batch.OpenAsyncSession();foreach(var item in batch.Items){var renter =await session.LoadAsync<Renter>(
item.Result.RenterId!);awaitProcessMessageAsync(_botClient, renter.TelegramChatId!,
$"Uploaded an image with caption: {item.Result.Caption}\r\n"+
$"Image description: {item.Result.Description}.",
cancellationToken);}});
In other words, we run over the items in the subscription batch, and for each one, we emit a “fake” message as if it were sent by the user to the Telegram bot. Note that we aren’t invoking the RavenDB conversation directly, but instead reusing the Telegram message handling logic. This way, the reply from the model will go directly back into the users' chat.
You can see how that works in the screenshot above. It looks like the model looked at the image, and then it acted. In this case, it acted by creating a service request. We previously looked at charging a credit card, and now let’s see how we handle creating a service request by the model.
The AI Agent is defined with a CreateServiceRequest action, which looks like this:
Actions =[
new AiAgentToolAction
{
Name ="CreateServiceRequest",
Description ="Create a new service request for the renter's unit",
ParametersSampleObject = JsonConvert.SerializeObject(
new CreateServiceRequestArgs
{
Type ="""
Maintenance | Repair | Plumbing | Electrical |
HVAC | Appliance | Community | Neighbors | Other
""",
Description ="""
Detailed description of the issue with all
relevant context
"""
})},
]
As a reminder, this is the description of the action that the model can invoke. Its actual handling is done when we create the conversation, like so:
conversation.Handle<PropertyAgent.CreateServiceRequestArgs>("CreateServiceRequest",async args =>{
using var session = _documentStore.OpenAsyncSession();var unitId =renterUnits.FirstOrDefault();var propertyId = unitId?.Substring(0,unitId.LastIndexOf('/'));var serviceRequest =newServiceRequest{RenterId=renter.Id!,UnitId= unitId,Type=args.Type,Description=args.Description,Status="Open",OpenedAt=DateTime.UtcNow,PropertyId= propertyId
};awaitsession.StoreAsync(serviceRequest);awaitsession.SaveChangesAsync();return $"Service request created ID `{serviceRequest.Id}` for your unit.";});
In this case, there isn’t really much to do here, but hopefully this conveys the kind of code this allows you to write.
Summary
The PropertySphere sample application and its Telegram bot are interesting, mostly because of everything that isn’t here. We have a bot that has a pretty complex set of behaviors, but there isn’t a lot of complexity for us to deal with.
This behavior is emergent from the capabilities we entrusted to the model, and the kind of capabilities we give it. At the same time, I’m not trusting the model, but verifying that what it does is always within the scope of the user’s capabilities.
Extending what we have here to allow additional capabilities is easy. Consider adding the ability to get invoices directly from the Telegram interface, a great exercise in extending what you can do with the sample app.
There is also the full video where I walk you through all aspects of the sample application, and as always, we’d love to talk to you on Discord or in our GitHub discussions.
In the previous post, I introduced the PropertySphere sample application (you can also watch the video introducing it here). In this post, I want to go over how we build a Telegram bot for this application, so Renters can communicate with the application, check their status, raise issues, and even pay their bills.
I’m using Telegram here because the process of creating a new bot is trivial, the API is really fun to work with, and it takes very little effort.
Compare that to something like WhatsApp, where just the process for creating a bot is a PITA.
Without further ado, let’s look at what the Telegram bot looks like:
There are a bunch of interesting things that you can see in the screenshot. We communicate with the bot on the other end using natural text. There aren't a lot of screens / options that you have to go through, it is just natural mannerism.
The process is pretty streamlined from the perspective of the user. What does that look like from the implementation perspective? A lot of the time, that kind of interface involves… big amount of complexity in the backend.
Here is what I usually think when I consider those demos:
In our example, we can implement all of this in about 250 lines of code. The magic behind it is the fact that we can rely on RavenDB’s AI Agents feature to do most of the heavy lifting for us.
Inside RavenDB, this is defined as follows:
For this post, however, we’ll look at how we actually built this AI-powered Telegram bot. The full code is here if you want to browse through it.
What model is used here?
It’s worth mentioning that I’m not using anything fancy, the agent is using baseline gpt-4.1-mini for the demo. There is no need for training or customization, the way we create the agent already takes care of that.
Here is the overall agent definition:
store.AI.CreateAgent(newAiAgentConfiguration{Name="Property Assistant",Identifier="property-agent",ConnectionStringName="Property Management AI Model",SystemPrompt="""
You are a property management assistant for renters.
... redacted ...
Do NOT discuss non-property topics.
""",Parameters=[// Visible to the model:newAiAgentParameter("currentDate","Current date in yyyy-MM-dd format"),// Agent scope only, not visible to the model directlynewAiAgentParameter("renterId","Renter ID; answer only for this renter", sendToModel:false),newAiAgentParameter("renterUnits","List of unit IDs occupied by the renter", sendToModel:false),],SampleObject=JsonConvert.SerializeObject(newReply{Answer="Detailed answer to query (markdown syntax)",Followups=["Likely follow-ups"],}),// redacted});
The code above will create an agent with the given prompt. It turns out that a lot of work actually goes into that prompt to explain to the AI model exactly what its role is, what it is meant to do, etc.
I reproduced the entire prompt below so you can read it more easily, but take into account that you’ll likely tweak it a lot, and that it is usually much longer than what we have here (although what we have below is quite functional, as you can see from the screenshots).
The agent’s prompt
You are a property management assistant for renters.
Provide information about rent, utilities, debts, service requests, and property details.
Be professional, helpful, and responsive to renters’ needs.
You can answer in Markdown format. Make sure to use ticks (`) whenever you discuss identifiers.
Do not suggest actions that are not explicitly allowed by the tools available to you.
Do NOT discuss non-property topics. Answer only for the current renter.
When discussing amounts, always format them as currency with 2 decimal places.
The way RavenDB deals with AI Agents, we define two very important aspects of them. First, we have the parameters, which define the scope of the system. In this case, you can see that we pass the currentDate, as well as provide the renterId and renterUnits that this agent is going to deal with.
We expose the current date to the model, but not the renter ID or the units that define the scope (we’ll touch on that in a bit). The model needs the current date so it will understand when it is running and have context for things like “last month”. But we don’t need to give it the IDs, they have no meaning and are instead used to define the scope of a particular conversation with the model.
The sample object we use defines the structure of the reply that we require the model to give us. In this case, we want to get a textual message from the model in Markdown format, as well as a separate array of likely follow-ups that we can provide to the user.
In order to do its job, the agent needs to be able to access the system. RavenDB handles that by letting you define queries that the model can ask the agent to execute when it needs more information. Here are some of them:
Queries=[newAiAgentToolQuery{Name="GetRenterInfo",Description="Retrieve renter profile details",Query="from Renters where id() = $renterId",ParametersSampleObject="{}",Options=newAiAgentToolQueryOptions{AllowModelQueries=false,AddToInitialContext=true}},newAiAgentToolQuery{Name="GetOutstandingDebts",Description="Retrieve renter's outstanding debts (unpaid balances)",Query="""
from index 'DebtItems/Outstanding'
where RenterIds in ($renterId) and AmountOutstanding > 0
order by DueDate asc
limit 10
""",ParametersSampleObject="{}"},newAiAgentToolQuery{Name="GetUtilityUsage",Description="""
Retrieve utility usage for renter's unit within a date
range (for calculating bills)
""",Query="""
from 'Units'
where id() in ($renterUnits)
select
timeseries(from 'Power'
between $startDate and $endDate
group by 1d
select sum()),
timeseries(from 'Water'
between $startDate and $endDate
group by 1d
select sum())
""",ParametersSampleObject="""
{
"startDate": "yyyy-MM-dd",
"endDate": "yyyy-MM-dd"
}
"""},}]
The first query in the previous snippet, GetRenterInfo, is interesting. You can see that it is marked as: AllowModelQueries = false, AddToInitialContext = true. What does that mean?
It means that as part of creating a new conversation with the model, we are going to run the query to get all the renter’s details and add that to the initial context we send to the model. That allows us to provide the model with the information it will likely need upfront.
Note that we use the $renterId and $renterUnits parameters in the queries. While they aren’t exposed directly to the model, they affect what information the model can see. This is a good thing, since it means we place guardrails very early on. The model simply cannot see any information that is out of scope for it.
The model can ask for additional information when it needs to…
An important observation about the design of AI agents with RavenDB: note that we provided the model with a bunch of potential queries that it can run. GetRenterInfo is run at the beginning, since it gives us the initial context, but the rest are left for the judgment of the model.
The model can decide what queries it needs to run in order to answer the user’s questions, and it does so of its own accord. This decision means that once you have defined the set of queries and operations that the model can run, you are mostly done. The AI is smart enough to figure out what to do and then act according to your data.
Here is an example of what this looks like from the backend:
Here you can see that the user asked about their utilities, the model then ran the appropriate query and formulated an answer for the user.
The follow-ups UX pattern
You might have noticed that we asked the model for follow-up questions that the user may want to ask. This is a hidden way to guide the user toward the set of operations that the model supports.
The model will generate the follow-ups based on its own capabilities (queries and actions that it knows it can run), so this is a pretty simple way to “tell” that to the user without being obnoxious about it.
Let’s look at how things work when we actually use this to build the bot, then come back to the rest of the agent’s definition.
Plugging the model into Telegram
We looked at the agent’s definition so far - let’s see how we actually use that. The Telegram’s API is really nice, basically boiling down to:
And then the Telegram API will call the HandleUpdateAsync method when there is a new message to the bot. Note that you may actually get multiple (concurrent messages), maybe from different chats, at the same time.
We’ll focus on the process message function, where we start by checking exactly who we are talking to:
async Task ProcessMessageAsync(ITelegramBotClient botClient,
string chatId, string messageText, CancellationToken cancellationToken){
using var session = _documentStore.OpenAsyncSession();var renter =await session.Query<Renter>().FirstOrDefaultAsync(r=> r.TelegramChatId == chatId,
cancellationToken);if(renter ==null){await botClient.SendMessage(chatId,"Sorry, your Telegram account is not linked to a renter profile.",cancellationToken: cancellationToken
);return;}var conversationId = $"chats/{chatId}/{DateTime.Today:yyyy-MM-dd}";// more code in the next snippet}
Telegram uses the term chat ID in their API, but it is what I would call the renter’s ID. When we register renters, we also record their Telegram chat ID, which means that when we get a message from a user, we can check whether they are a valid renter in our system. If not, we fail early and are done.
If they are, this is where things start to get interesting. Look at the conversation ID that we generated in the last line. RavenDB uses the notion of a conversation with the agent to hold state. The conversation we create here means that the bot will use the same conversation with the user for the same day.
Another way to do that would be to keep the same conversation ID open for the same user. Since RavenDB will automatically handle summarizing and trimming the conversation, either option is fine and mostly depends on your scenario.
The next stage is to create the actual conversation. To do that, we need to provide the model with the right context it is looking for:
var renterUnits = await session.Query<Lease>()
.Where(l => l.RenterIds.Contains(renter.Id!))
.Select(l => l.UnitId)
.ToListAsync(cts);
var conversation = _documentStore.AI.Conversation("property-agent",
conversationId,
new AiConversationCreationOptions
{
Parameters = new Dictionary<string, object?>{["renterId"]= renter.Id,
["renterUnits"]= renterUnits,
["currentDate"]= DateTime.Today.ToString("yyyy-MM-dd")}});
You can see that we pass the renter ID and the relevant units for the renter to the model. Those form the creation parameters for the conversation and cannot be changed. That is one of the reasons why you may want to have a different conversation per day, to get the updated values if they changed.
With that done, we can send the results back to the model and then to the user, like so:
var result =awaitconversation.RunAsync<PropertyAgent.Reply>(cts);var replyMarkup =newReplyKeyboardMarkup(result.Answer.Followups
.Select(text =>newKeyboardButton(text)).ToArray()){ResizeKeyboard=true,OneTimeKeyboard=true};awaitbotClient.SendMessage(
chatId,result.Answer.Answer,
replyMarkup: replyMarkup,
cancellationToken: cts);
The RunAsync() method handles the entire interaction with the model, and most of the code is just dealing with the reply markup for Telegram.
If you look closely at the chat screenshot above, you can see that we aren’t just asking the model questions, we get the bot to perform actions. For example, paying the rent. Here is what this looks like:
How does this work?
Paying the rent through the bot
When we looked at the agent, we saw that we exposed some queries that the agent can run. But that isn’t the complete picture, we also give the model the ability to run actions. Here is what this looks like from the agent’s definition side:
Actions=[newAiAgentToolAction{Name="ChargeCard",Description="""
Record a payment for one or more outstanding debts. The
renter can pay multiple debt items in a single transaction.
Can pay using any stored card on file.
""",ParametersSampleObject=JsonConvert.SerializeObject(newChargeCardArgs{DebtItemIds=["debtitems/1-A","debtitems/2-A"],PaymentMethod="Card",Card="Last 4 digits of the card"})}]
The idea here is that we expose to the model the kinds of actions it can request, and we specify what parameters it should pass to them, etc. What we are not doing here is giving the model control over actually running any code or modifying any data.
Instead, when the model needs to charge a card, it will have to call your code and go through validation, business logic, and authorization. Here is what this looks like on the other side. When we create a conversation, we specify handlers for all the actions we need to take, like so:
conversation.Handle<PropertyAgent.ChargeCardArgs>("ChargeCard",asyncargs=>{
using var paySession = _documentStore.OpenAsyncSession();var renterWithCard =await paySession.LoadAsync<Renter>(renter.Id!, cts);var card = renterWithCard?.CreditCards
.FirstOrDefault(c=> c.Last4Digits == args.Card);if(card ==null){thrownewInvalidOperationException(
$"Card ending in {args.Card} not found in your profile.");}var totalPaid =await PaymentService.CreatePaymentForDebtsWithCardAsync(
paySession,
renter.Id!,
args.DebtItemIds,
card,
args.PaymentMethod,
cts);return $"Charged {totalPaid:C2} to {card.Type}"+
$" ending in {card.Last4Digits}.";});
Note that we do some basic validation, then we call the CreatePaymentForDebtsWithCardAsync()method to perform the actual operation. It is also fun that we can just return a message string to give the model an idea about what the result of the action is.
Inside CreatePaymentForDebtsWithCardAsync(),we also verify that the debts we are asked to pay are associated with the current renter; we may have to apply additional logic, etc. The concept is that we assume the model is not to be trusted, so we need to carefully validate the input and use our code to verify that everything is fine.
Summary
This post has gone on for quite a while, so I think we’ll stop here. As a reminder, the PropertySphere sample application code is available. And if you are one of those who prefer videos to text, you can watch the video here.
In the next post, I’m going to show you how we can make the bot even smarter by adding visual recognition to the mix.
This post introduces the PropertySphere sample application. I’m going to talk about some aspects of the sample application in this post, then in the next one, we will introduce AI into the mix.
This is based on a real-world scenario from a customer. One of the nicest things about AI being so easy to use is that I can generate throwaway code for a conversation with a customer that is actually a full-blown application.
Here is the application dashboard, so you can get some idea about what this is all about:
The idea is that you have Properties (apartment buildings), which have Units (apartments), which you then Lease to Renters. Note the capitalized words in the last sentence, those are the key domain entities that we work with.
Note that this dashboard shows quite a lot of data from many different places in the system. The map defines which properties we are looking at. It’s not just a static map, it is interactive. You can zoom in on a region to apply a spatial filter to the data in the dashboard.
Let’s take a closer look at what we are doing here. I’m primarily a backend guy, so I’m ignoring what the front end is doing to focus on the actual behavior of the system.
Here is what a typical endpoint will return for the dashboard:
We use a static index (we’ll see exactly why in a bit) to query for all the service requests by status and location, and then we project data from the document, including related document properties (the last two lines in the Select call).
A ServiceRequest doesn’t have a location, it gets that from its associated Property, so during indexing, we pull that from the relevant Property, like so:
Map= requests =>
from sr in requests
let property =LoadDocument<Property>(sr.PropertyId)
select newResult{Id=sr.Id,Status=sr.Status,OpenedAt=sr.OpenedAt,UnitId=sr.UnitId,PropertyId=sr.PropertyId,Type=sr.Type,Description=sr.Description,Location=CreateSpatialField(property.Latitude,property.Longitude),};
You can see how we load the related Property and then index its location for the spatial query (last line).
You can see more interesting features when you drill down to the Unit page, where both its current status and its utility usage are displayed. That is handled using RavenDB’s time series feature, and then projected to a nice view on the frontend:
In the backend, this is handled using the following action call:
[HttpGet("unit/{*unitId}")]
public IActionResultGetUtilityUsage(string unitId,[FromQuery]DateTime? from,[FromQuery]DateTime? to){var unit = _session.Load<Unit>(unitId);if(unit ==null)returnNotFound("Unit not found");var fromDate = from ??DateTime.Today.AddMonths(-3);var toDate = to ??DateTime.Today;var result = _session.Query<Unit>().Where(u =>u.Id== unitId).Select(u =>new{PowerUsage=RavenQuery.TimeSeries(u,"Power").Where(ts =>ts.Timestamp>= fromDate &&ts.Timestamp<= toDate).GroupBy(g =>g.Hours(1)).Select(g =>g.Sum()).ToList(),WaterUsage=RavenQuery.TimeSeries(u,"Water").Where(ts =>ts.Timestamp>= fromDate &&ts.Timestamp<= toDate).GroupBy(g =>g.Hours(1)).Select(g =>g.Sum()).ToList()}).FirstOrDefault();returnOk(new{UnitId= unitId,UnitNumber=unit.UnitNumber,From= fromDate,To= toDate,PowerUsage= result?.PowerUsage?.Results?.Select(r =>newUsageDataPoint{Timestamp=r.From,Value=r.Sum[0],}).ToList()??newList<UsageDataPoint>(),WaterUsage= result?.WaterUsage?.Results?.Select(r =>newUsageDataPoint{Timestamp=r.From,Value=r.Sum[0],}).ToList()??newList<UsageDataPoint>()});
As you can see, we run a single query to fetch data from multiple time series, which allows us to render this page.
By now, I think you have a pretty good grasp of what the application is about. So get ready for the next post, where I will talk about how to add AI capabilities to the mix.
We are a database company, and many of our customers and users are running in the cloud. Fairly often, we field questions about the recommended deployment pattern for RavenDB.
Given the… rich landscape of DevOps options, RavenDB supports all sorts of deployment models:
Embedded in your application
Physical hardware (from a Raspberry Pi to massive servers)
Virtual machines in the cloud
Docker
AWS / Azure marketplaces
Kubernetes
Ansible
Terraform
As well as some pretty fancy permutations of the above in every shape and form.
With so many choices, the question is: what do you recommend? In particular, we were recently asked about deployment to a “naked machine” in the cloud versus using Kubernetes. The core requirements are to ensure high performance and high availability.
Our short answer is almost always: Best to go with direct VMs and skip Kubernetes for RavenDB.
While Kubernetes has revolutionized the deployment of stateless microservices, deploying stateful applications, particularly databases, on K8s introduces significant complexities that often outweigh the benefits, especially when performance and operational simplicity are paramount.
A great quote in the DevOps world is “cattle, not pets”, in reference to how you should manage your servers. That works great if you are dealing with stateless services. But when it comes to data management, your databases are cherished pets, and you should treat them as such.
The Operational Complexity of Kubernetes for Stateful Systems
Using an orchestration layer like Kubernetes complicates the operational management of persistent state. While K8s provides tools for stateful workloads, they require a deep understanding of storage classes, Persistent Volumes (PVs), and Persistent Volume Claims (PVCs).
Consider a common, simple maintenance task: Changing a VM's disk type or size.
As a VM, this is typically a very easy operation and can be done with no downtime.The process is straightforward, well-documented, and often takes minutes.
For K8s, this becomes a significantly more complex task. You have to go deep into Kubernetes storage primitives to figure out how to properly migrate the data to a new disk specification.
There is an allowVolumeExpansion: true option that should make it work, but the details matter, and for databases, that is usually something DBAs are really careful about.
Databases tend to care about their disk. So what happens if we don’t want to just change the size of the disk, but also its type? Such as moving from Standard to Premium. Doing that using VMs is as simple as changing the size. You may need to detach, change, and reattach the disk, but that is a well-trodden path.
In Kubernetes, you need to run a migration, delete the StatefulSets, make the configuration change, and reapply (crossing your fingers and hoping everything works).
Database nodes are not homogeneous
Databases running in a cluster configuration often require granular control over node upgrades and maintenance. I may want to designate a node as “this one is doing backups”, so it needs a bigger disk. Easy to do if each node is a dedicated VM, but much harder in practice inside K8s.
A recent example we ran into is controlling the upgrade process of a cluster. As any database administrator can tell you, upgrades are something you approach cautiously. RavenDB has great support for running cross-version clusters.
In other words, take a node in your cluster, upgrade that to an updated version (including across major versions!), and it will just work. That allows you to dip your toes into the waters with a single node, instead of doing a hard switch to the new version.
In a VM environment: Upgrading a single node in a RavenDB cluster is a simple, controlled process. You stop the database on the VM, perform the upgrade (often just replacing binaries), start the database, and allow the cluster to heal and synchronize. This allows you to manage the cluster's rolling upgrades with precision.
In K8s: Performing a targeted upgrade on just one node of the cluster is hard. The K8s deployment model (StatefulSets) is designed to manage homogeneous replicas. While you can use features like "on delete" update strategy, blue/green deployments, or canary releases, they add layers of abstraction and complexity that are necessary for stateless services but actively harmful for stateful systems.
Summary
For mission-critical database infrastructure where high performance, high availability, and operational simplicity are non-negotiable, the added layer of abstraction introduced by Kubernetes for managing persistence often introduces more friction than value.
While Kubernetes is an excellent platform for stateless services, we strongly recommend deploying RavenDB directly on dedicated Virtual Machines. This provides a cleaner operational surface, simpler maintenance procedures, and more direct control over the underlying resources—all critical factors for a stateful, high-performance database cluster.
Remember, your database nodes are cherished pets, don’t make them sleep in the barn with the cattle.
programmers have a dumb chip on their shoulder that makes them try and emulate traditional engineering there is zero physical cost to iteration in software - can delete and start over, can live patch our approach should look a lot different than people who build bridges
I have to say that I would strongly disagree with this statement. Using the building example, it is obvious that moving a window in an already built house is expensive. Obviously, it is going to be cheaper to move this window during the planning phase.
The answer is that it may be cheaper, but it won’t necessarily be cheap. Let’s say that I want to move the window by 50 cm to the right. Would it be up to code? Is there any wiring that needs to be moved? Do I need to consider the placement of the air conditioning unit? What about the emergency escape? Any structural impact?
This is when we are at the blueprint stage - the equivalent of editing code on screen. And it is obvious that such changes can be really expensive. Similarly, in software, every modification demands a careful assessment of the existing system, long-term maintenance, compatibility with other components, and user expectations.This intricate balancing act is at the core of the engineering discipline.
A civil engineer designing a bridge faces tangible constraints: the physical world, regulations, budget limitations, and environmental factors like wind, weather, and earthquakes.While software designers might not grapple with physical forces, they contend with equally critical elements such as disk usage, data distribution, rules & regulations, system usability, operational procedures, and the impact of expected future changes.
Evolving an existing software system presents a substantial engineering challenge.Making significant modifications without causing the system to collapse requires careful planning and execution.The notion that one can simply "start over" or "live deploy" changes is incredibly risky.History is replete with examples of major worldwide outages stemming from seemingly simple configuration changes.A notable instance is the Google outage of June 2025, where a simple missing null check brought down significant portions of GCP. Even small alterations can have cascading and catastrophic effects.
I’m currently working on a codebase whose age is near the legal drinking age. It also has close to 1.5 million lines of code and a big team operating on it. Being able to successfully run, maintain, and extend that over time requires discipline.
In such a project, you face issues such as different versions of the software deployed in the field, backward compatibility concerns, etc. For example, I may have a better idea of how to structure the data to make a particular scenario more efficient. That would require updating the on-disk data, which is a 100% engineering challenge. We have to take into consideration physical constraints (updating a multi-TB dataset without downtime is a tough challenge).
The moment you are actually deployed, you have so many additional concerns to deal with. A good example of this may be that users are used to stuff working in a certain way. But even for software that hasn’t been deployed to production yet, the cost of change is high.
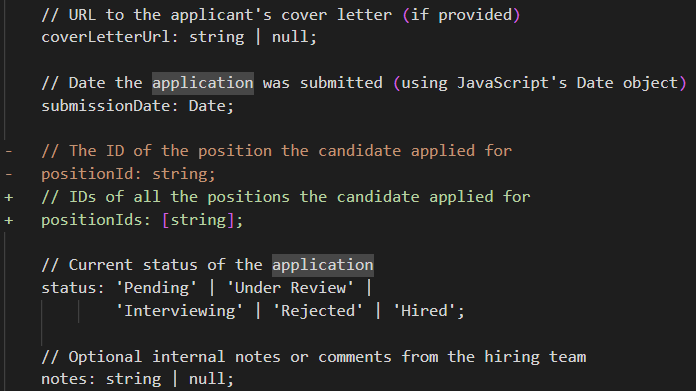
Consider the effort associated with this update to a JobApplication class:
This looks like a simple change, right? It just requires that you (partial list):
Set up database migration for the new shape of the data.
Migrate the existing data to the new format.
Update any indexes and queries on the position.
Update any endpoints and decide how to deal with backward compatibility.
Create a new user interface to match this whenever we create/edit/view the job application.
Consider any existing workflows that inherently assume that a job application is for a single position.
Can you be partially rejected? What is your status if you interviewed for one position but received an offer for another?
How does this affect the reports & dashboard?
This is a simple change, no? Just a few characters on the screen. No physical cost. But it is also a full-blown Epic Task for the project - even if we aren’t in production, have no data to migrate, or integrations to deal with.
Software engineersoperate under constraints similar to other engineers, including severe consequences for mistakes (global system failure because of a missing null check). Making changes to large, established codebases presents a significant hurdle.
The moment that you need to consider more than a single factor, whether in your code or in a bridge blueprint, there is a pretty high cost to iterations. Going back to the bridge example, the architect may have a rough idea (is it going to be a Roman-style arch bridge or a suspension bridge) and have a lot of freedom to play with various options at the start. But the moment you begin to nail things down and fill in the details, the cost of change escalates quickly.
Finally, just to be clear, I don’t think that the cost of changing software is equivalent to changing a bridge after it was built. I simply very strongly disagree that there is zero cost (or indeed, even low cost) to changing software once you are past the “rough draft” stage.