




time to read 1 min | 45 words
Take a look at this method:
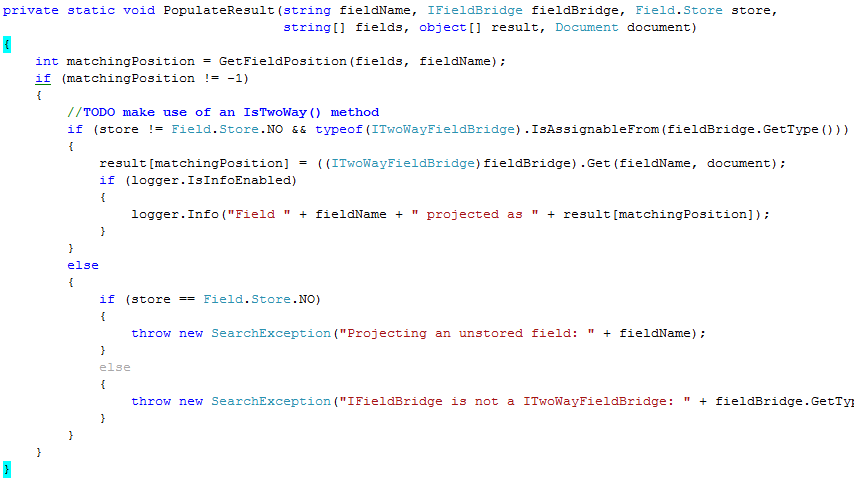
Now, let us make this simple, shall we?

Same meaning, and a significant reduction of complexity. Damn, but this is annoying.

Take a look at this method:
Now, let us make this simple, shall we?
Same meaning, and a significant reduction of complexity. Damn, but this is annoying.
I am going over a code base that I haven't seen in a while, and I am familiarizing myself with it by doing a code review to see that I understand what the code is doing now.
I am going to post code samples of changes that I made, along with some explanations.

This code can be improved by introducing a guard clause, like this:

This reduce nesting and make the code easier to read in the long run (no nesting).

I hope you recognize the issue. The code is using reflection to do an operation that is already built into the CLR.
This is much better:

Of course, there is another issue here, why the hell do we have those if statement on type instead of pushing this into polymorphic behavior. No answer yet, I am current just doing blind code review.
Here is another issue, using List explicitly:

It is generally better to rely on the most abstract type that you can use:

This is a matter of style more than anything else, but it drives me crazy:

I much rather have this:

Note that I added braces for both clauses, because it also bother me if one has it and the other doesn't.
Another issue is hanging ifs:

Which we can rewrite as:

I think that this is enough for now...
Java Enums are much more powerful than the ones that exists in the CLR. There are numerous ways of handling this issue, but here is my approach.
Given this enum (defined in Java):
private static enum Layer { FIRST, SECOND; public boolean isRightLayer(WorkType type) { if (this == FIRST && type != WorkType.COLLECTION) return true; return this == SECOND && type == WorkType.COLLECTION; } }
And the C# version is:
private class Layer { public static readonly Layer First = new Layer(delegate(WorkType type) { return type != WorkType.Collection; }); public static readonly Layer Second = new Layer(delegate(WorkType type) { return type == WorkType.Collection; }); public delegate bool IsRightLayerDelegate(WorkType type); private readonly IsRightLayerDelegate isRightLayer; protected Layer(IsRightLayerDelegate isRightLayer) { this.isRightLayer = isRightLayer; } public bool IsRightLayer(WorkType type) { return isRightLayer(type); } }
No, I am not going to bore you with another repetition of the news. Yeah, Microsoft is going to bundle jQuery with Visual Studio and the ASP.Net MVC. That is important, but not quite as important as something else that I didn't see other people pointing out.
This is the first time in a long time that I have seen Microsoft incorporating an Open Source project into their product line.
I am both thrilled and shocked.

Don't get used to the deluge of the screen casts, I usually do them with months apart, not a mere day.
At any rate, this screen cast is another significant diversion from my usual style.
To start with, it is a zero code webcast, and it would probably would well as a podcast, although I think that the artwork and presentation is still important.
Anyway, this webcast is focused on several lessons learned from unsuccessful project, what are the kind of things that we should pay attention to, and how we can avoid them.
It runs just under 40 minutes, and it is pretty intense.
As I said, this is a new approach for me, and I would like to get your feedback on the matter.
You can download it at the bottom of this page: http://ayende.com/hibernating-rhinos.aspx
Well, I spent almost two hours yesterday just getting things organized for the coming couple of months. It was only when I actually sat down to start making reservations that I figure out what I had set myself up to.
2nd Oct - 16th Oct - London, there is a ALT.Net beer night on the 14th that I am looking forward too.
27th Oct - 29th Oct - Dallas.
30th Oct - 2nd Nov - Austin for the ALT.Net conference there.
2nd Nov - 15th Nov - New Jersey.
16th Nov - 22th Nov - Sweden, for Ørdev.
Oh, and there is DevTeach as well at the beginning of December, but I am not thinking that far ahead.

It has been a while since I last published a screen cast, but here is a new one.
This one is in a slightly different style. I decided to follow Rob Conery's method of using a lot of prepared code instead of my usual ad hoc programming.
Please let me know what you think about the different style.
This is a far more condensed episode, lasting just under half an hour, and it is focus primarily on the internal architecture of a real world application.
I tried to go over a lot of the concepts that seems to trip people up when they come to define the structure of the application.
The technical details:
You can download this from this address: http://ayende.com/hibernating-rhinos.aspx
Here it the table of content:
The chapter starts with...
Documentation is a task that most developers strongly dislike. It is treated as a tedious, annoying task and often falls on the developer who protests the least. One additional problem is that a developer trying to document his own work is often not going to do a good work.
This is not an aspiration against developers in general; the problem is that there are too many things that people who actually write the code takes for granted. And even in we ignore that, developers tend to write to developers, in a way that makes little sense to non developers.
That is true for me as well. And trying to document how developers should write documentation is... hard.
At least I can look forward for a really interesting Chapter 12.
The Managed Extensibility Framework is "new library in .NET that enables greater reuse of applications and components. Using MEF, .NET applications can make the shift from being statically compiled to dynamically composed. If you are building extensible applications, extensible frameworks and application extensions, then MEF is for you."
(I was too lazy to think about my own description for it, so I just copied the official one.)
Probably the first thing that you should know about MEF is what will undoubtedly be the most common cause for confusion.
The Managed Extensibility Framework is not an IoC container.
 This is not a slug at MEF, it is an important distinction. If you try to judge MEF through IoC container glasses, you will come away confused. It may walk like a duck, but it meows.
This is not a slug at MEF, it is an important distinction. If you try to judge MEF through IoC container glasses, you will come away confused. It may walk like a duck, but it meows.
MEF is, first and foremost, a composition framework. And its target audience are BIG applications. Those two, taken together, are important to understand what MEF is and how we should look at it.
What is the difference between a composition framework and an IoC container? On the surface, they are doing much of the same thing, managing dependencies for the application in an automated fashion. The difference (and the devil) are in the details.
IoC containers have long ago stopped just managing dependencies. They are taking care of a lot of additional responsibilities. Managing lifecycles, proxies, aspect orientation, event aggregation, transaction semantics and a lot of other features.
In addition to that, there is a lot of focus on problem solving by utilizing the container. Things like generic specialization or component selectors allows you to approach a lot of very complex problems in a completely different mindset.
A composition framework, on the other hand, is focused on a single goal: dependency management.
It sounds like MEF is a subset of what an IoC container is doing, I know. This is not the case. MEF, the bits we have right now, are doing a lot more in the area of dependency management than the containers are doing. Where a container is usually static and opaque, MEF primary focus is to make the dependency management itself a dynamic and transparent process.
This is where the second part of the MEF design goals come into place. MEF is targeting Big applications. The really big ones. One of the immediate customers of MEF is Visual Studio itself.
Things like ( take a deep breath ):
All of those are key concepts in the overall dependency management theme. And all of those are the product of having a Visual Studio being one of the first consumers of this project. Visual Studio needs this kind of things, across tens of thousands of components. And MEF is setup to handle those kind of scenarios.
So, MEF is very similar to IoC containers, but it has very different goals (or maybe it would be more accurate to say that it has very different priorities).
Another important aspect of MEF has nothing to do with it at all and everything to do with where it is going to be used. MEF is going to ship with .Net 4.0, which put it in a position to be very widely distributed, but more importantly, since it is on the framework, it can be used by other parts of the framework. Which is where it get interesting.
There are a lot of places in the framework that could make use of a container. IControllerFactory is a good example of something that should not exists, for example. I am ambivalent with regards to that, because I think that the correct abstraction for those kind of things is not necessarily MEF, but that is beside the point.
And that is enough for now, I am going to toss a coin and see if it is going to be Erlang code or meta documentation next.
It is not public yet (but you can call and ask for it), but it will be when SP1 goes to Windows Update. This is the fix for the ExecutionEngineException that appeared in .Net 3.5 SP1, and was found by Rhino Mocks.
It took a while (but not unreasonably so), and it is here, yeah!
This is fixed, you can get the fix here: http://support.microsoft.com/?id=957541
No future posts left, oh my!