On Jun 11, 2025 I’m going to do a Big Reveal of RavenDB’s new Gen AI capabilities in a public webinar. RavenDB's new feature for automated decision-making, content classification, and data enrichment. We'll cover the behind-the-scenes mechanics and how RavenDB simplifies AI logistics, letting you focus on building your system. Discover how to build AI features without breaking the bank or your release schedule.
Yesterday I gave a live talk about some of the re-design we did to the internals of RavenDB’s storage engine (Voron). I think it went pretty well, and the record is here.
Tomorrow I’m going to be doing a Discord webinar about the deep optimizations we did in how RavenDB talks to the disk.
We are talking about some of the biggest changes to the internals in a decade or so, with the accompanying performance numbers to justify that. I had a great time preparing for that, and I’m really hoping to see you there.
Join Our Community Discussion: Exploring the Power of AI Search in Modern Applications
We're excited to announce our second Community Open Discussion, focusing on a transformative feature in today's applications: AI search.This technology is rapidly becoming the new standard for delivering intelligent and intuitive search experiences.
Join Dejan from our DevRel team for an open and engaging discussion.Whether you're eager to learn, contribute your insights, or simply listen in, everyone is welcome!
We’ll talk about:
The growing popularity and importance of AI search.
A deep dive into the technical aspects, including embeddings generation, query term caching, and quantization techniques.
An open forum to discuss best practices and various approaches to implementing AI search.
A live showcase demonstrating how RavenDB AI Integration allows you to implement AI Search in just 5 minutes, with the same simplicity as our regular search API.
Orleans is a distributed computing framework for .NET. It allows you to build distributed systems with ease, taking upon itself all the state management, persistence, distribution, and concurrency.
The core aspect in Orleans is the notion of a “grain” - a lightweight unit of computation & state. You can read more about it in Microsoft’s documentation, but I assume that if you are reading this post, you are already at least somewhat familiar with it.
You can use RavenDB to persist and retrieve Orleans grain states, store Orleans timers and reminders, as well as manage Orleans cluster membership.
RavenDB is well suited for this task because of its asynchronous nature, schema-less design, and the ability to automatically adjust itself to different loads on the fly.
If you are using Orleans, or even just considering it, give it a spin with RavenDB. We would love your feedback.
RavenDB is moving at quite a pace, and there is actually more stuff happening than I can find the time to talk about. I usually talk about the big-ticket items, but today I wanted to discuss some of what we like to call Quality of Life features.
The sort of things that help smooth the entire process of using RavenDB - the difference between something that works and something polished. That is something I truly care about, so with a great sense of pride, let me walk you through some of the nicest things that you probably wouldn’t even notice that we are doing for you.
RavenDB Node.js Client - v7.0 released (with Vector Search)
We updated the RavenDB Node.js client to version 7.0, with the biggest item being explicit support for vector search queries from Node.js. You can now write queries like these:
This is the famous example of using RavenDB’s vector search to find pizza and pasta in your product catalog, utilizing vector search and automatic data embeddings.
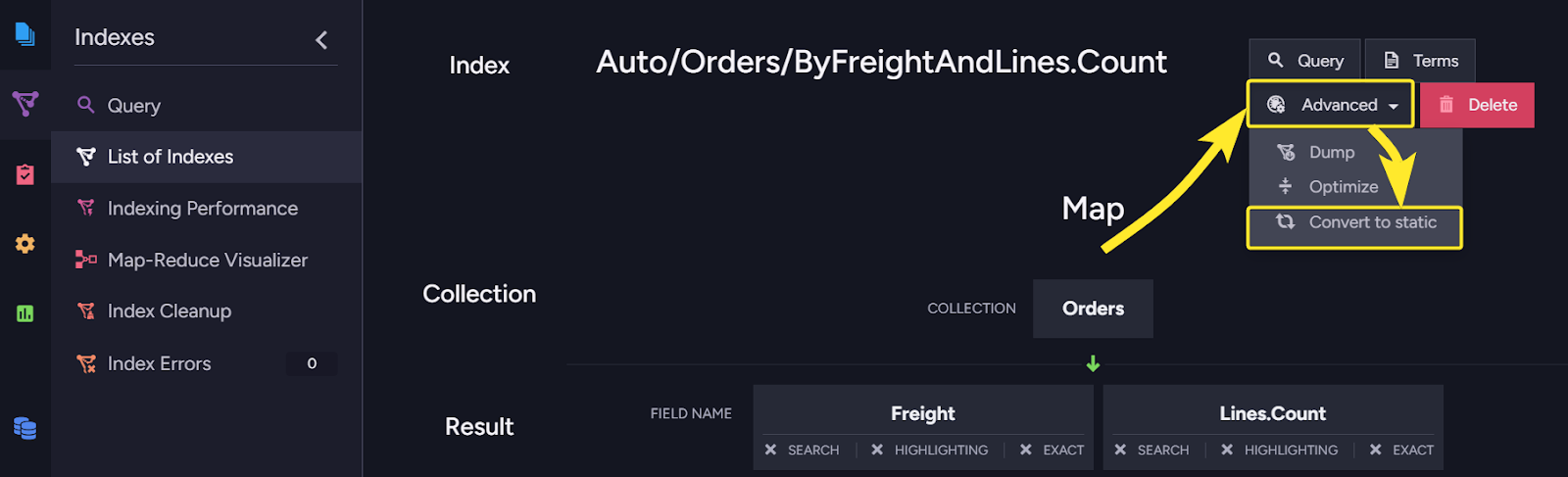
Converting automatic indexes to static indexes
RavenDB has auto indexes. Send a query, and if there is no existing index to run the query, the query optimizer will generate one for you. That works quite amazingly well, but sometimes you want to use this automatic index as the basis for a static (user-defined) index. Now you can do that directly from the RavenDB Studio, like so:
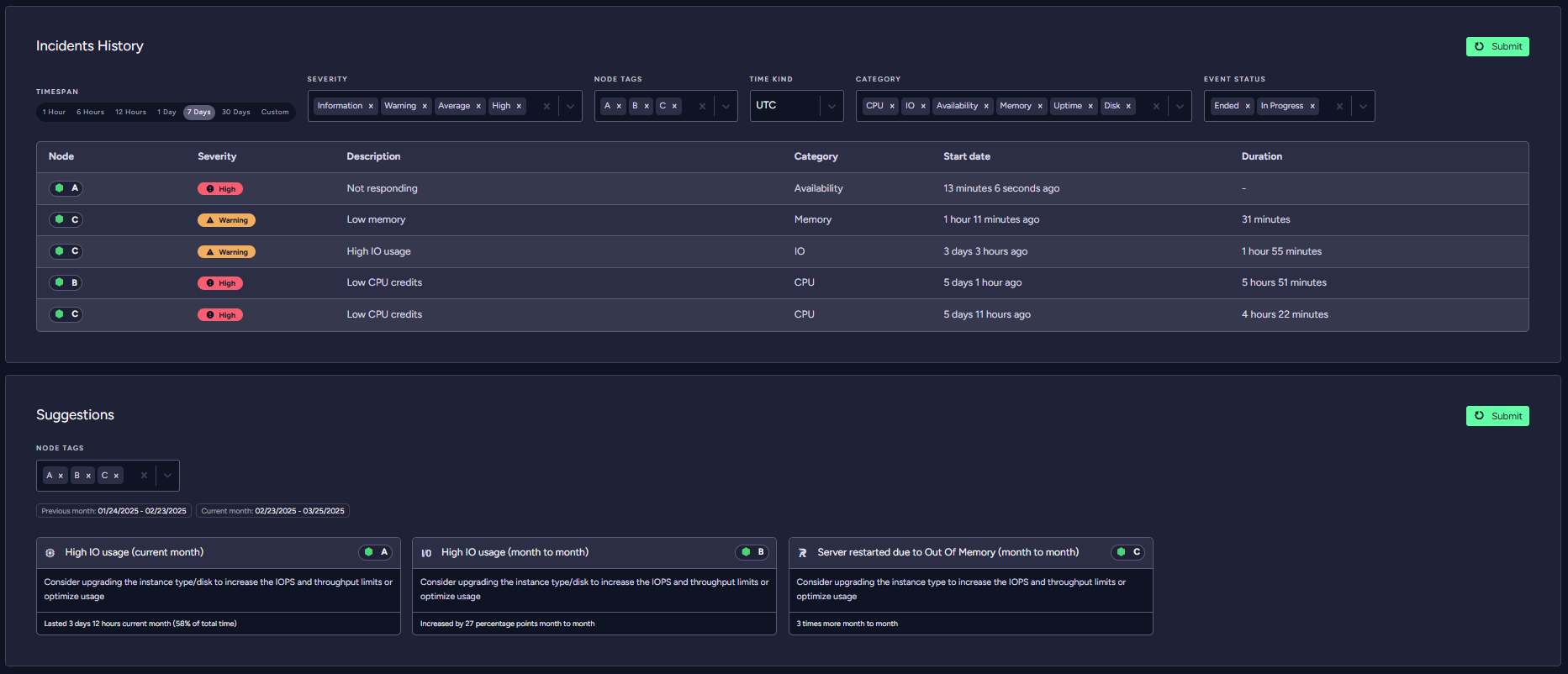
You can also see what happened to your system in the past, including things that RavenDB’s system automatically recovered from without you needing to lift a finger.
For example, take a look at this highly distressed system:
As usual, I would appreciate any feedback you have on the new features.
Last week I did an hour long webinar showing AI integration in RavenDB. From vector search to RAG, from embedding generation to Gen AI inside of the database engine.
Most of those features are already released, but I would really love your feedback on the Gen AI integration story (starts at around to 30 minutes mark in the video).
I was just reviewing a video we're about to publish, and I noticed something in the subtitles. It said, "Six qubits are used for..."
I got all excited thinking RavenDB was jumping into quantum computing. But nope, it turned out to be a transcription error. What was actually said was, "Six kilobytes are used for..."
To be fair, I listened to the recording a few times, and honestly, "qubits" isn't an unreasonable interpretation if you're just going by the spoken words. Even with context, that transcription isn't completely out there. I wouldn't be surprised if a human transcriber came up with the same result.
Fixing this issue (and going over an hour of text transcription to catch other possible errors) is going to be pretty expensive. Honestly, it would be easier to just skip the subtitles altogether in that case.
Here's the thing, though. I think a big part of this is that we now expect transcription to be done by a machine, and we don't expect it to be perfect. Before, when it was all done manually, it cost so much that it was reasonable to expect near-perfection.
What AI has done is make it cheap enough to get most of the value, while also lowering the expectation that it has to be flawless.
So, the choices we're looking at are:
AI transcription - mostly accurate, cheap, and easy to do.
Human transcription - highly accurate, expensive, and slow.
No transcription - users who want subtitles would need to use their own automatic transcription (which would probably be lower quality than what we use).
Before, we really only had two options: human transcription or nothing at all. What I think the spread of AI has done is not just made it possible to do it automatically and cheaply, but also made it acceptable that this "Good Enough" solution is actually, well, good enough.
Viewers know it's a machine translation, and they're more forgiving if there are some mistakes. That makes it way more practical to actually use it. And the end result? We can offer more content.
Sure, it's not as good as manual transcription, but it's definitely better than having no transcription at all (which is really the only other option).
What I find most interesting is that it's the fact that this is so common now that makes it possible to actually use it more.
Yes, we actually review the subtitles and fix any obvious mistakes for the video. The key here is that we can spend very little time actually doing that, since errors are more tolerated.