





RavenDB 7.1 introduces Gen AI Integration, enabling seamless integration of various AI models directly within your database. No, you aren’t going to re-provision all your database servers to run on GPU instances; we empower you to leverage any model—be it OpenAI, Mistral, Grok, or any open-source solution on your own hardware.
Our goal is to replicate the intuitive experience of copying data into tools like ChatGPT to ask a question. The idea is to give developers the same kind of experience with their RavenDB documents, and with the same level of complexity and hassle (i.e., none).
The key problem we want to solve is that while copy-pasting to ChatGPT is trivial, actually making use of an AI model in production presents significant logistical challenges. The new GenAI integration feature addresses these complexities. You can use AI models inside your database with the same ease and consistency you expect from a direct query.
The core tenet of RavenDB is that we take the complexity upon ourselves, leaving you with just the juicy bits to deal with. We bring the same type of mindset to Gen AI Integration.
Let’s explore exactly how you use this feature. Then I’ll dive into exactly how this works behind the scenes, and exactly how much load we are carrying for you.
Example: Automatic Product Translations
I’m using the sample database for RavenDB, which is a simple online shop (based on the venerable Northwind database). That database contains products such as these:
| Scottish Longbreads | Longlife Tofu | Flotemysost |
| Gudbrandsdalsost | Rhönbräu Klosterbier | Mozzarella di Giovanni |
| Outback Lager | Lakkalikööri | Röd Kaviar |
I don’t even know what “Rhönbräu Klosterbier” is, for example. I can throw that to an AI model and get a reply back: "Rhön Brewery Monastery Beer." Now at least I know what that is. I want to do the same for all the products in the database, but how can I do that?
We broke the process itself into several steps, which allow RavenDB to do some really nice things (see the technical deep dive later). But here is the overall concept in a single image. See the details afterward:

Here are the key concepts for the process:
- A context extraction script that applies to documents and extracts the relevant details to send to the model.
- The prompt that the model is working on (what it is tasked with).
- The JSON output schema, which allows us to work with the output in a programmatic fashion.
- And finally, the update script that applies the output of the model back to the document.
In the image above, I also included the extracted context and the model output, so you’ll have better insight into what is actually going on.
With all the prep work done, let’s dive directly into the details of making it work.
I’m using OpenAI here, but that is just an example, you can use any model you like (including those that run on your own hardware, of course).
We’ll start the process by defining which model to use. Go to AI Hub > AI Connection Strings and define a new connection string. You need to name the connection string, select OpenAI as the connector, and provide your API key. The next stage is to select the endpoint and the model. I’m using gpt-4o-mini here because it is fast, cheap, and provides pretty good results.
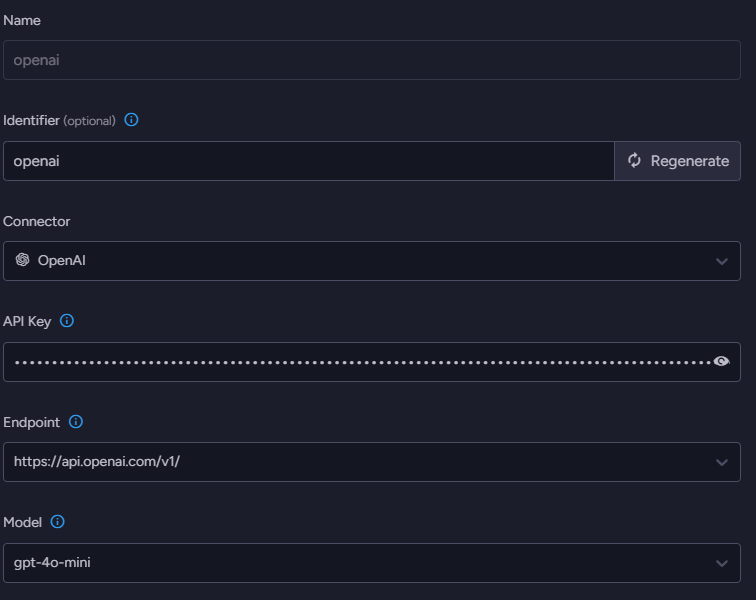
With the model selected, let’s get started. We need to go to AI Hub > AI Tasks > Add AI Task > Gen AI. This starts a wizard to guide you through the process of defining the task. The first thing to do is to name the task and select which connection string it will use. The real fun starts when you click Next.
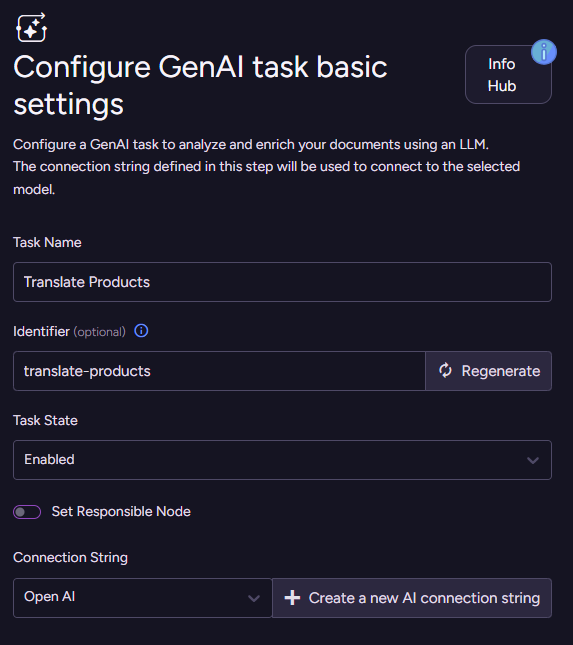
Defining the context
We need to select which collection we’ll operate on (Products) and define something called the Context generation script. What is that about? The idea here is that we don’t need to send the full document to the model to process - we just need to push the relevant information we want it to operate on. In the next stage, we’ll define what is the actual operation, but for now, let’s see how this works.
The context generation script lets you select exactly what will be sent to the model. The method ai.genContext generates a context object from the source document. This object will be passed as input to the model, along with a Prompt and a JSON schema defined later. In our case, it is really simple:
ai.genContext({
Name: this.Name
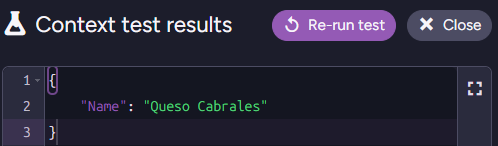
});Here is the context object that will be generated from a sample document:
Click Next and let’s move to the Model Input stage, where things really start to get interesting. Here we are telling the model what we want to do (using the Prompt), as well as telling it how it should reply to us (by defining the JSON Schema).
For our scenario, the prompt is pretty simple:
You are a professional translator for a product catalog.
Translate the provided fields accurately into the specified languages, ensuring clarity and cultural appropriateness.Note that in the prompt, we are not explicitly specifying which languages to translate to or which fields to process. We don’t need to - the fields the model will translate are provided in the context objects created by the "context generation script."
As for what languages to translate, we can specify that by telling the model what the shape of the output should be. We can do that using a JSON Schema or by providing a sample response object. I find it easier to use sample objects instead of writing JSON schemas, but both are supported. You’ll usually start with sample objects for rough direction (RavenDB will automatically generate a matching JSON schema from your sample object) and may want to shift to a JSON schema later if you want more control over the structure.
Here is one such sample response object:
{
"Name": {
"Simple-English": "Simplified English, avoid complex / rare words",
"Spanish": "Spanish translation",
"Japanese": "Japanese translation",
"Hebrew": "Hebrew translation"
}
}I find that it is more hygienic to separate the responsibilities of all the different pieces in this manner. This way, I can add a new language to be translated by updating the output schema without touching the prompt, for example.
The text content within the JSON object provides guidance to the model, specifying the intended data for each field.This functions similarly to the description field found in JSON Schema.
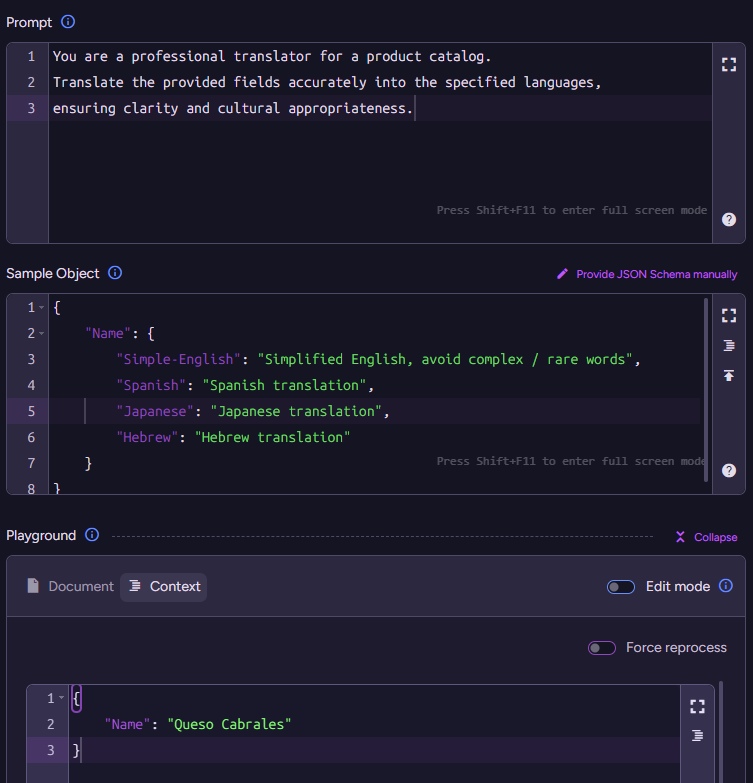
We have the prompt and the sample object, which together instruct the model on what to do. At the bottom, you can see the context object that was extracted from the document using the script. Putting it all together, we can send that to the model and get the following output:
{
"Name": {
"Simple-English": "Cabrales cheese",
"Spanish": "Queso Cabrales",
"Japanese": "カブラレスチーズ",
"Hebrew": "גבינת קברלס"
}
}The final step is to decide what we’ll do with the model output. This is where the Update Script comes into play.
this.i18n = $output;This completes the setup, and now RavenDB will start processing your documents based on this configuration. The end result is that your documents will look something like this:
{
"Name": "Queso Cabrales",
"i18n": {
"Name": {
"Simple-English": "Cabrales cheese",
"Spanish": "Queso Cabrales",
"Japanese": "カブラレスチーズ",
"Hebrew": "גבינת קברלס"
}
},
"PricePerUnit": 21,
"ReorderLevel": 30,
// rest of document redacted
}I find it hard to clearly explain what is going on here in text. This is the sort of thing that works much better in a video. Having said that, the basic idea is that we define a Gen AI task for RavenDB to execute. The task definition includes the following discrete steps: defining the connection string; defining the context generation script, which creates context objects; defining the prompt and schema; and finally, defining the document update script. And then we’re done.
The context objects, prompt, and schema serve as input to the model. The update script is executed for each output object received from the model, per context object.
From this point onward, it is RavenDB’s responsibility to communicate with the model and handle all the associated logistics. That means, of course, that if you want to go ahead and update the name of a product, RavenDB will automatically run the translation job in the background to get the updated value.
When you see this at play, it feels like absolute magic. I haven’t been this excited about a feature in a while.
Diving deep into how this works
A large language model is pretty amazing, but getting consistent and reliable results from it can be a chore. The idea behind Gen AI Integration in RavenDB is that we are going to take care of all of that for you.
Your role, when creating such Gen AI Tasks, is to provide us with the prompt, and we’ll do the rest. Well… almost. We need a bit of additional information here to do the task properly.
The prompt defines what you want the model to do. Because we aren’t showing the output to a human, but actually want to operate on it programmatically, we don’t want to get just raw text back. We use the Structured Output feature to define a JSON Schema that forces the model to give us the data in the format we want.
It turns out that you can pack a lot of information for the model about what you want to do using just those two aspects. The prompt and the output schema work together to tell the model what it should do for each document.
Controlling what we send from each document is the context generation script. We want to ensure that we aren’t sending irrelevant or sensitive data. Model costs are per token, and sending it data that it doesn’t need is costly and may affect the result in undesirable ways.
Finally, there is the update script, which takes the output from the model and updates the document. It is important to note that the update script shown above (which just stores the output of the model in a property on the document) is about the simplest one that you can have.
Update scripts are free to run any logic, such as marking a line item as not appropriate for sale because the customer is under 21. That means you don’t need to do everything through the model, you can ask the model to apply its logic, then process the output using a simple script (and in a predictable manner).
What happens inside?
Now that you have a firm grasp of how all the pieces fit together, let’s talk about what we do for you behind the scenes. You don’t need to know any of that, by the way. Those are all things that should be completely opaque to you, but it is useful to understand that you don’t have to worry about them.
Let’s talk about the issue of product translation - the example we have worked with so far. We define the Gen AI Task, and let it run. It processes all the products in the database, generating the right translations for them. And then what?
The key aspect of this feature is that this isn’t a one-time operation. This is an ongoing process. If you update the product’s name again, the Gen AI Task will re-translate it for you. It is actually quite fun to see this in action. I have spent <undisclosed> bit of time just playing around with it, modifying the data, and watching the updates streaming in.
That leads to an interesting observation: what happens if I update the product’s document, but not the name? Let’s say I changed the price, for example. RavenDB is smart about it, we only need to go to the model if the data in the extracted context was modified. In our current example, this means that only when the name of the product changes will we need to go back to the model.
How does RavenDB know when to go back to the model?
When you run the Gen AI Task, RavenDB stores a hash representing the work done by the task in the document’s metadata. If the document is modified, we can run the context generation script to determine whether we need to go to the model again or if nothing has changed from the previous time.
RavenDB takes into account the Prompt, JSON Schema, Update Script, and the generated context object when comparing to the previous version. A change to any of them indicates that we should go ask the model again. If there is no change, we simply skip all the work.
In this way, RavenDB takes care of detecting when you need to go to the model and when there is no need to do so. The key aspect is that you don’t need to do anything for this to work. It is just the way RavenDB works for you.
That may sound like a small thing, but it is actually quite profound. Here is why it matters:
- Going to the model is slow - it can take multiple seconds (and sometimes significantly longer) to actually get a reply from the model. By only asking the model when we know the data has changed, we are significantly improving overall performance.
- Going to the model is expensive - you’ll usually pay for the model by the number of tokens you consume. If you go to the model with an answer you already got, that’s simply burning money, there’s no point in doing that.
- As a user, that is something you don’t need to concern yourself with. You tell RavenDB what you want the model to do, what information from the document is relevant, and you are done.
You can see the entire flow of this process in the following chart:
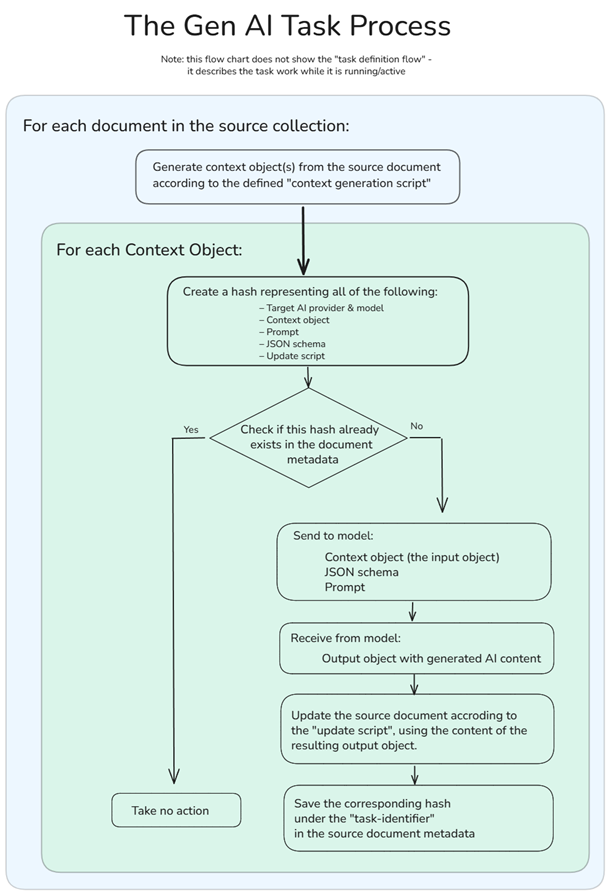
Let’s consider another aspect. You have a large product catalog and want to run this Gen AI Task. Unfortunately, AI models are slow (you may sense a theme here), and running each operation sequentially is going to take a long time. You can tell RavenDB to run this concurrently, and it will push as much as the AI model (and your account’s rate limits) allow.
Speaking of rate limits, that is sadly something that is quite easy to hit when working with realistic datasets (a few thousand requests per minute at the paid tier). If you need to process a lot of data, it is easy to hit those limits and fail. Dealing with them is also something that RavenDB takes care of for you. RavenDB will know how to properly wait, scale back, and ensure that you are using the full capacity at your disposal without any action on your part.
The key here is that we enable your data to think, and doing that directly in the database means you don’t need to reach for complex orchestrations or multi-month integration projects. You can do that in a day and reap the benefits immediately.
Applicable scenarios for Gen AI Integration in RavenDB
By now, I hope that you get the gist of what this feature is about. Now I want to try to blow your mind and explore what you can do with it…
Automatic translation is just the tip of the iceberg. I'm going to explore a few such scenarios, focusing primarily on what you’ll need to write to make it happen (prompt, etc.) and what this means for your applications.
Unstructured to structured data (Tagging & Classification)
Let’s say you are building a job board where companies and applicants can register positions and resumes. One of the key problems is that much of your input looks like this:
Date: May 28, 2025
Company: Example's Financial
Title: Senior Accountant
Location: Chicago
Join us as a Senior Accountant, where you will prepare financial statements, manage the general ledger, ensure compliance with tax regulations, conduct audits, and analyze budgets. We seek candidates with a Bachelor’s in Accounting, CPA preferred, 5+ years of experience, and proficiency in QuickBooks and Excel. Enjoy benefits including health, dental, and vision insurance, 401(k) match, and paid time off. The salary range is $80,000 - $100,000 annually. This is a hybrid role with 3 days on-site and 2 days remote.A simple prompt such as:
You are tasked with reading job applications and transforming them into structure data, following the provided output schema. Fill in additional details where it is relevant (state from city name, for example) but avoid making stuff up.
For requirements, responsibilities and benefits - use tag like format min-5-years, office, board-certified, etc.Giving the model the user-generated text, we’ll get something similar to this:
{
"location": {
"city": "Chicago",
"state": "Illinois",
"country": "USA",
"zipCode": ""
},
"requirements": [
"bachelors-accounting",
"cpa-preferred",
"min-5-years-experience",
"quickbooks-proficiency",
"excel-proficiency"
],
"responsibilities": [
"prepare-financial-statements",
"manage-general-ledger",
"ensure-tax-compliance",
"conduct-audits",
"analyze-budgets"
],
"salaryYearlyRange": {
"min": 80000,
"max": 100000,
"currency": "USD"
},
"benefits": [
"health-insurance",
"dental-insurance",
"vision-insurance",
"401k-match",
"paid-time-off",
"hybrid-work"
]
}You can then plug that into your system and have a much easier time making sense of what is going on.
In the same vein, but closer to what technical people are used to: imagine being able to read a support email from a customer and extract what version they are talking about, the likely area of effect, and who we should forward it to.
This is the sort of project you would have spent multiple months on previously. Gen AI Integration in RavenDB means that you can do that in an afternoon.
Using a large language model to make decisions in your system
For this scenario, we are building a help desk system and want to add some AI smarts to it. For example, we want to provide automatic escalation for support tickets that are high value, critical for the user, or show a high degree of customer frustration.
Here is an example of a JSON document showing what the overall structure of a support ticket might look like. We can provide this to the model along with the following prompt:
You are an AI tasked with evaluating a customer support ticket thread to determine if it requires escalation to an account executive.
Your goal is to analyze the thread, assess specific escalation triggers, and determine if an escalation is required.
Reasons to escalate:
* High value customer
* Critical issue, stopping the business
* User is showing agitataion / frustration / likely to leave usWe also ask the model to respond using the following structure:
{
"escalationRequired": false,
"escalationReason": "TechnicalComplexity | UrgentCustomerImpact | RecurringIssue | PolicyException",
"reason": "Details on why escalation was recommended"
}If you run this through the model, you’ll get a result like this:
{
"escalationRequired": true,
"escalationReason": "UrgentCustomerImpact",
"reason": "Customer reports critical CRM dashboard failure, impacting business operations, and expresses frustration with threat to switch providers."
}The idea here is that if the model says we should escalate, we can react to that. In this case, we create another document to represent this escalation. Other features can then use that to trigger a Kafka message to wake the on-call engineer, for example.
Note that now we have graduated from “simple” tasks such as translating text or extracting structured information to full-blown decisions, letting the model decide for us what we should do. You can extend that aspect by quite a bit in all sorts of interesting ways.
Security & Safety
A big part of utilizing AI today is understanding that you cannot fully rely on the model to be trustworthy. There are whole classes of attacks that can trick the model into doing a bunch of nasty things.
Any AI solution needs to be able to provide a clear story around the safety and security of your data and operations. For Gen AI Integration in RavenDB, we have taken the following steps to ensure your safety.
You control which model to use. You aren’t going to use a model that we run or control. You choose whether to use OpenAI, DeepSeek, or another provider. You can run on a local Ollama instance that is completely under your control, or talk to an industry-specific model that is under the supervision of your organization.
RavenDB works with all modern models, so you get to choose the best of the bunch for your needs.
You control which data goes out. When building Gen AI tasks, you select what data to send to the model using the context generation script. You can filter sensitive data or mask it. Preferably, you’ll send just the minimum amount of information that the model needs to complete its task.
You control what to do with the model’s output. RavenDB doesn’t do anything with the reply from the model. It hands it over to your code (the update script), which can make decisions and determine what should be done.
Summary
To conclude, this new feature makes it trivial to apply AI models in your systems, directly from the database. You don’t need to orchestrate complex processes and workflows - just let RavenDB do the hard work for you.
There are a number of scenarios where this can be extremely useful. From deciding whether a comment is spam or not, to translating data on the fly, to extracting structured data from free-form text, to… well, you tell me. My hope is that you have some ideas about ways that you can use these new options in your system.
I’m really excited that this is now available, and I can’t wait to see what people will do with the new capabilities.





