





reWhy Uber Engineering Switched from Postgres to MySQL
The Uber Engineering group have posted a really great blog post about their move from Postgres to MySQL. I mean that quite literally, it is a pleasure to read, especially since they went into such details as the on-disk format and the implications of that on their performance.
For fun, there is another great post from Uber, about moving from MySQL to Postgres, which also has interesting content.
Go ahead and read both, and we’ll talk when you are done. I want to compare their discussion to what we have been doing.
In general, Uber’s issue fall into several broad categories:
- Secondary indexes cost on write
- Replication format
- The page cache vs. buffer pool
- Connection handling
Secondary indexes
Postgres maintain a secondary index that points directly to the data on disk, while MySQL has a secondary index that has another level of indirection. The images show the difference quite clearly:
| Postgres | MySQL |
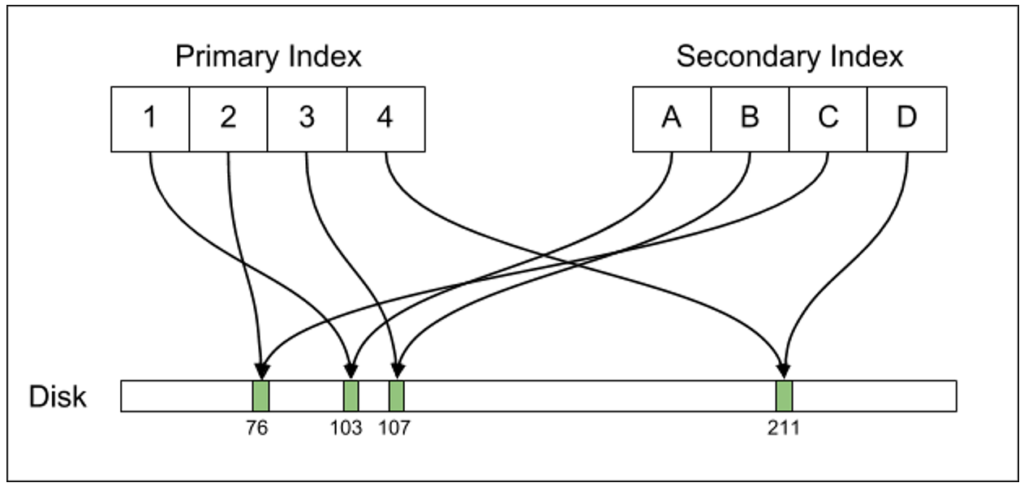 |
|
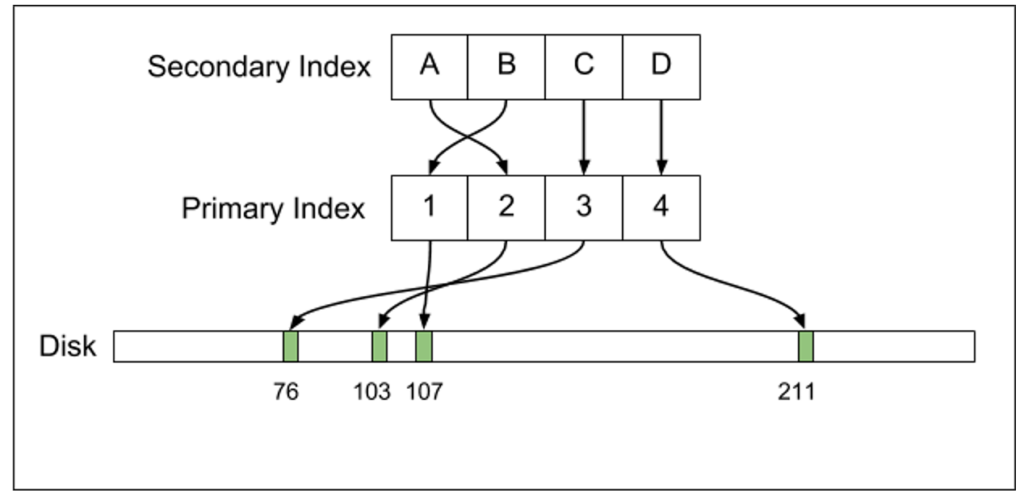
I have to admit that this is the first time that I ever considered the fact that the indirection’s manner might have any advantage. In most scenarios, it will turn any scan on a secondary index into an O(N * logN) cost, and that can really hurt performance. With Voron, we have actually moved in 4.0 from keeping the primary key in the secondary index to keeping the on disk position, because the performance benefit was so high.
That said, a lot of the pain the Uber is feeling has to do with the way Postgres has implemented MVCC. Because they write new records all the time, they need to update all indexes, all the time, and after a while, they will need to do more work to remove the old version(s) of the record. In contrast, with Voron we don’t need to move the record (unless its size changed), and all other indexes can remain unchanged. We do that by having a copy on write and a page translation table, so while we have multiple copies of the same record, they are all in the same “place”, logically, it is just the point of view that changes.
From my perspective, that was the simplest thing to implement, and we get to reap the benefit on multiple fronts because of this.
Replication format
Postgres send the WAL over the wire (simplified, but easier to explain) while MySQL send commands. When we had to choose how to implement over the wire replication with Voron, we also sent the WAL. It is simple to understand, extremely robust and we already had to write the code to do that. Doing replication using it also allows us to exercise this code routinely, instead of it only running during rare crash recovery.
However, sending the WAL has issues, because it modify the data on disk directly, and issue there can cause severe problems (data corruption, including taking down the whole database). It is also extremely sensitive to versioning issues, and it would be hard if not impossible to make sure that we can support multiple versions replicating to one another. It also means that any change to the on disk format needs to be considered with distributed versioning in mind.
But what killed it for us was the fact that it is almost impossible to handle the scenario of replacing the master server automatically. In order to handle that, you need to be able to deterministically let the old server know that it is demoted and should accept no writes, and the new server that it can now accept writes and send its WAL onward. But if there is a period of time in which both can accept write, then you can’t really merge the WAL, and trying to is going to be really hard. You can try using distributed consensus to run the WAL, but that is really expensive (about 400 writes / second in our benchmark, which is fine, but not great, and impose a high latency requirement).
So it is better to have a replication format that is more resilient to concurrent divergent work.
OS Page Cache vs Buffer Pool
From the post:
Postgres allows the kernel to automatically cache recently accessed disk data via the page cache. … The problem with this design is that accessing data via the page cache is actually somewhat expensive compared to accessing RSS memory. To look up data from disk, the Postgres process issues lseek(2) and read(2) system calls to locate the data. Each of these system calls incurs a context switch, which is more expensive than accessing data from main memory. … By comparison, the InnoDB storage engine implements its own LRU in something it calls the InnoDB buffer pool. This is logically similar to the Linux page cache but implemented in userspace. While significantly more complicated than Postgres’s design…
So Postgres is relying on the OS Page Cache, while InnoDB implements its own. But the problem isn’t with relying on the OS Page Cache, the problem is how you rely on it. And the way Postgres is doing that is by issuing (quite a lot, it seems) system calls to read the memory. And yes, that would be expensive.
On the other hand, InnoDB needs to do the same work as the OS, with less information, and quite a bit of complex code, but it means that it doesn’t need to do so many system calls, and can be faster.
Voron, on the gripping hand, relies on the OS Page Cache to do the heavy lifting, but generally issues very few system calls. That is because Voron memory map the data, so access it is usually a matter of just pointer dereference, the OS Page Cache make sure that the relevant data is in memory and everyone is happy. In fact, because we memory map the data, we don’t have to manage buffers for the system calls, or to do data copies, we can just serve the data directly. This ends up being the cheapest option by far.
Connection handling
Spawning a process per connection is something that I haven’t really seen since the CGI days. It seems pretty harsh to me, but it is probably nice to be able to kill a connection with a kill –9, I guess. Thread per connection is also something that you don’t generally see. The common situation today, and what we do with RavenDB, is to have a pool of threads that all manage multiple connections at the same time, often interleaving execution of different connections using async/await on the same thread for better performance.
More posts in "re" series:
- (05 Dec 2025) Build AI that understands your business
- (02 Dec 2025) From CRUD TO AI – building an intelligent Telegram bot in < 200 lines of code with RavenDB
- (29 Sep 2025) How To Run AI Agents Natively In Your Database
- (22 Sep 2025) How To Create Powerful and Secure AI Agents with RavenDB
- (29 May 2025) RavenDB's Upcoming Optimizations Deep Dive
- (30 Apr 2025) Practical AI Integration with RavenDB
- (19 Jun 2024) Building a Database Engine in C# & .NET
- (05 Mar 2024) Technology & Friends - Oren Eini on the Corax Search Engine
- (15 Jan 2024) S06E09 - From Code Generation to Revolutionary RavenDB
- (02 Jan 2024) .NET Rocks Data Sharding with Oren Eini
- (01 Jan 2024) .NET Core podcast on RavenDB, performance and .NET
- (28 Aug 2023) RavenDB and High Performance with Oren Eini
- (17 Feb 2023) RavenDB Usage Patterns
- (12 Dec 2022) Software architecture with Oren Eini
- (17 Nov 2022) RavenDB in a Distributed Cloud Environment
- (25 Jul 2022) Build your own database at Cloud Lunch & Learn
- (15 Jul 2022) Non relational data modeling & Database engine internals
- (11 Apr 2022) Clean Architecture with RavenDB
- (14 Mar 2022) Database Security in a Hostile World
- (02 Mar 2022) RavenDB–a really boring database
Comments
"But what killed it for us was the fact that it is almost impossible to handle the scenario of replacing the master server automatically. In order to handle that, you need to be able to deterministically let the old server know that it is demoted and should accept no writes, and the new server that it can now accept writes and send its WAL onward. But if there is a period of time in which both can accept write, then you can’t really merge the WAL, and trying to is going to be really hard. You can try using distributed consensus to run the WAL, but that is really expensive (about 400 writes / second in our benchmark, which is fine, but not great, and impose a high latency requirement)."
There are ways of working around this EventStore does it (and two orders of magnitude higher in terms of performance). In particular you use quorums for election and only respond to write when a quorum of nodes acknowledges it.
Greg,
Yes, that is what we did.
The problem is that quorum writes are possible only a certain number of times a second.
We can do better than that by using tx merging, but then your writes become bigger, and it takes longer to confirm them over the network.
And you can't really do tx merging properly for the WAL.
" The problem is that quorum writes are possible only a certain number of times a second."
Umm we certainly do more than a few writes/second. I am at about 60k/sec on my desktop here.
Greg,
Full, distributed quorum writes?
As in, you have contacted a majority of the nodes and got a reply back after doing on disk persistence on over half of them?
I get the feeling that we are talking about different things.
I see a lot of design issues in both databases as well. It boggles the mind how capable engineers can make such grave mistakes such as a process per connection or the rather strange Postgres MVCC format. Did they not see the consequences? They are easy to see.
Postgres is far beyond MySQL in terms of features and usability. The deal is marred by a few, severe issues.
The more I learn about MySQL and Postgres the more I understand why it pays off to pay for commercial databases. Basically, they don't stink as much. Raven seems rather clean. From experience I know that SQL Server is super clean and does not suffer from the issues written about here and at Uber. I'm often amazed at how much they got right in the initial design (there has not been a major design revision ever).
"Full, distributed quorum writes?
As in, you have contacted a majority of the nodes and got a reply back after doing on disk persistence on over half of them?"
yes.
Greg,
I'm not familiar with a disk that can do 60K sync per second. Let alone over the network.
What are you using?
Tobi,
The strange MVCC format is actually quite reasonable. But it comes at a cost for such scenarios. It gives PG a much better way to handle concurrent transactions without locks.
Note that commercial databases has their own issues and trade off. They are generally not discussed so publicly, though.
Not trying to sell SQL Server here but they don't need that for their MVCC. There is only one row version in the database. Older versions are kept in tempdb in a very efficient format. They are bulk-deleted periodically. This has it's downsided but in practice it works really well. No write amplification for indexes, no replication cost. The main cost is a 14 byte hidden field in all rows.
So the Postgres choice is not reasonable given that better solutions exist. Reasonable != it works.
Writes != iops there can be multiple conceptual writes in a given disk operation (think 4 1k writes in a 4k operation). That said if you don't know any disks that can do 60k iops you really aren't looking very hard 80-100k iops is the low bar on most reasonable commodity ssds these days. High end are 1m iops (fusionio etc).
Intel 750 210k iops
samsung 950 256 90k (4k) iops
samsung 950 110k iops
Sandisk extreme pro 100K (4k) iops
Mushkin striker 91k (4k) iops
Samsung evo 97k iops
I can write a blog post if you want on how the system actually works its quite similar to raft though.
Tobi,
Yes, we do much the same thing in Voron, but without the overhead. :-)
Greg,
Okay, we are talking about very different things.
When I'm talking about a write, I'm talking about (conceptually, write() && fsync() ).
Even good disks today can't do more than a few hundreds per second.
You are talking about buffered writes, which is something quite different.
And you are also batch writes into a single disk / quorum operation.
let's see I just ran a test here on my mac book pro.
Here is 1.3m 4096 write/flush via memmap (each is a write then msync)
mmap_write flush=true doing 1310720 iterations of 4096 size for 5368709120 total
Total time 56797.429000
That is slightly more than a few hundred write + flush/second.
mmap_write flush=true doing 40960 iterations of 131072 size for 5368709120 total
Total time 11859.856000
This is 130KB writes (flush for each) still at bout 4000/second though each operation is 32 4k operations.
For write + fsync
file_write flush=true doing 1310720 iterations of 4096 size for 5368709120 total
Total time 61973.707000
file_write flush=true doing 40960 iterations of 131072 size for 5368709120 total
Total time 8571.320000
O_DIRECT gives similar (though is a bit dodgy on macs)
Code (C): https://gist.github.com/gregoryyoung/09f5d8799f4425d6d7717b81cfc678c7
Greg,
On Macs, fsync does nothing. you need to use fcntl(F_FULLFSYNC).
From testing that we have done, real fsync on mac is much slower than linux /windows
You miss my point. I get similar results on my linux box (where fsync absolutely works). I am in the 10s of thousands of synchronous operations there. Other areas of the test of course use msync (which does work) and O_DIRECT (dodgy on mac but fine in linux). You said :
"When I'm talking about a write, I'm talking about (conceptually, write() && fsync() ). Even good disks today can't do more than a few hundreds per second. "
You are off by two orders of magnitude. As this test proves.
Greg,
Something is wrong with your setup.
See my blog posts about this recently:
https://ayende.com/blog/174785/fast-transaction-log-windows
https://ayende.com/blog/174753/fast-transaction-log-linux
Hi,
Every database has its design limitations, and Postgres' MVCC design certainly isn't good for very volatile data. The biggest thing biting PostgreSQL here is definitely lack of operational knowledge, as this was the decisive reason why Uber really migrated (back) to MySQL, see another very informative post on https://eng.uber.com/schemaless-part-one/
Lack of decent multi-master clustering support is also a big pain point.
As to see what happened with Uber's postgresql see, the funky part starts 16 minutes into the video - https://vimeo.com/145842299
Kind regards,
Gasper Z.
Bah, forgot to mention - postgres does not rely solely on page cache, but also has own cache, via shared memory.
Greg, I had the same finding when I tested it on Windows with WRITE_THROUGH | NO_BUFFERING on a magnetic disk with 4KB synchronous QD1 writes. I'm hard pressed to explain that result. I don't think consumer disks lie to the OS these days about durability. AFAIK this is kind of a myth. I never saw evidence for that.
The best explanation that I have is that the disk buffers 1 track of data and has enough capacitor energy to write that back before power is lost. I don't know if that is true... Writing one track takes about 6ms so it's plausible.
Just to add a bit. You would be right 4 years ago not today SSDs have gone from milliseconds to microsends. The test is essentially measuring the latency of the write/flush (or page cache + msync or direct io). If you compile it (enable histograms) and run it you will see why you can do much more than a few hundred/per second, 98% for me come back sub-millisecond on the small (4096) writes.
You are also correct thats its a few hundred/second if you are running in the cloud. A d4 in azure running against local SSD gave me 1-2ms at 90%. In this case you would only get around 500/sec. Locally attached SSDs are however much faster.
If you really want to have some fun try on a high end board check out the latencies on the dimm based one here: http://wccftech.com/intel-3d-xpoint-optane-ssd-benchmark/ 9μs?!
@tobi many disks in general do lie, they also like to put a bit of ram and or ssd as a cache in front of the spindle to cheat benchmarks. measuring disks is hard. You can find out by trying a durability test on it.
Postgres does not rely directly on the OS cache, it has it's own dedicated buffer pool - called Shared Buffers. Data that does not is not in the buffer pool may be found by the OS in the OS cache if PG doesn't find a page in its own buffer cache and issues a request to the OS for data.
Logical Replication is available today, as an extension and will be getting pulled into Postgres Core in the next release (not 9.6 which is in Beta, but the following one). You can get it today. Yes it is an add on, but trivial to install.
https://2ndquadrant.com/en/resources/pglogical/
As far as the per/process connection model - remember that this choice was made close to two decades ago (possibly even longer). Could it be improved now? Of course, but to criticize the developers who made that choice at the time is a bit silly. It was done to favor stability (look at the long history of MySQL issues surrounding threading for comparison)
Brad, the engineers may habe made good choice back then but in the last 15 years they have made the bad choice to not do anything about this. Windows does not support forking so the code base appears to be able to work without it.
According to https://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server only starting with 9.4 was using any significant shared buffer amount possible without recompiling the kernel. So it seems the main mode of operation was to indeed rely on the OS.
I think this analysis is somewhat flawed:
@tobi - you are incorrect. I ran high volume Postgres databases with shared buffers set to the several gigabytes as far back as Postgres 8.0 (which was released in 2005).
Your interpretation of the wiki is wrong. There is need to recompile the kernel to do this, you needed to run a couple sysctl commands to change kernel.shmmax & kernel.shmall settings and change the defaults in /etc/sysctl.conf. This was no great secret, it is clearly documented in the manual and simple to find on google. Of course, that is a pain to remember, which is why the PG developers fixed it in 9.4 and it's not needed anymore.
On connection pooling - pgbouncer is a great tool and works wonders, but there is a core issue with the connection model in general. Connections are made on a per DB/DB User pair, which means that you can't pool connections between different DB users. That is fine for some setups, but if you have a multi-tenant application, or ever a single one with a number of different users, it gets problematic. There are workaround (like SET ROLE), but those involve security compromises that are not always wise.
It seems my knowledge of Postgres is not sufficient to comment on some aspects. That said, why does Postgres use the OS cache at all for its data files? It seems a purely shared buffer based solution would be best. The OS would not contribute anything meaningful if Postgres is capable of managing the cache by itself.
Tobi,
By letting the OS manage the buffers, you get much nicer behavior since the OS can consider other resource usage needs. If you have a web app and a db on the same server, the OS can balance their needs appropriately.
It also means that you can get away with not writing a lot of pretty complex code to manage the cache, and you avoid having duplicate data, once in the OS page cache and once in your own cache.
I actually really enjoyed and appreciated that blog post as well (for getting into the down-and-dirty aspects while being well-written), so much so that I emailed Evan directly to give him some feedback, since Uber's developer blog doesn't have a comments section. Your post (also awesome) stirs in my some of the same thoughts I had for his post as well, specifically:
Should we be using MySQL and InnoDB as interchangeable terms? I know that MyISAM is rarely used and highly discouraged at this point, but clearly MySQL is a DB engine that is designed to separate itself as a product from the storage engine set for a given table. So does the credit for these performance decisions go to MySQL or to InnoDB? If MySQL introduced some newer storage engine, could that storage engine lack these benefits while still being run in a MySQL context?
For that matter, if the credit does go to InnoDB, does that mean that we should really be praising InnoDB-enabled RDBMSs, like MariaDB and Percona?
By the same train of thought, Evan's post emphasized the value found in MySQL over Postgres when they adopted Schemaless. Are these distinctions in disk writes and index updates more noticeable/relevant for that specific application running on top of MySQL? As I worded it to him, if they were just migrating from Postgres to MySQL and using pure db queries, would these differences have as big an impact or is it more like "MySQL is pretty good, but its main benefit to us is that it can run Schemaless like a champ!" Is the endorsement for MySQL (or InnoDB) overall, or its superior performance for a specific next-layer application ( Schemaless )?
I think Uber chose Postgres (over MySQL) with some amount of forethought, but for myself personally, I have never really understood what Postgres's real advantage is. It always has seemed like the snobbier open-source older brother of MySQL, like everyone likes MySQL, thinks it's really friendly and gets invited to the cool parties and the dive bars, but we act like Postgres is this better or more esteemed product that really just suffers from being so smart it alienates everyone at the party. These articles are the first really nitty-gritty level endorsements I've seen for MySQL as a technology rather than as a product (if that makes any sense). The only thing I've really understood about Postgres in terms of being superior as an RDBMS is that it is the most compliant with the SQL-2011 standards, which I think is pretty cool but is hardly a huge selling point when it implicitly indicates that none of the other major vendors are as compliant and they are still more popular (suddenly my mind wanders to Opera and I'm a little sad). Anyways, my point being : as long as we're discussing why MySQL (or InnoDB) is clearly better in the ways mentioned here and in Evan's post, can we give some reasons or explanation on what Postgres /is/ better at, compared to MySQL or other vendors? I am not trying to defend Postgres so much as fill in the blanks of this discussion on why Postgres was a contender against MySQL in the first place
Post-Script : Evan responded to my email and was super cool and gave me lots of great feedback, but seeing this article makes me think this discussion is long overdue, and my questions might help shape the public conversation.
But Postgres does have it's own cache. They have both which seem worse than one of them alone. And the OS has no idea what appropriate memory quotas are for different apps. If you want to run a database on the same server as a web application I don't think you'll like the paging that the other apps are going to experience. OS paging systems don't have enough information and in my experience the Windows memory manager is sometimes outright dumb.
On Windows XP copying a large file tended to page out almost everything else because the LRU list was filled with fresh pages from the files to be copied. This is fixed now but this shows how much attention the OS caching algorithms get (nearly none).
Anthony, Postgres has a great feature list: https://www.postgresql.org/about/featurematrix/ This is far beyond MySQL. Postgres is a better system in most cases. Uber does not use much of those features. They built a document DB on top of an RDBMS. For any relational-style system Postgres will deliver far better productivity. I can't speak to performance. They can't be far apart on performance.
Tobi,
Windows XP was released 15 years ago. You really shouldn't base decisions on what it would do.
The kind of smarts and attention that go into the paging system are decidedly more than none. They are critical for system performance, and they get a lot of eyes and attention.
That is like saying that Linux sucks because fsync freeze the entire system (http://news.softpedia.com/news/Who-Freezes-The-System-Firefox-or-ext3-86242.shtml) in 2008.
The double buffering is inefficient, but the development community is fairly small and folks decide to focus on more pressing things (thankfully - we are seeing parallel query execution coming finally, and logical replication in core on the horizon). I have also been told by PG developers that it's a different skill set to deal with the filesystem stuff. Better to leave that to the folks that know it and have the PG developers focus on what they know.
Also, there have been numerous times that I have seen Postgres get a good speed bump "for free" from developments in the filesystem /Linux OS layer, so there is benefit.
Postgres is fast. Uber hit the edge at what looks like a high volume, and move to a NoSQL style approach. Not uncommon.
Brad,
While I fully appreciate that the skill set for doing things like parallel queries isn't fully overlapping with file system internals, managing how you write to the disk is pretty much #1 in the level of importance.
I would expect the PG developers to know how to make the best use of that.
Now, I absolutely think that you should be using the OS cache, because you get to lean on people who deal with that and have more insight into what is going on, but I do that with full understanding of what is going on behind the curtain, and knowing how to take advantage of this behavior to get the best performance.
As a good example of that, see:
http://queue.acm.org/detail.cfm?id=1814327
Comment preview