I mentioned before that NH Prof has a problem with dealing with a lot of activity from the profiled application. In essence, until it catch up with what the application is doing, there isn't much that you can do with the profiler.
I consider this a bug, and I decided to track that issue with some verifiable results, and not just rely on hunches. The results were... interesting. The actual problem was in the place that I expected it to be, but it was more complex than expected. Let me try to explain.
The general architecture of NH Prof is shown here:

And the actual trouble from the UI perspective is in the last stage, actually updating the UI. UI updates are done directly on a (very) rich view model, which supports a lot of the functionality that NH Prof provides.
Because, as usual, we have to synchronize all access to the UI, we actually update the UI through a dispatcher class. The relevant code is this:
private void SendBatchOfUpdates()
{
while (true)
{
int remainingCount;
Action[] actions;
lock (locker)
{
actions = queuedActions
.Take(100)
.ToArray();
for (int i = 0; i < actions.Length; i++)
{
queuedActions.RemoveAt(0);
}
remainingCount = queuedActions.Count;
}
if (actions.Length == 0)
{
Thread.Sleep(500);
continue;
}
dispatcher.Invoke((Action)delegate
{
using(dispatcher.DisableProcessing())
{
var sp = Stopwatch.StartNew();
foreach (var action in actions)
{
action();
}
Debug.WriteLine(remainingCount + "\t" + sp.ElapsedMilliseconds);
}
});
}
}
We queue all the operations on the view model, batch them and execute them to the UI. This is the behavior as it stands right now (that is, with the problem). Looking at the code, is should be obvious to you that there is one glaring issue. (Well, it should be oblivious, it wasn't to me until I dug deeper into it.)
If the number of queued actions is greater than the batch size, we are going to try to drain the queue, but as long as we add more actions to the queue faster than we can process them, we are going to keep hammering the UI, we basically keep the UI busy with updates all the time, and never let it time to process user input.
Note the debug line in the end, from that, I can generate the following graph:
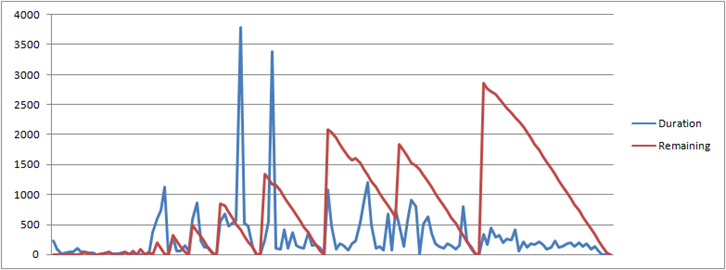
For the duration line, the number is the number of milliseconds it took to process a batch of 100 items, for the red line, this is the number of items remaining in the queue that we need to drain. You can clearly see the spikes in which more work was added to the queue before we could deal with that.
You can also see that doing the actual UI work is slow. In many cases, it takes hundreds of milliseconds to process, and at times, it takes seconds to run. That is because, again, we have a very rich view model, and a lot of stuff is bound to that.
Before I can go forward, I need to describe a bit how NH Prof actually talks to the UI. Talking to the UI is done by raising events when interesting things happen. The problem that I initially tried to solve was that my input model is a stream of events, and it mapped nicely to updating the UI when I got the information.
Let us say that we want opened a session, executed a single SQL statement, and then closed the session. What are the implication from UI marshalling?
- Create new session
- Add new statement
- Add alert, not running in transaction
- Update statement with parsed SQL
- Update statement with row count
- Add alert, unbounded row set
- Update statement duration
- Close session
- Update session duration
So for the simplest scenario, we have to go to the UI thread 9 times. Even when we batch those calls, we are still end up going to the UI thread too often, and updating the UI frequently. That, as I mentioned, can take time.
Now, a very easy fix for the problem is to move the thread sleep above the if statement. That would introduce a delay in talking to the UI, letting the UI time to catch up with user input. This would make the application responsive during periods where the actions to perform in the UI.
The downside is that while this works, it means slow stream of updates into the application. That is actually acceptable solution, except that this is the same situation that we find ourselves with when we are dealing with processing an offline profiling session. When those are big, it can take really long time to process those.
Therefor, this is not a good solution.
A much better solution would be to reduce the number of times that we go to the UI. We can reduce the number of going to the UI significantly by changing the process to:
- Create new session
- Add new statement (with alerts, parsed SQL, row count and duration)
- Close session (with duration)
That requires some changes to the way that we work, but those are actually good changes.
This is not quite enough, though. We can do better than that when we realize that we actually only show a single session at a time. So most often, we can reduce the work to:
- Create new session
- Close Session (with duration, number of statements, alerts aggregation, etc)
If we also add batching to the mix, we can reduce it further to:
- Create new session & close it (with duration, number of statements, alerts aggregation, etc)
We have to support both of them, because we need to support both streaming & debugging scenarios.
We don't need to let the UI know about the statements, we can give it to the UI when it asks us about them, when you select a session in the sessions list.
And now, when we are looking at a session, we can raise an event only for that session, when a statement is added to that session. As an added bonus, we are going to batch that as well, so we will update the UI about this every .5 seconds or so. At that point, we might as well do an aggregation of the changes, and instead of sending just the new statement, we can send a snapshot of the currently viewed session. The idea here is that if we added several statements, we can reduce the amount of UI work we have to do by making a single set of modifications to the UI.
Thoughts?
Oh, and do you care that I am doing detailed design for NH Prof problems on the blog?






 Very often I see people trading startup performance for overall performance. That is a good approach, generally. But it has huge implications when it gets out of hand.
Very often I see people trading startup performance for overall performance. That is a good approach, generally. But it has huge implications when it gets out of hand.








