First, I need to justify why I am doing this. In the past, I have evaluated both NServiceBus and Mass Transit, and I have created applications to try both of them up. Both code bases have enlightened me about the notions of messaging and how to make use of them. That said, they are both of much wider scope than I need right now, and that is hurting me. What do I mean by that?
Right now I am introducing a whole lot of concepts to a team, and I want to make sure that we have as few moving parts as possible. If you go through the code, you'll see that I liberally stole from both ideas and code from Mass Transit and NServiceBus. My main goal was to get to a level with no configuration, no complexity, high degree of flexibility from design stand point, but a very rigid structure for the users. Along the way I also took care to try to build into this support for some concepts that I think are interesting (message interception, taking advantage of features in MSMQ 4.0, message modules, etc).
The current code base is tiny, ~2,550 lines of code, cohesive, and well designed (I believe). It doesn't do everything that NServiceBus or Mass Transit , but I think that it is an interesting project, and I intend to take it to production.
Some of the highlights:
- C# 3.0 & MSMQ 4.0 - taking advantage of features such as sub queues, async queue receiving.
- Pluggable internal architecture.
- Minimal moving parts, strongly opinionated.
- Hard focus on developer productivity and ease of use.
- Conventions, assertions and convictions.
Let me try to go over each item and explain what I mean in it.
I have the freedom to chose my platform for this project, and I decided to make as much use of the platform features as I can, to make my life easier. C# 3.0 makes a lot of tasks more pleasant, if only because of extension methods and the ability to filter using Where(), and I am quite addicted to var.
But probably more interesting is the use of MSMQ 4.0 sub queues, I am using them here to make sure that an endpoint is a consolidated unit. Take a look:
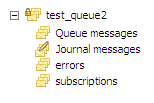
Using this approach, subscriptions are stored in a sub queue of the current queue, and I can reroute errors to the error sub queue. This keeps everything in a single place, and simplify understanding what is actually going on in the application, not to mention that it keeps everything together (less queues, less places to check, less things can go wrong). Aysnc queue receiving is another different thing that I am doing. This allow me to avoid consuming application level threads when they are not needed, and defer this to the level of the OS.
The next two points are sort of contrary to one another. On the one hand, I have a very strong bias toward pluggable systems, but at the same time, I wanted to make something that requires very little from the user. That is, it should require very little configuration and a real effort to break. I solved that by creating they type of architecture that I generally do, but by making the public API as simple as possible:
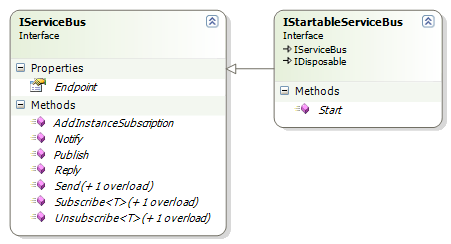
Startable service bus does just that, it allow you to start & dispose of the bus. The real interesting tidbits are in IServiceBus.
Subscribe and Unsubscribe should be pretty much self explanatory, I think. They let other endpoints know that you are are interested / not interested in a particular message type.
Send will send (bet you wouldn't figure that one out if I didn't told you!) a message to a particular end point, although you can (and probably will) just send a message, and the bus will figure out who the message owner on its own (one of the few pieces of configuration that I did put in).
Reply will send a message back to the originator of the message we are currently handling. If you aren't handling a message, it will throw.
Notify & Publish are very similar, both of them will publish the message to all interested subscribers, but they have one very different semantic. If you publish a message and it has no subscribers, it is considered an error, and it will throw. If you you use notify, it is expected that you might not have any subscribers. I find this distinction important enough that I wanted to capture this in the API.
AddInstanceSubscription is something that I am not sure that I like yet, although I can see why I would need it if I didn't have it. It allow a live instance to request to subscribe to messages from the bus.
One thing that you will notice is that there is absolutely no facility for request / reply here. At least, not to the same instance of the object. Actually, that is not accurate, you can handle this scenario, but you would have to handle your own locking, I am not going to provide anything there for you. This is a scenario that I want to discourage.
Let us move from the bus to the actual message handlers. In Rhino ServiceBus, they are specified as:
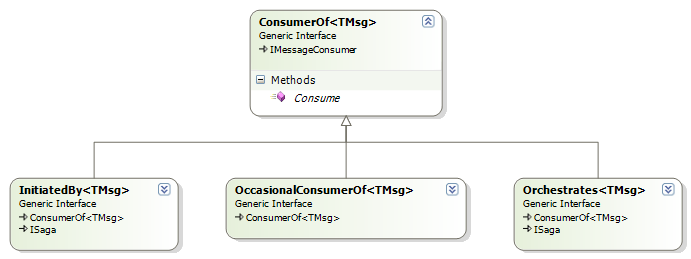
A standard consumer for messages need to implement ConsumerOf<TMsg>, and that about it. The bus will automatically check the container for all types that match that, subscribe them to their destinations, and get ready to start processing messages. OccasionalConsumerOf<TMsg> is a way to tell the bus that we aren't really interested in automatically subscribing, Maybe we intend to use this using AddInstanceSubscription or maybe we want to programmatically control subscriptions.
InitiatedBy<TMsg> and Orchestrate<TMsg> are messages that drives sagas. I don't have much to say about them except that they work much the same way you would use them in NServiceBus or Mass Transit.
If you look at the API, you probably notice something interesting. A lot of the concepts are very similar to the way NServiceBus handle them, but the some of the API (especially for message handlers) is much closer to Mass Transit. As I mentioned, I dug deep into both of them before deciding to build my own. Much of the behavior is also modeled around the way NServiceBus works (transactional message interactions, auto roll backs on error, message handlers are not expected to deal with errors, auto retries, moving to error sub queue for administrator attention, etc).
Here is the configuration for an endpoint in the service bus:
<castle>
<facilities>
<facility id="rhino.esb" >
<bus threadCount="1"
numberOfRetries="5"
endpoint="msmq://localhost/test_queue2"
/>
<messages>
<add assembly="Rhino.ServiceBus.Tests"
endpoint="msmq://localhost/test_queue"/>
</messages>
</facility>
</facilities>
</castle>
And in order to start the bus:
var container = new WindsorContainer(new XmlInterpreter());// read config from app.config
container.Kernel.AddFacility("rhino.esb", new RhinoServiceBusFacility());// wire up facility for rhino service bus
container.Register(
AllTypes.FromAssembly(Assembly)
.BasedOn(typeof(IMessageConsumer))
);
var bus = container.Resolve<IStartableServiceBus>();
bus.Start();
And this is it, messages arrives at the test_queue2 endpoint will now be served.
There isn't any additional configuration, and every line of configuration here is something that an administrator is likely to want to change. Note that we pick up consumers automatically from the container, and we register them automatically. This is another step that I am doing in order to reduce the amount of things that you should worry about.
I mentioned that I somehow had to resolve my own drive toward pluggable architecture and operational flexibility with the need to create a simple, standard way of doing things. I solved the problem making the code pluggable, but the RhinoServiceBusFacility has very strong opinions about how things should go, and it is responsible of setting the bus' policies.
Another design goal was that this system should be extremely developer friendly. This means that I took the time to investigate and warn about as many failure paths as possible. For example, publishing without subscribers, which is something that happened to me in the past, and took me some time to figure out. I consider errors to be part of the user interface of a framework. Bad errors are a big problem, and can cause tremendous amount of time wastage along the way, just tracking down issues.
No configuration is another, but there are a few others. For example, Rhino ServiceBus contains a logging mode in which all messaging activities can be sent to a separate queue, to allow us a time delayed view of what is actually going on. The serialization format on the wire is also human readable (xml, and heavily influenced by how NServiceBus's serialization format is built).
Here is an example of a test message:
<?xml version="1.0" encoding="utf-8"?>
<esb:messages xmlns:esb="http://servicebus.hibernatingrhinos.com/2008/12/20/esb"
xmlns:tests.order="Rhino.ServiceBus.Tests.XmlSerializerTest+Order, Rhino.ServiceBus.Tests"
xmlns:uri="uri"
xmlns:int="int"
xmlns:guid="guid"
xmlns:datetime="datetime"
xmlns:timespan="timespan"
xmlns:array_of_tests.orderline="Rhino.ServiceBus.Tests.XmlSerializerTest+OrderLine[], Rhino.ServiceBus.Tests"
xmlns:tests.orderline="Rhino.ServiceBus.Tests.XmlSerializerTest+OrderLine, Rhino.ServiceBus.Tests"
xmlns:string="string"
xmlns:generic.list_of_int="System.Collections.Generic.List`1[[System.Int32, mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089]], mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
<tests.order:Order>
<uri:Url>msmq://www.ayende.com/</uri:Url>
<int:Count>5</int:Count>
<guid:OrderId>1909994f-8173-452c-a651-14725bb09cb6</guid:OrderId>
<datetime:At>2008-12-17T00:00:00.0000000</datetime:At>
<timespan:TimeToDelivery>P0Y0M1DT0H0M0S</timespan:TimeToDelivery>
<array_of_tests.orderline:OrderLines>
<tests.orderline:value>
<string:Product>milk</string:Product>
<generic.list_of_int:Fubar>
<int:value>1</int:value>
<int:value>2</int:value>
<int:value>3</int:value>
</generic.list_of_int:Fubar>
</tests.orderline:value>
<tests.orderline:value>
<string:Product>butter</string:Product>
<generic.list_of_int:Fubar>
<int:value>4</int:value>
<int:value>5</int:value>
<int:value>6</int:value>
</generic.list_of_int:Fubar>
</tests.orderline:value>
</array_of_tests.orderline:OrderLines>
</tests.order:Order>
</esb:messages>
That is pretty readable, I think. And yes, I am aware of the other million of XML serialization formats that are out there. I wanted something readable, remember?
Another common pain in the... knee with messaging systems is debugging. Usually you have a sender and a receiver, which communicate with one another via messaging, and trying to track down what is going on between them can be a pretty nasty issue. Frankly, I would much rather wish that I didn't have to debug this, but that is not going to happen any time soon, so I wanted to create a good debugging experience. Rhino ServiceBus is hostable in any type process, and for development, I set it up so my web front end also host the back end, this make debugging through complex message flows pretty much seamless.
Last, conventions and assertions. I have a very clear idea about what I want to do with this library, and the code reflects that. Things like making a distinction between publish and notify, or making it hard to do request reply are just part of that. Another is the notion of an endpoint as a fully independent unit, as you can see in the notion of subscriptions being part of a sub queue on the endpoint, rather than being backed by either a service (Mass Transit) or a separate queue or database based subscription storage (NServiceBus).
And now we get to talk about convictions. Rhino ServiceBus will actively fight against you if you try to do things that you shouldn't. For example, if you try to send a batch of messages containing over 256 messages, it will fail. But more than that, if you try to send a message containing a collection that has more than 256 items, it will also fail. In both cases, it will alert you to a problem with unbounded result set. The proper way to handle this scenario is to send several batches of messages. Then it is the job of the transport to ensure that they get to the destination in the appropriate fashion, and that is free to join them together if it really wants to.
One final notion relates to the idea of service isolation. Right now, Rhino ServiceBus doesn't have an explicit notion about that, but it does let you run several services as part of the same process. I intend to take it a bit further once I finish polishing up the host, to the point where you can say that a service is an assembly, and you can host several of them (isolated to their own AppDomains) in the same process.
But that is enough, I think. You can get the source in the usual place:
http://github.com/ayende/rhino-esb
Some stats:
- I started the project at about noon, Sunday.
- It has 36 commits so far, and I am already using it for a real project.
- 2,550 lines of code.
- 1,761 lines of tests
- 86% test coverage in 81 tests
- C# 3.0
- MSMQ 4.0 - Vista or Windows Server 2008



















