How many times have the documentation of a product told you that you really should use another product? Well, this is one such case. Rhino Igloo is an attempt to make an application that was mandated to Web Forms more palatable to work with. As such, it is heavily influenced by MonoRail and its ideas.
I speak as the creator of this framework, if at all possible, prefer (mandate!) the use of MonoRail, it will be far easier, all around.
Model View Controller is a problematic subject in Web Forms, because of the importance placed on the view (ASPX page) in the Web Forms framework.
When coming to build an MVC framework on top of Web Forms, we need to consider this limitation in our design. For that reason, Rhino Igloo is not a pure MVC framework, and it works under the limitations of the Web Forms framework.
Along with the MVC framework, Rhino Igloo has tight integration to the Windsor IoC container, and make extensive use of it in its internal operations.
It is important to note that while we cover the main chain of events that occurs when using Rhino Igloo, we are not going into the implementation details here, just a broad usage overview.
I took to liberty of flat out ignoring implementation details that are not necessary to understanding how things flow.
 Overall, the Rhino Igloo4framework hooks into the Web Forms pipeline by utilizing a common set of base classes ( BasePage, BaseMaster, BaseScriptService, BaseHttpHandler ). This set of base classes provide transparent dependency injection capabilities to the views.
Overall, the Rhino Igloo4framework hooks into the Web Forms pipeline by utilizing a common set of base classes ( BasePage, BaseMaster, BaseScriptService, BaseHttpHandler ). This set of base classes provide transparent dependency injection capabilities to the views.
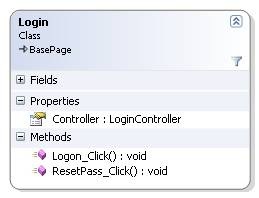
As an example, to the right you can see the Login page. As you can see that the login page has a Controller property, of type LoginController. The controller property is a simple property, which the base page initializes with an instance of the LoginController.
It is important to note that it is not the responsibility of the Login page to initialize the Controller property, but rather its parent, the BasePage. As an example, here is a valid page, which, when run, will have its Controller property set to an instance of a LoginController:
public partial class Login : BasePage
{
private LoginController controller;
public LoginController Controller
{
get { return controller; }
set { controller = value; }
}
}
As a result of that, the view no longer needs to be aware of the dependencies that the LoginController itself has. Those are automatically supplied using Windsor itself.
The controller is the one responsible for handling the logic of the particular use case that we need to handle. The view's responsibilities are to call the controller when needed. Here is the full implementation of the above Login_Click method:
public void Logon_Click(object sender, EventArgs e)
{
if (!Controller.Authenticate(Username.Text, Password.Text))
{
lblError.Text = Scope.ErrorMessage;
}
}
As you can see, the view calls to the controller, which can communicate back to the view using the scope.
The scope class is the main way controllers get their data, and a common way to pass results from the controller to the view.
The scope class contains properties such as Input and Session, which allows an abstract access to the current request and the user's session.
This also allows replacing them when testing, so we can test the behavior of the controllers without resorting to loading the entire HTTP pipeline.
Of particular interest are the following properties:
· Scope.ErrorMessage
· Scope.SuccessMessage
· Scope.ErrorSummary
These allow the controller to pass messages to the view, and in the last case, the entire validation failure package, as a whole.
Communication between the controller and the view is intentionally limited, in order to ensure separation of concerns between the two.
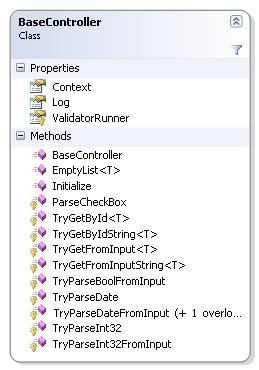 All controllers inherit from Base Controller, which serves as a common base class and a container for a set of utility methods as well.
All controllers inherit from Base Controller, which serves as a common base class and a container for a set of utility methods as well.
From the controller, we can access the current context, which is a nicer wrapper around the Http Context and operations exposed by it.
While the controllers are POCO classes, which are easily instantiated and used outside the HTTP context, there are a few extra niceties that are supplied for the controllers.
The first is the Initalize() method, which allows the controller to initialize itself before processing begins.
As an extension to this idea, and taking from MonoRail DataBind approach, there are other niceties:
[Inject]
Inject is an attribute that can be used to decorate a property, at which point the Rhino Igloo framework will take a value from the request, convert it to the appropriate data type and set the property when the controller is first being created. Here is an example:
[Inject]
public virtual Guid CurrentGuid
{
Get { return currentGuid; }
set { currentGuid = value; }
}
The framework will search for a request parameter with the key "CurrentGuid", convert the string value to a Guid, and set its value.
[InjectEntity]
InjectEntity performs the same operation as Inject does, but it takes the value and queries the database an entity with the specified key.
[InjectEntity(Name = Constants.Id, EagerLoad = "Customer")]
public Order Order
{
get { return order; }
set { order = value; }
}
This example shows how we can automatically load an order from the database based on the "Id" request parameter, and eager load the Customer property as well.
Rhino Igloo has integration to Rhino Common's Unit Of Work style, but overall, has no constraints on the way the model is built.