I spoke before about using the XML capabilities of SQL Server in order to easily pass list of values to SQL Server. I thought that this was a pretty good way to go, until I started to look at the performance numbers.
Let us take a look at this simple query:
DECLARE @ids xml
SET @ids = '<ids>
<id>ALFKI</id>
...
<id>SPLIR</id>
</ids>'
SELECT * FROM Customers
WHERE CustomerID IN (SELECT ParamValues.ID.value('.','NVARCHAR(20)')
FROM @ids .nodes('/ids/id') as ParamValues(ID) )
This simple query has a fairly involved execution plan:
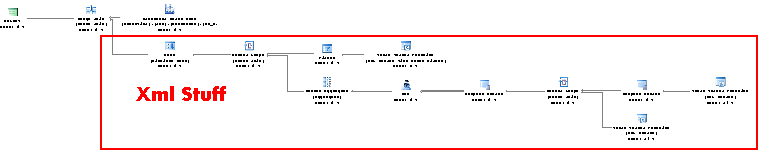
This looks to me like way too much stuff for such a simple thing, especially when I see this:
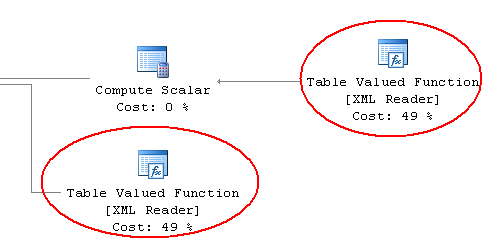
So the XML stuff is taking up 98% of the query?
I then checked the second route, using fnSplit UDF from here. Using it, I got this result:
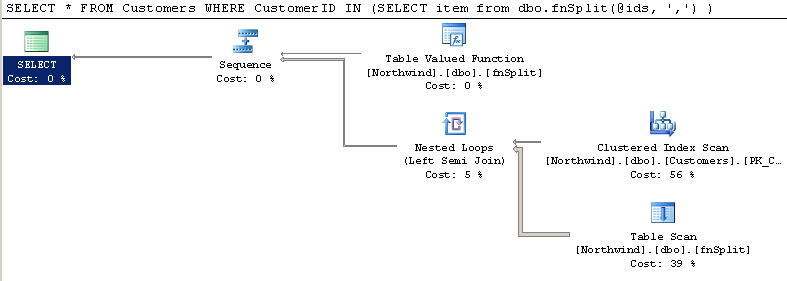
So it looks like it is significantly more efficient than the XML counter part.
But what about the larger scheme? Running the fnSplit over 9,100 items got me a query that took nearly 45 seconds, while a XML approach over the same set of data had no measurable time over just 91 records.
I then tried a simple SqlCLR function, and got this the same performance from it:
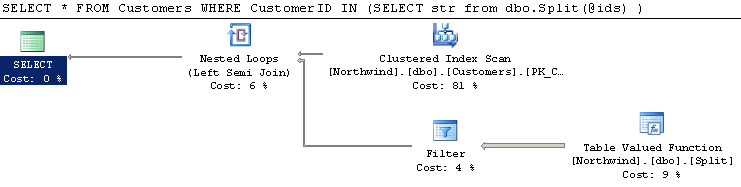
The code for the function is:
[SqlFunction(FillRowMethodName = "FillRow", TableDefinition = "str NVARCHAR(MAX)")]
public static IEnumerable Split(SqlString str)
{
if (str.IsNull)
return null;
return str.Value.Split(',');
}
public static void FillRow(object obj, out SqlString str)
{
string val = (string) obj;
if (string.IsNullOrEmpty(val))
str = new SqlString();
else
str = new SqlString(val);
}
As you can probably guess, there are all sorts of stuff that you can do to make it better if you really want, but this looks like a very good approach already.
Tripling the size of the data we are talking about to ~30,000 items had no measurable difference that I could see.
Obviously, when you are talking about those numbers, an IN is probably not something that you want to use.










