There are some interesting discussions about the way Twitter is architected. Frankly, I think that having routine outages over such a long period is a sign of either negligence or incompetence. The problem isn't that hard, for crying out loud.
With that in mind, I set out to try architecting such a system. As far as I am concerned, twitter can be safely divided into two separate applications, the server side and the client side. The web UI, by the way, is considered part of the client.
The server responsibilities:
- Accept twits from the client, this include:
- Analyzing the message content, (@foo should go to foo, #tag should be tagged, etc)
- Forward the message to all the followers of the particular user
- Answer to queries about twits from people that a certain person is following
- Answer to queries about a person
- It should scale
- Clients are assumed to be badly written
The client responsibilities:
- Display information to the user
- Pretty slicing & dicing of the data
Obviously, I am talking as someone who knows that there is even the need to scale, but let us leave this aside.
I am going to ignore the client, I don't care much about this bit. For the server, it turn out that we have a fairly simple way of handling that.
We will split it into several pieces, and deal with each of them independently. The major ones are read, write and analysis.
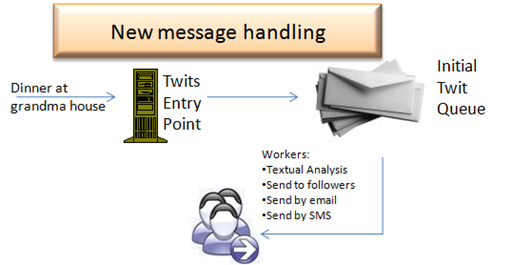 There isn't much need to deal with analysis. We can handle that using on the backend, without really affecting the application, so we will start with processing writes.
There isn't much need to deal with analysis. We can handle that using on the backend, without really affecting the application, so we will start with processing writes.
Twitter, like most systems, is heavily skewed toward reads. In addition to that, we don't really need instant responsiveness. It is allowed to take a few moments before the new message is visible to all the followers.
As such, the process of handling new twits is fairly simple. A gateway server will accept the new twit and place it in a queue. A set of worker server will take the new twits out of the queue and start processing them.
There are several ways of doing that, either by distributing load by function or by simple round robin. Myself, I tend toward round robin unless there is a process that is significantly slower than the others, or require extra requirements (sending email may require opening a port in the firewall, as such, it cannot run on just any machine, but only on machines dedicated to it).
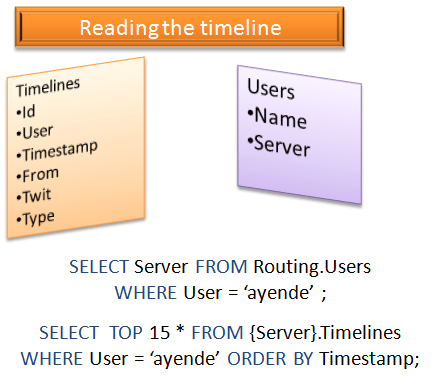 The process of handling a twit is fairly straightforward. As I mentioned, we are heavily skewed toward reads, so it is worth taking more time when processing a write to make sure that a read is as simple as possible.
The process of handling a twit is fairly straightforward. As I mentioned, we are heavily skewed toward reads, so it is worth taking more time when processing a write to make sure that a read is as simple as possible.
This means that our model should support the following qualities:
- Simple - Reading the timeline should involve no joins and no complexity whatsoever. Preferably, it should involve a query that uses a clustered index and that is it.
- Cacheable - There should be as few a factors that affects the data that we need to handle as possible.
- Shardable - the ability to split the work into multiple databases would mean that we will be able to scale out very easily.
As such, the model on the right seems like a good one (obviously this is very over simplified, but it works as an example).
This means that in order to display the timeline for a particular user, we will need to perform exactly two queries. One to the routing database, to find out what server this user data is sitting on, the second, to perform a trivial select on the timelines table.
What this means, in turn, is that the process for writing a new twit can be described using the following piece of code:
followers = GetFollowersFor(msg.Author)
followers.UnionWith( GetRepliesToIn(msg.Text) )
for follower in followers:
DirectPublish(follower, msg)
DirectPublish would simply locate the appropriate server and insert a new message, that is all.
If we will take a pathological case of someone who has 10,000 followers, what this means is that each time this person will publish a new twit, the writer section of the application will have to go and write the message 10,000 times. Ridiculous, isn't it?
Not really. This model allows us to keep very low contention, since we don't have any need for complex coordination, it is easily scalable for additional servers as needed, and it means that even in the case of several such pathological users suddenly starting to send high amount of messages, the application as a whole is not really affected. That is quite a side from the fact that inserting 10,000 rows is not really big. Especially since we are splitting it across several servers.
But if it really bothered me, I would designate separate machines for handling such high volume users. It will ensure that regular traffic in the site can still flow while some machine in the back of the data center is slowly processing the big volume. In fact, I would probably decide that it is worth my time using bulk insert techniques for those users.
All of that said, we now have a system where the database end is trivially simple (probably because the problem, as shown in this post, is trivial, I am pretty sure that the real world is more complex, but never mind that), scaling out the writing part is a matter of adding more workers to process more messages. Scaling out the database is a matter of putting more boxes in the data center, nothing truly complex. Scaling the read portion is a good place for judicious use of caching, but the model lends itself well for that.
Now, feel free to tell me what I am off the hook...






 in SvnBridge for a long while now.
in SvnBridge for a long while now.