I have been planning to check this out for a while now, but I seem to never get the time. Today I made time for this. As usual in such cases, this post is a stream of consciousness. You get my thoughts as I am thinking them.
Before trying to understand anything about NServiceBus, you probably need to understand a bit about distributed systems and messaging. NServiceBus is structured around a bus (into which you can put messages) and message handlers (which handles messages for you). On top of this very simple idea, everything else is built. This forces you to think in a way that makes a lot of sense in distributed, high scalability, scenarios. I got a lot of the concepts behind NServiceBus because I read Programming Erlang, in which the same concepts are explained beautifully.
Just to note, I am probably not going to make a lot of sense to people who are trying to understand NServiceBus. I am going to go over the code here. Which is how I learn new stuff.
Let us get to the review. The first thing that I noticed was this:

AllProjects is really all projects. That include samples, tests, extras, etc.
Looking into the NServiceBus project itself made me much calmer, I can handle this:
In fact, most of the projects contains very few files (one or two in many cases). This is probably done to allow you to pick & choose your dependencies, without having to deal with unrelated stuff.
BaseMessageHandler is a simple base class that simply define the Bus property.
This, however, is annoying.
I don't like to have camelCase exposed in my classes. Yes, it is just an issue of style, I know... The bracing styles in NServiceBus has a strange feel to it, but I have R#, and it can fix that ;-)
This is where the fun really starts:
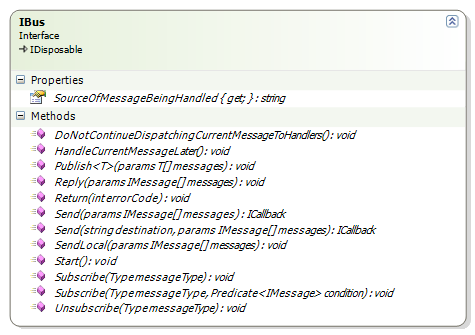
Publish and Subscribe looks remarkably like their equivalent in Retlang. Same model, after all.
I am not really sure about the difference between Publish and Send yet. And SendLocal doesn't really make any sort of sense yet.
I am not happy with Return(errorCode) either. I don't like using codes for errors, it reminds me when I had to interface to a mainframe, and 12 was corrupted file and 14 corrupted header, etc. Reading further into the code reveals that typical usage of this is with enum
HandleCurrentMessageLater is interesting, and I have seen some samples on Udi's blog on where it is used (handle the message after another transaction has finished running). Not sure what DoNotContinueDispatchingCurrentMessageToHandlers purpose is yet.
ICallback interface is interesting:
Need to check it out in more depth, when I figure it what you are registering for and the usage for that.
IMessage is a marker interface, nothing more.
There are a couple of interesting attributes as well:
- Recoverable - this is a durable message, and it should survive transient failures en route.
- TimeToBeReceived - what is the lifetime of this message. I am not really sure that this is a good way to specify this. I would assume that things like that are much more dynamic than the code. As a simple example, a burst scenario may cause high latency for processing work. I have a post dedicated to this issue here.
ReadyMessage (on the Messages.cs file) is interesting. I followed the references, but I don't think that I understand what is going on when it is handled.
Moving on, NServiceBus.Saga:
A saga is a way to handle a series of messages that are related to one another.
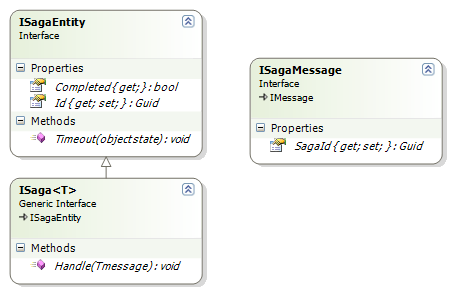
A good example may be submitting a order. It needs a manager authorization before it can be done. So you send a message for it to be approved, and you will only continue processing the order after you got the authorization message. Udi has a sample here.
The reason for the large numbers of projects, and the reason many of them contains only a single class or two becomes clear when you track down the classes that implements this bit:

I don't like either of the two implementers that are provided (not my style, basically), but it is going to be trivial to supply a new implementation that I would be happy with. I really like that ability. For that matter, the Persister.Deserialize() method is really fun to read. Really cool way to solve the problem.
Overall, I like the idea of Saga very much. It seems to me like there aren't really better alternative to Erlang's recieve keyword in C#.
Speaking of replacing the building blocks, NServiceBus use the following interface to abstract the container. You can usually guess what is the inspiration for the container abstraction. In this case, this is Spring.
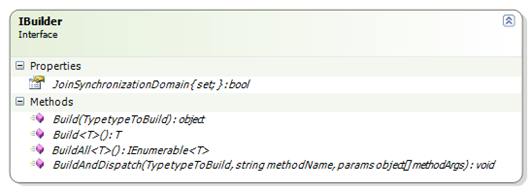
For using Windsor, we would need to write a simple adapter. (Basically mapping Build() calls to Resolve() calls).
The only really interesting bit is with BuildAndDispatch. This is how NServiceBus deals with making calls to generic interfaces without knowing up front what the generic parameter would be. I don't like it, but I don't see any other choice.
NServiceBus.Testing.
Not much to say about it, except that it is a great example of how much of a difference building an explicit interface for testing can make.
TimeoutMessageHandler made my head hurt. Go on, take a look. Now figure out what it does... The code is deceptively simple, because you have to think in terms of reentrancy.
I figured out what the ICallback is for, it is the result of the Send()
bus.Send(command).Register(cb, extraData);
Okay, that just about finishes with the core services that NServiceBus has to offer. Next, the infrastructure components are Transport and Bus, there is also the concept of a distributor, but I am not sure what this is, looks like the manager in a grid.
Transport is how NServiceBus abstract the details of the network communication.
Bus manages the messages, correlation, translation between transport messages and application message, dispatching to message handlers, etc.
There is also subscription manager and subscription storage, which I understand conceptually, but not in detail.
The distributor section of NServiceBus is a thing of beauty. Which I'll describe in the next post.

















