





The cost of select count(*) from tbl
I was always somewhat baffled that something that was so obviously required so often can be so expensive with RDBMSes. When diving deep into B-Tree implementation I suddenly found it obvious why that is the case.
Let us look at the following B-Tree:
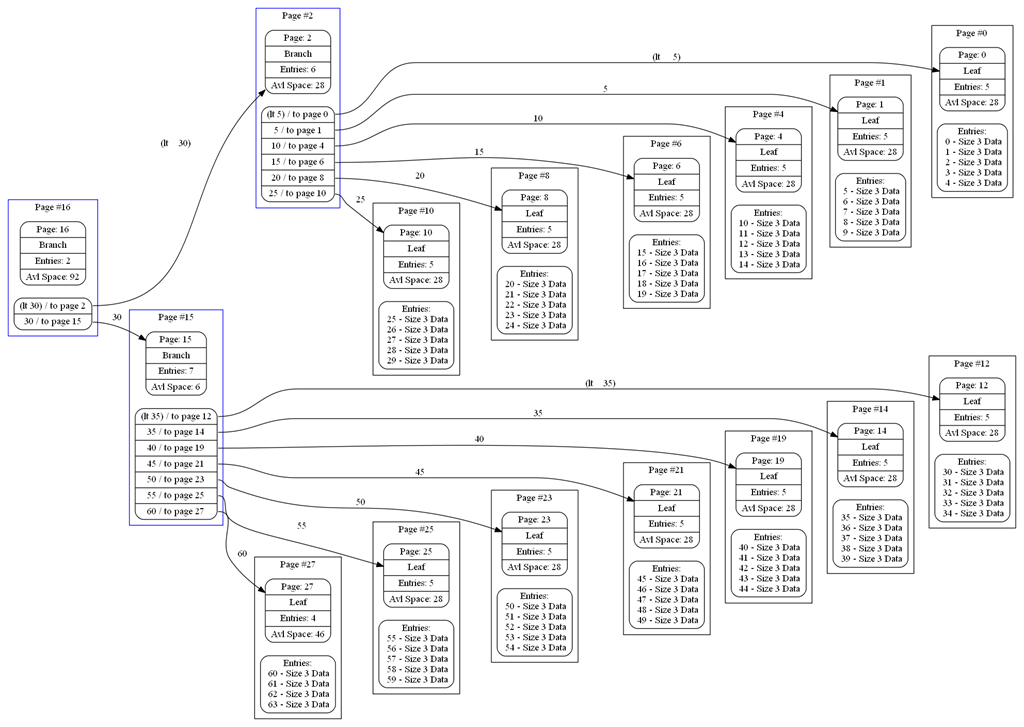
Now, if I asked you how many entries you had in this tree, you would have to visit each and every page. And that can be very expensive when you have large number of items.
But why can’t we just keep track of the total number ourselves? There is counting B-Trees that we can use that will give us the answer in O(1) time.
The answer to that is that it is too expensive to maintain this. Imagine a big tree, with 10 million records, and a fan out of 16 keys per page. That means that it has a depth of 6. Let us say that we want to add a new record. We can do that by modifying and saving the page. That would cost us 4KB of writes.
However, if we use a counting B-Tree, we have to update all of the parent pages. With a depth of 6, that means that instead of writing 4KB to disk we will have to write 24KB to disk. And probably have to do multiple seeks to actually do the write properly. That is an unacceptable performance cost, and the reason why you have to manually check all the pages when you want the full count.
Comments
Comment preview