I am having an interesting discussion in email with Evan Hoff, about the benefits of pub/sub architecture vs. request/reply. I want to state upfront that I see a lot of value in async one way messaging for a lot of the interactions in an application and across services. However, I am still skeptic about the push for pub/sub all the way.
To me, it seems like the request/reply model is a very natural one in many common scenarios. In most backend processing systems, I would tend to use pub/sub with sagas as both the easiest and most scalable solution. But in almost all cases that end up in the UI, this just doesn't make sense. Even if I want to fire several requests and then wait for all their reply, the model is still more natural than a pub/sub approach.
Note that the following code sample use imaginary API.
Let us go back to the displaying the available candidates. Using the request/reply model, I would have:
public void AvailableCandidates()
{
var specifications = BuildSpecifications();
var msg = bus.Process(new FindAvailableCandidateMessage(specifications));
DisplayResults(msg.Results);
}
All of those are using the request / reply model.
The pub/sub model will look somewhat like this:
public void AvailableCandidates()
{
var specifications = BuildSpecification();
bus.Publish(new FindAvailableCandidatesMessage(specifications))
.WaitForCallback(delegate(AvailableCandidatesMessage msg)
{
DisplayResults(msg.Results);
});
}
Or probably something like:
public void AvailableCandidates()
{
var specifications = BuildSpecification();
Guid correlationId = Guid.NewGuid();
ManualResetEvent waitForReply = new ManualResetEvent(false);
bus.SubscribeOnce<AvailableCandidatesMessage>(correlationId, delegate(AvailableCandidatesMessage msg)
{
DisplayResults(msg.Results);
waitForReply.Set();
});
bus.Publish(new FindAvailableCandidatesMessage(correlationId, specifications));
waitForReply.WaitOne();
}
Notice that I am not saying anything about the way those are handled once they leave the client. In fact, some of the reasons that were mentioned to favor the pub/sub model is the flexibility that you get when adding more functionality. Such as adding auditing, or redirecting messages to different services based on the type of candidate, etc.
The problem is that I see not inherent need for pub/sub to make this work. In fact, I think that anything that publish a message and than waits for the callback message is a big API issue, because this is request/reply, but with harder to use API. Even if you are doing the wait in async manner, I still think that this is a bad idea.
In the context of a request/reply interaction, we can handle everything the way we would handle any other message:
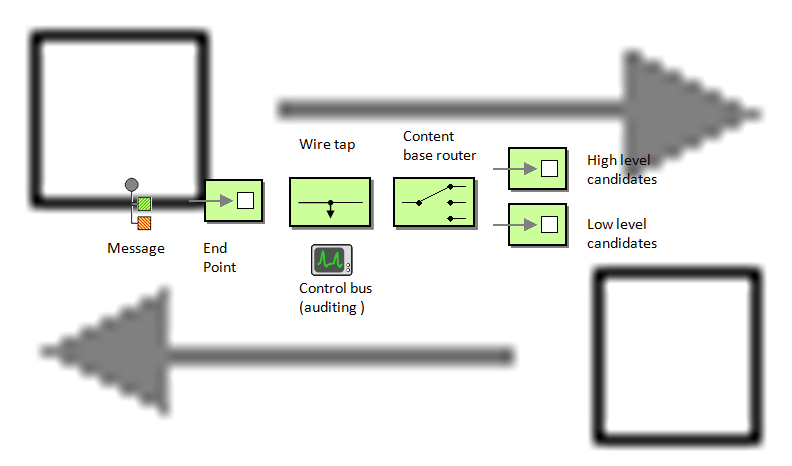
In fact, from the perspective of the infrastructure, there is little need to distinguish those. A message going out will go out either via a request/reply channel or a one way output channel, with a reply maybe arrived through a one way input channel. We don't really care about that.
From my point of view, it makes a lot more sense than to wait for a callback.
Thoughts?









