





Reading ErlangCouchDB - From REST to Disk in a few function calls
As you can probably figure out from the title, the purpose of this post is to track how CouchDB is saving a document on the disk. We have already tracked how much of CouchDB works, including some fascinating pieces such as btree:lookup and btree:query_modify. Now it is time to dig ourselves from the trenches and have a slightly higher level view of what is going on.
We start with the recently refactored couch_httpd_db module. The fun starts with handle_request.
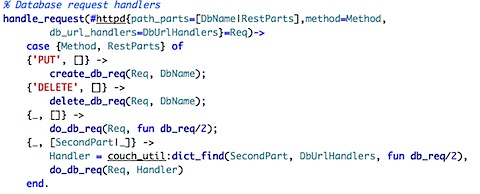
It took me a few seconds to realize what is going on here. Again, some of the problem is that I am not used to the function declaration being such an important role in the function behavior. In this case, the function declaration decompose the request into several parameters. The case statement is used to dispatch based on the arguments. If we have a PUT or DELETE requests with just the DB name, we know that we need to create/delete a database. Otherwise, we assume we have some other operation on the database directly, and we send a function for it to execute. The reason for that becomes clear when you check the rest of the code.

As we can see, the create_db_req and delete_db_req have different disposal semantics than do_db_req. do_db_req will just open/close the database and then execute the function in the cotext of this database handle.
This is quite a common pattern in functional programming, and it used frequently in Ruby. I am using it as much as I can in C# as well, since it is a very natural syntax to use with anonymous delegates and lambdas.
Anyway, what we are interested in today is the actual process of getting data from the request and putting it on the disk, so let us move along and see what is going on here. The next place of interest, of course, is db_req itself, which we pass into do_db_req. This is fairly interesting in its own, since it deals with all the commands that the server can support (from bulk_docs to compactions to purging). That isn't really interesting to me at this time, so we will move to the first code sample and look at the last clause.
This is where we are handling with a request for a specific document. couch_util:dict_find is where we need to look now...
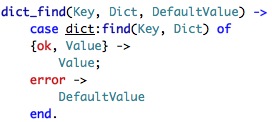
This is simply a way to do a lookup into a dictionary with a default value. So what does this code do?
![]()
Well, it lookup in the DbUrlHandlers (which we got passed to the method) and defaults to the db_req if it isn't found there. But what is this DbUrlHandlers? I'll save you the trouble of finding out on your own and guide us directly to the location that we care about. Here is a section from the couchdb.ini configuration:
[httpd_global_handlers]
/ = {couch_httpd_misc_handlers, handle_welcome_req, <<"Welcome">>}
_utils = {couch_httpd_misc_handlers, handle_utils_dir_req, "%localdatadir%/www"}
_all_dbs = {couch_httpd_misc_handlers, handle_all_dbs_req}
_config = {couch_httpd_misc_handlers, handle_config_req}
_replicate = {couch_httpd_misc_handlers, handle_replicate_req}
_uuids = {couch_httpd_misc_handlers, handle_uuids_req}[httpd_db_handlers]
_view = {couch_httpd_view, handle_view_req}
_temp_view = {couch_httpd_view, handle_temp_view_req}
If this looks like erlang code, you are almost right. This is actually just an .ini file, but it is format like erlang on purpose, since this is a simple mapping of a url to its handler in the code. This is a new extension mechanism to CouchDB that was added just yesterday.
This is a really nice way of handling extensibility, but enough beating around the bush, where is the save document code path? It starts with this function clause:
![]()
So we need to go to the do_doc_req to see what else is going on here. And in the db_doc_req, we just need to find the PUT handler, which will create a new document. And here it is:

Let us examine this in depth. couch_httpd:json_body(Req) just takes the request body and decode the JSON information there. I'll save you the way JSON is parsed using erlang. Suffice to say that I don't think it is pretty.
couch_doc:from_json_doc is interesting, though. First, take a look at this code:
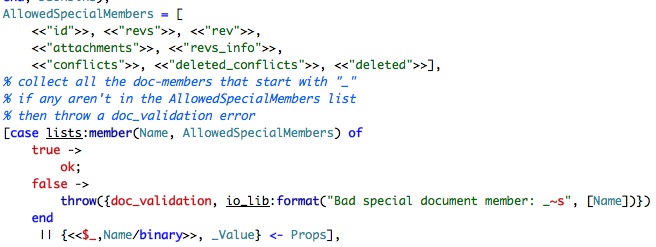
This is the equivalent of this code:
var allowedSpecialMembers = new[]{ /* see list above */ };
foreach(var prop in Props)
{
if( allowedSpecialMembers.Contains(prop)) continue;
throw new DocValidationexception('Bad special document member " + prop);}
The method is doing a few extra things that aren't really interesting to us at the moment, basically taking the JSON object that we got and turning that into this object:

Going back to db_doc_req, we can see that next we just get the appropriate revisions and then we extract the header revision, whatever that may be...
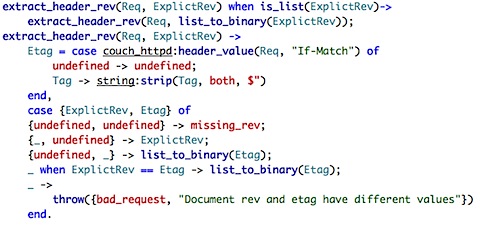
This is merely dealing with ensuring that if we specified the etag header, it will match the current revision. Not sure why this is important for PUT request, however. This make sense for POST (update) request, however. Taking that as a given, we then call update_doc (which seems to serve double duty as create_doc) and send as JSON response back to the user.
This means that we finally have a lead, and can move from couch_httpd_db to couch_db :-)
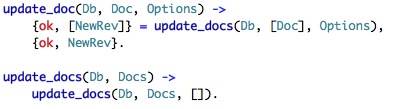
update_doc just forward the call to update_docs (plural). That should be interesting, but it wouldn't be today.
More posts in "Reading Erlang" series:
- (04 Oct 2008) CouchDB - From REST to Disk in a few function calls
- (24 Sep 2008) Inspecting CouchDB
Comments
Comment preview