I like the ideas that Erlang promotes, but I find myself in a big problem trying to actually read Erlang. That is, I can read sample code, more or less, but real code? Not so much. I won't even touch on writing the code.
One of the problems is the lack of IDE support. I tried both ErlIDE and Erlybird, none of them gave me so much as syntax highlighting. They should, according to this post, but I couldn't get it to work. I ended up with Emacs, which is a tool that I just don't understand. It supports syntax highlighting, which is what I want to be able to read the code more easily, so that is fine.
Emacs is annoying, since I don't understand it, but I can live with that. The source code that I want to read is CouceDB, which is a Document DB with REST interface that got some attention lately. I find the idea fascinating, and some of the concepts that they raise in the technical overview are quite interesting. Anyway, I chose that to be the source code that will help me understand Erlang better. Along the way, I expect to learn some about how CouchDB is implemented.
Unlike my usual code reviews, I don't have the expertise or the background to actually judge anything with Erlang, so please take that into account.
One of the things that you notice very early with CouchDB is how little code there is in it. I would expect a project for a database to be in the hundreds of thousands of lines and hundreds of files. But apparently there is something else going on. There are about 25 files, the biggest of them being 1,200 lines or so. I know that the architecture is drastically different (CouchDB shells out to other processes to do some of the things that it does), but I don't think it is just that.
As usual, I am going to start reading code in file name order, and jump around in order to understand what is going on.
couch_btree is strange, I would expect Erlang to have an implementation of btree already. Although, considering functional languages bias toward lists, it may not be the case. A more probable option is that CouchDB couldn't use the default implementation because of the different constraint it is working under.
This took me a while to figure out:

The equivalent in C# is:
public class btree
{
fd, root;
extract_kv = (KeyValuePair kvp) => kvp;
assemble_kv = (KeyValuePair kvp) => kvp;
less = (a, b) => a < b;
reduce = null
}
public object Extract(btree, val)
{
return btree.extract_kv(val);
}
The ability to magically extract values out of a record make the code extremely readable, once you know what is going on. I am not sure why the Extract variable is on the right side, but I can live with it.
Here is another piece that I consider extremely elegant:

You call set_options with a list of tuples. The first value in each tuple is the option you are setting, the second is the actual value to set. This is very similar to Ruby's hash parameters.
Note how it uses recursion to systematically handle each of those items, then it call itself with the rest of it. Elegant.
It is also interesting to see how it deals with immutable structure, in that it keeps constructing new ones as copy of the old. The only strange thing here is why we map split to extract and join to assemble. I think it would be best to name them the same.
There is also the implementation of reduce:

This gave me a headache for a while, before I figured it out. Let us say that we are calling final_reduce with a binary tree and a value. We expect that value to always be a tuple of two lists. We call the btree.reduce function on the value. And this is the sequence of operations that is going on:
- if the value is two empty lists, we call reduce with an empty list, and return its value.
- if the value is composed of an empty list and a list with a single value, then we have reduced the value to its final state, and we can return that value.
- if the value is an empty list and a list of reduced values, we call reduce again to re-reduce the list, and return its value.
- if the value is two lists, we call reduce on the first and prepend the result to the second list. Then we call final_reduce again with an empty list and the new second list.
Elegant, if you can follow what is going on.
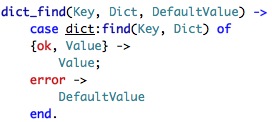
There is a set of lookup functions that I am not sure that I can understand. That seems to be a problem in general with the CouchDB source code, there is very little documentation, and I don't think that it is just my newbie status at Erlang that is making this difficult.
I got up to get_node (line 305) before I realized that this isn't actually an in memory structure. This is backed by couch_file:pread_term, whatever that is. And then we have write_node. I am skipping ahead and see things like reduce_stream_kv_node2, which I am pretty sure are discouraged in any language.
Anyway, general observation tells me that we have kvnode and kpnode. I think that kvnode is key/value node and kpnode is key/pointer node. I am lost beyond that. Trying to read a function with eleven arguments tax my ability to actual understand what each of them is doing.
I found it very interesting to find test functions at the end of the file. They seem to be testing the btree functionality. Okay, I am giving up on understanding exactly how the btree works (not uncommon when starting to read code, mind you), so I'll just move on and record anything new that I have to say about the btree if I find something.
Next target, couch_config. This one actually have documentation! Be still, my heart:

Not sure what an ets table is, mind you.
couch_config is not just an API, like the couch_btree is. It is a process using Erlang's OTP in order to create an isolate process:

gen_server is a generic server component. Think about this like a separate process that is running inside the Erlang VM.
Hm, looks like ets is an API to handle in memory databases. Apparently they are implemented using Judy Arrays, a data structure implementation that aims to save in cache misses on the CPU.
This is the public API for cache_config:
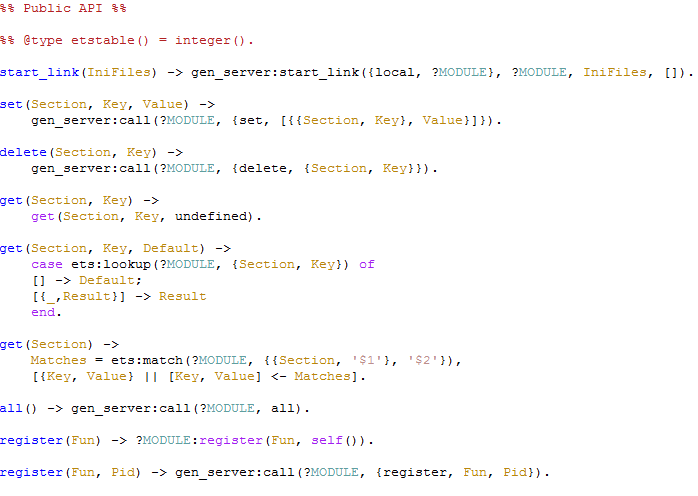
It is a fairly typical OTP process, as far as I understand. All calls to the process are translated to messages and sent to the server process to handle. I do wonder about the ets:lookup and ets:match calls that the get is making. I assume that those have to be sync calls.
Reading the ini file itself is an interesting piece of code:

In the first case, I am no sure why we need io:format("~s~n", [Msg]), that seems like a no op to me. The file parsing itself (the lists:foldl) is a true functional code. It took me a long time to actually figure out what is going on with there, but I am impressed with the ability to express so much with so little code.
The last line uses a list comprehension to write all the values to the ets table.
On the other hand, it is fairly complex, for something that procedural code would handle with extreme ease and be more readable.
Let us take a look at the rest of the API, okay?

This is the part that actually handles the calls that can be made to it (the public API that we examined earlier). Init is pretty easy to figure out. We create a new in memory table, load all the the ini files (using list comprehension to do so).
The last line is interesting. Because servers needs to maintain state, they do it by always returning their state to their caller. It is the responsibility of the Erlang platform (actually, I think it is OTP specifically) to maintain this state between calls. The closest thing that I can think of is that this is similar to the user's session, which can live beyond the span of a single request.
However, I am not sure how Erlang deals with concurrent requests to the same process, since then two calls might result in different state. Maybe they solve this by serializing access to processes, and creating more processes to handle concurrency (that sounds likely, but I am not sure).
The second function, handle_call of set will call insert_and_commit, which we will examine shortly, and just return the current state. The function handle_call of delete is pretty obvious, I think, as is handle_call of all.
handle_call of register is interesting. We use this to register a callback function. The first thing we do is setup a monitor on the process that asked us for the callback. When that process goes down, we will be called (I'll not show that, it is pretty trivial code).
Then we prepend the new callback and the process id to the notify_funs variable (the callbacks functions) and return it as the new state.
But what are we doing with those?

Well, we call them in the insert_and_commit method. The first thing we do is insert to the table, then we use list comprehension over all the callbacks (notify_funs) and call them. Note that we use a catch block there to ignore errors from other processors. We write the newly added config item to file as well, on the last line.
And this is it for couch_config. couch_config_writer isn't really worth talking about. Moving on to the first item of real meat. The couch_db.erl file itself! Unsurprisingly, couch_db, too, is an OTP managed process. And the first two functions in the file tell us quite a bit.

catch, like all things in Erlang, is an expression. So start_link will return the error, instead of throwing it. I am not quite sure why this is used, it seems strange, like seeing a method whose return type is System.Exception.
start_link0, however, is interesting. couch_file:open returns an Fd, I would assume that this is a File Descriptor, but the call to unlink below means that it is actually a process identifier, which means that couch_file:open creates a new process. Probably we have a process per file. I find this interesting. We have seen couch_file used in the btree, but I haven't noticed it being its own process before.
Note the error recovery for file not found. We then actually start the server, after we ensure that the file exists and valid, delete the old file if exists, and return.
We then have a few functions that just forward to the rest of couch_db:

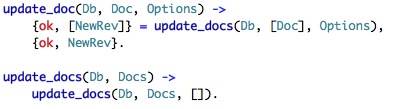
Looks like those are used as a facade. delete_doc is funny:

I am surprised that I can actually read this. What this does is create a new document document for all the relevant versions that were passed. I initially read it as modifying the doc and using pattern matching to do so, but it appears that this is actually creating a new one. I hope that I'll be able to understand update_docs.
In the meantime, this is fairly readable, I think:
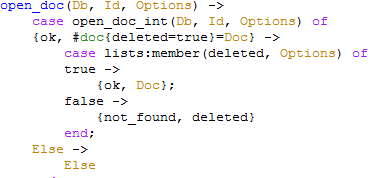
This translate to the following C# code:
public var open_doc(var db, var id, var options)
{
var doc = open_doc_internal(db,id,options);
if(doc.deleted)
{
if (options.Contains("deleted"))
return doc;
return null;
}
return doc;
}
About the same line count. And I am not sure what is more readable.
I am skipping a few functions that are not interesting, but I was proud that I was able to figure this one out:
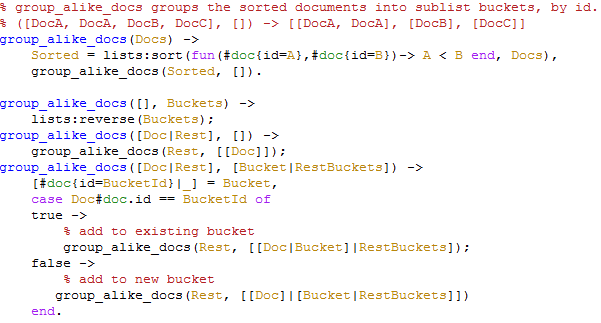
We start with a sorted list of documents, which we pass to group_alike_docs/2:
- if the first arg is an empty list, return the reserved list from the second arg.
- If the first argument is a list with value, and the second one is an empty list, create a new bucket for that document, and recurse.
If both lists are not empty, requires its own explanation. Note this piece of code:
[#doc{id=BucketId}|_] = Bucket,
This is the equivalent of the following C# code:
var BucketId = Bucket.First().Id;
Now, given that, we can test if the bucket it equals to the current document it. If it is, we add it to the existing bucket, if it is not, we create new one. The syntax is pretty confusing, I admit, but it make sense when you realize that we are dealing with a sorted list.
By this time I am pretty sure that you are tired of me spelling out all the CouchDB code. So I'll only point out things that are of real interest.
couch_server is really elegant, and I was able to figure out all the code very easily. One thing that is apparent to me is that I don't understand the choice of using sync vs. async calls in Erlang. couch_server is all synchronous calls, for example.
That is all for now, I reviewed couch_file as well, and I think that I need to go back to couch_btree to understand it more.
couch_ft_query is very interesting. It is basically a way to shell out to an external process to do additional work. This fits very well with the way that Erlang itself works. What seems to be going on is that full text search is being shelled elsewhere, and the result of calling that javascript file is a set of doc id and score, which presumably can be used later to get an ordered list from the database itself.
This seems to indicate that there is a separate process that handles the actual indexing of the data (Lucene / Solar seems to be a natural choice here). It isn't currently used, which maps to what I know about the current state of CouchDB. It is interesting to note that Lucene is also a document based store.
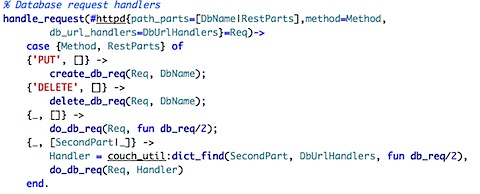
Moving on, couch_httpd is where the dispatching of all commands occur. I took only a single part, which represent most of how the code looks like in this module:

I really like the way pattern matching is used here. Although I must admit that it is strange to see function declaration being used as logic.
couch_view is the one that is responsible for views, obviously. I can't follow all it is doing now, but it is shelling out some functionality to couch_query_servers, which is shelling the work, in turn, to... a java script file. This one, to be precise. CouchDB is using an external process in order to handle all of its views processing. This give it immense flexibility, since a user can define a view that does everything they want. Communication is done using standard IO, which surprised me, but seems like the only way you could do cross platform process communication. Especially if you wanted to communicated with java script.
All in all, that has been a very interesting codebase, that is all for now...
For the single reader who actually wade through all of that, thanks.