





reWhy You Should Never Use MongoDB
I was pointed at this blog post, and I thought that I would comment, from a RavenDB perspective.
TL;DR summary:
If you don’t know what how to tie your shoes, don’t run.
The actual details in the posts are fascinating, I’ve never heard about this Diaspora project. But to be perfectly honest, the problems that they run into has nothing to do with MongoDB or its features. They have a lot to do with a fundamental lack of understanding on how to model using a document database.
In particular, I actually winced in sympathetic pain when the author explained how they modeled a TV show.
They store the entire thing as a single document:
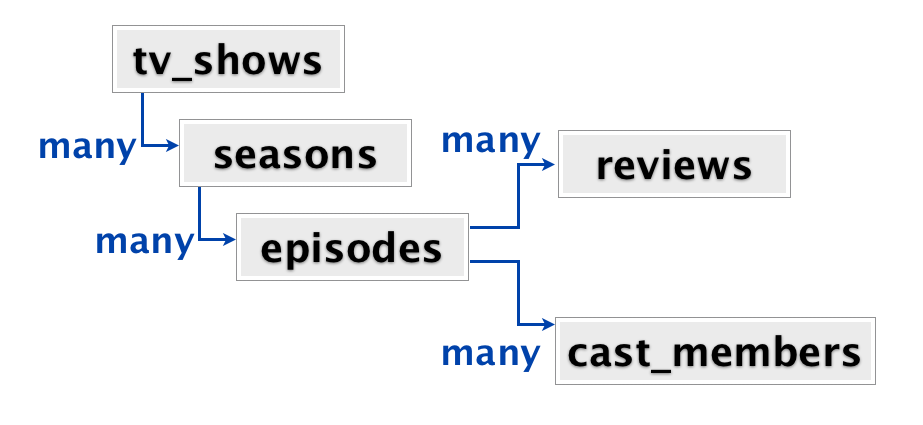
Hell, the author even talks about General Hospital, a show that has 50+ sessions and 12,000 episodes in the blog post. And at no point did they stop to think that this might not be such a good idea?
A much better model would be something like this:
- Actors
- [episode ids]
- TV shows
- [seasons ids]
- Seasons
- [review ids]
- [episode ids]
- Episodes
- [actor ids]
Now, I am not settled in my own mind if it would be better to have a single season document per season, containing all episodes, reviews, etc. Or if it would be better to have separate episode documents.
What I do know is that having a single document that large is something that I want to avoid. And yes, this is a somewhat relational model. That is because what you are looking at is a list of independent aggregates that have different reasons to change.
Later on in the post the author talks about the problem when they wanted to show “all episodes by actor”, and they had to move to a relational database to do that. But that is like saying that if you stored all your actors information as plain names (without any ids), you would have hard time to handle them in a relational database.
Well, duh!
Now, as for the Disapora project issues. They appear to have been doing some really silly things there. In particular, let us store store the all information multiple times:

You can see for example all the user information being duplicated all over the place. Now, this is a distributed social network, but that doesn’t call for it to be stupid about it. They should have used references instead of copying the data.
Now, to be fair, there are very good reasons why you’ll want to duplicate the data, when you want a point in time view of it. For example, if I commented on a post, I probably want my name in that post to remain frozen. It would certainly make things much easier all around. But if changing my email now requires that we’ll run some sort of a huge update operation on the entire database… well, it ain’t the db fault. You are doing it wrong.
Now, when you store references to other documents, you have a few options. If you are using RavenDB, you have Include support, so you can get the associated documents easily enough. If you are using mongo, you have an additional step in that you have to call $in(the ids), but that is about it.
I am sorry, but this is blaming the dancer blaming the floor.
More posts in "re" series:
- (05 Dec 2025) Build AI that understands your business
- (02 Dec 2025) From CRUD TO AI – building an intelligent Telegram bot in < 200 lines of code with RavenDB
- (29 Sep 2025) How To Run AI Agents Natively In Your Database
- (22 Sep 2025) How To Create Powerful and Secure AI Agents with RavenDB
- (29 May 2025) RavenDB's Upcoming Optimizations Deep Dive
- (30 Apr 2025) Practical AI Integration with RavenDB
- (19 Jun 2024) Building a Database Engine in C# & .NET
- (05 Mar 2024) Technology & Friends - Oren Eini on the Corax Search Engine
- (15 Jan 2024) S06E09 - From Code Generation to Revolutionary RavenDB
- (02 Jan 2024) .NET Rocks Data Sharding with Oren Eini
- (01 Jan 2024) .NET Core podcast on RavenDB, performance and .NET
- (28 Aug 2023) RavenDB and High Performance with Oren Eini
- (17 Feb 2023) RavenDB Usage Patterns
- (12 Dec 2022) Software architecture with Oren Eini
- (17 Nov 2022) RavenDB in a Distributed Cloud Environment
- (25 Jul 2022) Build your own database at Cloud Lunch & Learn
- (15 Jul 2022) Non relational data modeling & Database engine internals
- (11 Apr 2022) Clean Architecture with RavenDB
- (14 Mar 2022) Database Security in a Hostile World
- (02 Mar 2022) RavenDB–a really boring database
Comments
I think one point from this is that, those new to NoSQL see the no relational aspect of it and think everything should be put in one document. I think there is a lack of material to guide those coming from SQL on how to best model their data and I believe if said material appeared it would be extremely helpful and an instant success.
i know you're going to code a demo version of the tv show app in raven
So in short you want people to store information in entities which resemble a more or less relational model? Tell me why people have to abandon their RDBMSs again?
Jonathan, watch out for the 5th chapter of "RavenDB in Action" titled "Document oriented modelling" due to be released this month to MEAP.
It is specific to RavenDB, but does go in length about doc-oriented modelling in general as well, with or without previous experience with RDBMS
http://manning.com/synhershko/
Reading the original blog post was really painful, like watching people in horror movies going alone in a dark, dirty tunnel without weapons hoping it will all ends well. And you are there on your couch thinking "oh c'mon! really? stop doing that, it doesn't make sense, stop!". But then again, it's a horror movie, so you now how things are going to end...
You've basically made a relational model which is badly normalised (Have to update actors every time a season is added). I agree that this is better than the original design but doesn't seem to be giving any benefit over a relational database.
What puzzles me is that that blog post seems to only talk about loading documents, as if that's the only form of querying a document store. What about using map/reduce to generate different read models, like for the "all actors in a movie" query?
Thats why is so hard to move to NoSQL. How can I ensure I modeling it in right way?
Or worse, how can I ensure that model is "future proof"? Modeling a Car Table will always be a Car Table, no matter how I use it
Very interesting article. The post name is a bit sensationalist thought (I know it's a copy of the original post name) . It should be something like "Why should you never use a document store if you don't know how to use it" :)
Frans, No, that isn't the case. But you need to respect aggregate boundaries. For example, an Order document would embed the order lines, but will not embed the product data.
" ... but will not embed the product data." depends. there are many situations whet it will. Ex. VAT/Sales Tax charged per item at that time.
Dorin, shouldn't that part of the order line then? I mean, the product doesn't change just because the VAT rules in your country differ from mine, right?
And unless you want to end up in a fight with your accountant (you don't), your order line will include the final price anyway. Just quantity and item price is not enough.
One thing I've learned: the data will outlive the application. That's the main reason why you want it to be organized independently of how it happens to be useful for the first application. In other words, you want it normalized because at some point someone will want to query / update it in a totally different way than you've organized it initially.
Relational databases were invented specifically to fix the problem caused by the previously-existing hierarchical databases; I don't know why people think going back to those is in any way an improvement.
Ayende, this time :) you are absolutely right. The point isn't "MongoDB yes or no", but how you model your documents. The mistake is this.
Marcel, at some point when someone will update db in a totally different way than you've organized it initially, this operation will broke something, independently from what kind of storage you use.
@Marcel,
In our experience (wall st brokerage) an ideally normalized schema has never actually been used, for that either leads to joins involving insane numbers of tables or implicit joins using a zillion views etc. The bread-and-butter everyday coding is always against data that has been denormalized to a greater or lesser degree. Disk space is usually easy to get as required, but brainpower to debug huge stored procs written years ago is not always to be taken for granted.
In my manager's office is posted a huge diagram of a rewrite of the company name and address store (which is currently based off a denormalized mainframe dump) as Codd himself would be proud of. Fortunately it has remained unimplemented.
Patrick, in the same country , Some products may have different VAT
Hmm. I have worked for a company that has extensive financial data on everyone in the US (around 300 million people) and also on people in a lot of other countries. TBs of data. I have never, in 15 years, had problems because of the data being normalized. I'm talking sub-second queries retrieving financial history with sub-queries calling web-services.
I have ALWAYS had problems because of it being denormalized. Some of the programmers thought 1NF was too much and kept multiple values in the same field, delimited with commas, except when commas were part of the field value in which case the tilde character was used, except when...
Oh, I have also worked indirectly for a company doing financial transactions (Brownstone). Again, data being normalized = great; data being denormalized = who the fsck came up with this crap?
Maybe we just had fast computers :)
@Marcel,
I agree with @Peter, having worked in large banking extensively, normalized data is often unworkable, and an unachievable goal - see the data warehouses utopia.
Especially when you talk about multi-service/department data, you cannot really all normalize them together for multiple reasons (and 90% of those reasons are actually not technical), and if you are able to come close, they are unworkable by everyone equally for many reasons.
Having each services being responsible of it's own data (boundary) and making data available to others in multiple formats (REST, Reports, CSV, SQL, multi-dimension(Cube), etc.) is probably the best way to go about it, and NoSQL could help you manage it efficiently. There is no reason you cannot run NoSQL and export relevant 'resulting' data (stats, accounting, logs, etc.) in SQL or another shareable format, if that makes sense for your needs.
But building your whole systems on that 'shareable' format (SQL) ONLY because it makes it easier to share it/reuse it later is as wrong as using NoSQL for highly relational data or doing what they did in the blog article. Each has it's uses, each are very good doing what they do, but you must choose wisely, and that part is not always obvious.
Every choices have tradeoffs, and our job is to juggle with them and find the best middle ground and manage all those risks.
@Marcel,
Seems like your situation is working on historical data that aren't dynamic and do not change (a lot), which having it all normalized makes a lot of senses. Normalized relational data is very good for that kind of dataset.
Working directly on realtime transactional data, or multisegment data integration between multiple systems/providers, is another beast tho, and often normalized data is a problem in that case.
Just to show that there is no silver bullet.
@marcel
We do not have performance issues with normalized data, and we have constant issues with bad data from denormalized sources. I didn't state otherwise. Who came up with this carp? People who were around with mainframes decades ago. We have a broker still working since 1965. Brownstone was founded in 1998, which means they have less legacy detritus hanging around. As I said, we have a resource limitation maintaining code going against too-purely-normalized schema. It is not feasible to enter all the data again, and it is being scrubbed slowly as we go along, and the thousands of cobol programs on the backend are slowly being migrated.
I don't disagree with the idea that you cannot normalize the data... but I believe (and I admit I could be wrong) that the reasons are social rather than technical most of the time. In any case, as I said, I could be wrong and both of you definitely seem to have a lot more experience with large and/or time-critical databases than I do. (For example, I hate stored procedures with a fiery passion.)
Going back to the topic, though, I am still waiting for a good reply to Frans' question: if you have to store IDs in the database anyway, and do joins, why not use a RDBMS in the first place?
@Marcel
I believe ayende or someone else in the comments made a comment along the lines of you are storing aggregate roots which would seem to align well with DDD and services.
Ayende hit the nail on the head: "you need to respect aggregate boundaries."
This is so crucial to data modeling, document or relational. Even though DDD is no longer the flavor of the month, it's lessons are just as important. Data churn falls along certain boundaries that are specific to a business, not universally absolute. (And this holds for relational normalization. For example, it is not a given that an address should be pulled out of a table if it will never change on its own. This is no different than the fact that common surnames aren't normalized, and cities and states aren't normalized out of addresses.) Data modeling is always subject to value perceived by the specific business/domain. When change boundaries encompass some hierarchy, there's no reason to panic! The right choice in this case is to use a semi-structured column type (xml/hstore), or a doc store.
It may be prudent to worry about the data outlasting the app, but that just means one should ensure that the data in some usable, understood format. It's usually wasteful to worry about the data outlasting the business (and the value perceived by it), so carelessly/naively normalizing everything is the data modeling version of YAGNI.
To argue about data modeling without recognizing that normalization is business-specific is as much of a waste of time as is complaining about document stores without understanding aggregates.
"Relational databases were invented specifically to fix the problem caused by the previously-existing hierarchical databases; I don't know why people think going back to those is in any way an improvement."
@Marcel this is false. Relational databases were created because the cost of a gigabyte in even just 1980 was over $400,000. RDBMS were created to solve the problem of do not copy anything, store the most densest amount data you can possibly fit per kilobyte of storage.
Storage now is cheap. I will choose duplication far more than i will choose normalization.
The reason to not choose a RDBMS is that it assumes EVERYTHING is a relationship. Relationships in your data are some of the most important design decisions you will ever make. With non-relational systems, they force you to think very hard about them and if you choose wrong, it does bite you. RDBMS on the other hand dictates you must obey them and everything is a relationship... up until people start using it non-relational and storing CSV data, JSON data, or other loose schema data inside the tables themselves.
@Chris Storage is cheap so let's use it all and then pay for 10 more servers for sharding. We're Big Data, normalization is silly and looks unprofessional ;)
@Rafal did i say denormalize everything, copy everything over and over? It's about making the right choices. Note, the right answer very well might be copy everything onto 10 shards and have an amazingly high level of throughput.
As with everything in software, IT DEPENDS.
"Relational databases were created because the cost of a gigabyte in even just 1980 was over $400,000."
No this is completely false. Hierarchical databases had the concept of keys and could be normalized if needed, all this talk of aggregate roots was well known back in the 1960s, lookup root segments in IBM's IMS database. These old hierarchical databases where fixed schema as well so they did not have to redundantly store fields names with every value as well like Mongo and Raven do wasting tons of disk space and I/O and ram so you can keep your schema in app code rather than the db. They used disk space just as efficiently as any relational db if not more so because parent child relationships used compact internal data structures(offsets and pointers).
There is plenty of documented history on why the relational model was created and it had nothing to do with disk space. Start with EF Codds orginal paper: http://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
So this is your response from the RavenDB perspective, eh? All hat and no cattle, dude.
@Justin thanks... yea, I have no idea where the "because of storage costs" came from.
@Chris - relations in the relational model are not what you think. "Relation" is what we nowadays call table. Please don't skip the basics, they're there for a reason :)
@Mike - "For example, it is not a given that an address should be pulled out of a table if it will never change on its own." Right, with just a tiny small observation: addresses ALWAYS change on their own.
Incidentally, I feel like this is a good place to point out Patrick's list of "falsehoods people believe about names" - http://www.kalzumeus.com/2010/06/17/falsehoods-programmers-believe-about-names/ - it applies equally to addresses.
The name of my street changed three times since I was born, for example. The name of my COUNTRY changed once.
Again: data outlives applications. We're programmers, we know excessive coupling is bad; that also applies to the code/data interface.
@Josh - If I interpret Ayende's answer correctly, he's advocating for a semi-normalized model - not a full hierarchical one but not a fully normalized one either. I don't see the advantages but I'm accepting that it might be my fault.
@Marcel, @Mike
I think you have a different definition of an address. I guess @Mike is talking just about the "street 42" part, while @Marcel seems to think about the whole shebang including city and postal code.
@Marcel said "In other words, you want it normalized because at some point someone will want to query / update it in a totally different way than you've organized it initially."
This sounds a lot like Greg Young's arguments for Event Sourcing.
I find ES a more compelling solution to that problem than rdbms. Update == Delete.
Have to agree with Frans on this one. This is a bad example for a document database in general, and Ayende's solution is no solution at all. "But you need to respect aggregate boundaries." - And what are those boundaries? Actors need episodes and episodes need actors. If you change one, you need to go through and sync the relationship between the two.
"For example, an Order document would embed the order lines, but will not embed the product data." - yes, orders and order lines "work"... Products is "iffy" unless the product edits result in new references; but this example was not about orders and order lines so this doesn't explain respecting aggregate boundaries in the context of the problem at hand.
@Kijana I actually think event sourcing is a fantastic idea, and I would love to get some experience with it... I just need to find the right project for it I guess.
@Steve - yes Ayende's model does not respect boundaries. Actors should not contain episode ids.
Seems like some people think to use a document database means to denormalize your data. This is an orthogonal issue. The main advantage of a document db is that it allows you to store collections within the document.
In the above example we can store the Actor IDs inside the Episode document. With SQL, we would need another table and would get into locking issues, as multiple Episodes would share that table.
@Jon "Seems like some people think to use a document database means to denormalize [ALL] your data. This is an orthogonal issue."
Very well said, they are completely orthogonal.
I agree with the others saying that doing modelling right with a document database is a hard thing to do. Partly this is because most people don't have experience with document databases yet.
I think in web applications, one key should be what data do I need for the use cases I want to provide. This should naturally yield you some root aggregates.
In the example above, I might want to have a list of all series, where I need names, etc., but I also might want to show a page of a single chapter, where I don't need all the other information.
If I need to query 100 documents to show a single page, I'm probably doing something wrong. Equally if I query a single document but only use 1% of the information contained, I'm also probably doing something wrong.
Comment preview