





 I talked a lot about how graph queries in RavenDB will work, but one missing piece of the puzzle is how they are going to be used. I’m going to use this post to discuss some of the options that the new features enables. We’ll take the following simple model, issue tracking. Let’s imagine that a big (secret) project is going on and we need to track down the tasks for it. On the right, you have an image of the permissions graph that we are interested in.
I talked a lot about how graph queries in RavenDB will work, but one missing piece of the puzzle is how they are going to be used. I’m going to use this post to discuss some of the options that the new features enables. We’ll take the following simple model, issue tracking. Let’s imagine that a big (secret) project is going on and we need to track down the tasks for it. On the right, you have an image of the permissions graph that we are interested in.
The permission model is pretty standard I think. We have the notion of users and groups. A user can be associated to one or more groups. Groups memberships are hierarchical. An issue’s access is controlled either by giving access to a specific users or to a group. The act of assigning a group will also allow access to all the group’s parents and any user that is associated to any of them.
Here is the issue in question:

Given the graph on the right, let’s see, for each user, how we can find out what issues they have access to.
We’ll start with Sunny, who is named directly in the issue as allowed access. Here is the query to find the issues on which we are directly named.

This was easy, I must admit. We could also write this without any need for graph queries, because it is so simple:

It gets a bit trickier when we have to look at Max. Unlike Sunny, Max isn’t directly named. Instead, he is a member in a group that is directly named in the issue. Let’s see how we can query on issues that Max has access to:

This is where things gets start to get interesting. If you’ll look into the match clause, you’ll see that we have arrows that go both left and right. We are telling RavenDB that we want to find issues that have the same group (denoted as g in the query) as the user. This kind of query you already can’t express with RavenDB right now without the graph query syntax. Another way to write this query is to use explicit clauses, like so:

In this case, all the arrows go in a single direction, but we have two clauses that are being and together. These two queries are exactly the same, in fact, RavenDB will translate the one with arrows going both ways to the one with the and.
The key here is that between any two clauses with an and, RavenDB will match the same alias to the same value.
So we now can find issues for Max and Sunny, but what about all the rest of the people? We can, of course, do this manually. Here is how we can find issues for people a group removed from the issue.

This query gives us all the issues for Nati that are one group removed from him. That works, but it isn’t how we want to do things. It is a good exercise in setting out the structure, though. Because instead of hard coding the pattern, we are now going to use recursion.

The key for this query is the recursive element in the third line. We moved from the issue to its groups, and then we recurse from the issues’ groups to their parents. We allow empty recursion and we follow all the paths in the graph.
On the other side, we go from the user and try to find a match from the user’s group to any of the groups that end the query. In Nati’s case, we went from project-x group to team-nati, which is a match, so we can return this issue.
Here is the final query that we can use, it is a bit much, even if it is short, so I will deconstruct it below:

We use a parameterized query here, to make things easier. We start from a user and find an issue if:
- The issue directly name the user as allowed access. This is the case for Sunny.
- The issue’s groups (or their parents) match the groups that the user belong to (non recursively, mind).
In the case of Max, for example, we have a match because the recursive element allows a zero length path, so the project-x group is allowed access and Max is a member of it.
In the case of Nati, on the other hand, we have to go from project-x to team-nati to get a match.
If we’ll set $uid to users/23, which is Pheobe, all the way to the left in the graph, we’ll also have a match. We’ll go from project-x to execs to board and then find a match.
Snoopy, on the other hand, doesn’t have access. Look carefully at the direction of the arrows in the graph. Snoopy belongs to the r-n-d group, and that groups is a child of exces, but the query we specified only go up to the parents, not the children, so Snoopy is not included.
I hope that this post gave you some ideas about what kind of use cases are enabled by graph queries in RavenDB. I would love to hear about any scenarios you have for graph queries so we can play with them and see how they are answered by RavenDB.
 Graph queries as I discussed them so far gives you the ability to search for patterns. On the right, you can see the family tree of the
Graph queries as I discussed them so far gives you the ability to search for patterns. On the right, you can see the family tree of the 










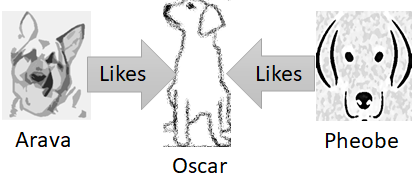 An interesting challenge with implementing graph queries is that you sometimes get into situations where the correct behavior is counter intuitive.
An interesting challenge with implementing graph queries is that you sometimes get into situations where the correct behavior is counter intuitive. 
























{kind=link}