





Data Layer Componentization
Alex is talking about Data Layer Componentization, as it works in Base4 and apparently in the Entity Framework as well.
A data-layer component simply allows for information to be shared between different applications.
By supporting re-use data layer componentization allows you to break the duplication habit. You can still have silos, but the natural tendency to duplicate data disappears. Each new silo will instead contain only new types of data and where old types are required, simply pointers, or cross silo foreign keys.
We have two different things here, a shared schema and a shared database. As far as I understand the idea, Alex is talking about having the ability to access the shared database in the same way, from all the applications in the organization, and not having the same schema in all the DBs for all applications, I envision is as something like this:

Taking this approach to its logical conclusion, I may end up with an application that is dependant on many databases. There are known issues with this approach, from the top of my head:
- Reliability issues - the application talks to more than a single DB, so now any of the DBs going down will break it.
- Maintainability issue #1 - since you have other application dependant on your database, how are you going to handle upgrades and changes to it? When you take down a single database / application, you need to take down a significant number of applications with it.
- Maintainability issue #2 - changing a single database can have a ripple affect to all the applications in an organization.
- Maintainability issue #3 - the way the previous application stored its data may cause severe issues for you when you try to consume it. Perhaps you access pattern dictate that you need to get data from several disparate tables, making it more expensive to get the data. Maybe the data that you want requires extra calculation that you want to store in the DB, etc.
- Maintainability issue #4 - In any big organization, it is very likely that you will have several database products in place (SQL Server, Oracle, MySQL, etc). Those have different behaviors at time, and would require that you would remember to treat them differently.
- Duplication issues - Quite often, the data in the database is not readily consumable, and requires a bit a business logic to handle properly. For instance, the policy status that the user sees may depend on the policy type and the risk level of the customer. If you want to do the same on another application, you need to duplicate this logic again. This can be a real issue if this is a piece of business logic that often changes.
- Security implications - leaving aside the problem of letting multiply applications to access a database, there are security implications that are beyond what can be specified using SQL permissions. The salary of an employee is only visible to the HR person responsible for the employee and its manager (if he is above level 16). Now, please try to define that using SQL Permissions. You can't, at least not without a lot of awkwardness. This means that you need application level security decisions. To say that those are complex is a big understatement.
- FK issue - traditionally, cross DB FK are a problem, especially when you consider cross server and cross database products FKs.
My current projects pulls data from five different databases into its own database, and several other sources like XML files, flat text files, etc. It all goes to a single database, where it is stored in a way that make it really easy for the application to consume it, and a lot of the difficult stuff has been moved to the ETL process, which make it much easier to ignore the way we get the data when I consume it.
My personal preference is to create a silo, define a known master for the data that I want, and simply use an ETL process in order to get fresh data at regular intervals. This makes things a lot simpler from all perspectives.
All of that said, I still don't think that I understand why Alex thinks that other OR/M doesn't support it. I have used the componentization technique in the past, it looks something like this:
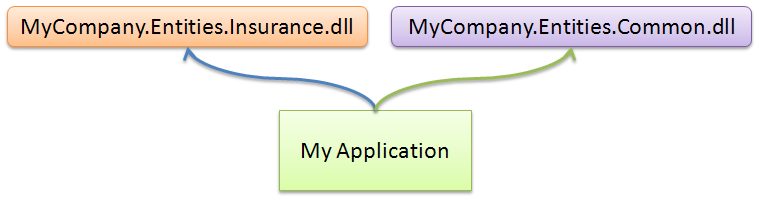
It takes a bit of configuration to handle, but basically when you are asking to get a type from the common entities, it goes to one DB, and when you want to get your own type, it goes to the application DB.
A nice property of NHibernate's parameterized user types means that you can have cross database reference with ease. Meaning that you can have policy.Customer rather than have policy.CustomerId.
A fairly big issue here is performance, since cross database joins are rarely possible (linked servers are one way, but they are a PITA and comes with their own set of problem), so you would need to be aware of that, but this is just a side effect of the approach used.
Am I missing something here?
Comments
Comment preview