





Optimizing read transaction startup timeThe performance triage
This series is no longer appropriately named, but we’ll go with that for the sake of grouping everything together.
So far we have seen how we start with a fixed benchmark, and we use a profiler to narrow down all sort of hotspots. However, we do that in a pretty strange way. Consider were we started:

Now consider this series’ name. Why are we even looking at OpenReadTransaction in the first place? There is a big giant hotspot in GetDocumentsById that we can start with.
Even a small change there is likely to generate a lot more results for our benchmark than eliminating everything else entirely. So why focus on those first?
Put simply, this isn’t just about this particular benchmark. We focused on everything else because those are costs that are shared across the board. Not only for the “read random documents” benchmark but for pretty much anything else in RavenDB.
By reducing those costs, we are enabling ourselves to get much better performance overall. And we’ll get to the actual meat of this benchmark late, when it takes the bulk of the work.
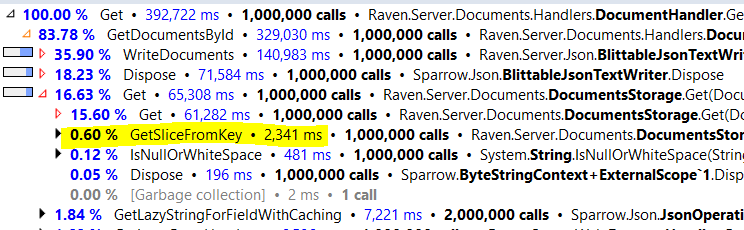
Look at the relative costs here. We moved from 60% of the request being spent there to over 80% being spent there. (Don’t look at the actual number, different machines, load and timing are responsible for those).
Now any work that we do here will have much greater impact.
More posts in "Optimizing read transaction startup time" series:
- (31 Oct 2016) Racy data structures
- (28 Oct 2016) Every little bit helps, a LOT
- (26 Oct 2016) The performance triage
- (25 Oct 2016) Unicode ate my perf and all I got was
- (24 Oct 2016) Don’t ignore the context
- (21 Oct 2016) Getting frisky
- (20 Oct 2016) The low hanging fruit
Comments
Comment preview