





Distributed Applications Failure Points
The worst part of building a distributed application is that you get different state in different parts of the system. Let us take a look at a simple message passing application, and the issues there. At the end of the day, each and every message should arrive once, and exactly once. I am assuming that it is not possible for the message to be corrupted in transmissions (The TCP/IP stack in general makes sure that you won't see those messages).
The simplest model is where everything works out great:
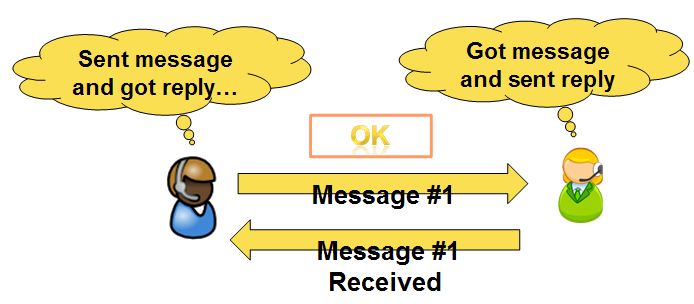
A common scenario is that the sender failed to send the message:
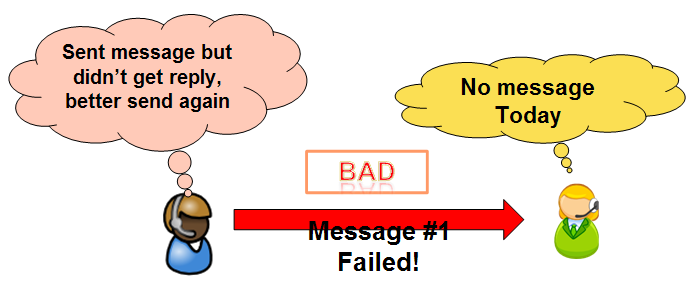
A simple resolution is sending the message again, and again, until you get an OK reply back. But then there is the dropped reply scenario, the reciever got the message, but the reply was dropped. As far as the sender knows, the reciever never got the message:
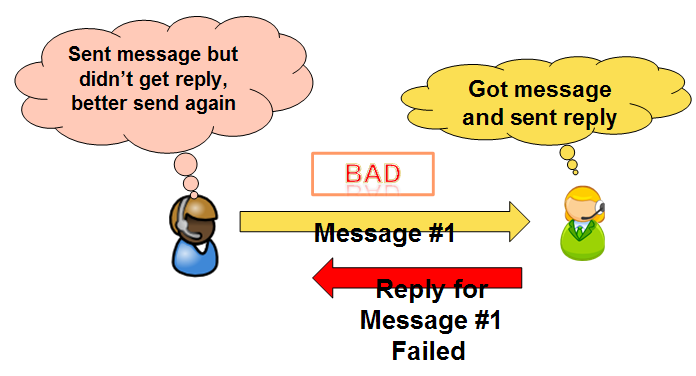
A naive implementation on the reciever side will lead to the duplicate message scenario, but a slightly less naive implementation, which detects and errors on duplicate messages may result in a lot more headaches in the end, consider this scenario:

The sender never recieves an OK reply for his message, so it will send it to the end of the days. The reciever got the message the first time and replied just fine, but the sender persist trying to give it duplicate data, which means that it keeps returning error messages back.
A good way to prevent that is to check before sending, like this:

Assuming that we always keep this semantics, a failure at any points of the road never leads to losing messages or duplicating them. I tried, but I can't think of a way the sender will think that the reciever got a message when the reciever didn't get it.
Just to point out, the scenario above happens all the way up from TCP. This is a relatively simple scenario. More interesting ones include ordered messages, and two ways communications.
Hope you liked the pretty pictures.
Comments
Comment preview