 If deployment means a week with little sleep and beepers going off just as you nod to sleep, then you are doing it wrong. I am saying that as someone whose standard deployment procedure has two steps, "svn up" and "build.cmd". Actually, I lied, I have a single step, deploy.cmd, which runs them both for me.
If deployment means a week with little sleep and beepers going off just as you nod to sleep, then you are doing it wrong. I am saying that as someone whose standard deployment procedure has two steps, "svn up" and "build.cmd". Actually, I lied, I have a single step, deploy.cmd, which runs them both for me.
Now, you can't always get this procedure to work, this is especially true if you need to deploy several different parts of the same application at the same time. The classic example is making a change that requires modifying the database as well. More interesting examples consist of several layers of the same application, web servers, application servers, dedicated tasks servers and the database servers, all of whom need to be touched in order to deploy the new version of the application.
One of my customers takes the simple approach of shutting down everything and systematically upgrading all the systems when the application itself is offline. That is probably the simplest approach, you don't have to worry about concurrent state and multi versioning, but it is also the one that is harder to the business to deal with.
In fact, service level agreements may very well limit or prevent doing that. Here is a simple table of the common SLA and their meaning, in terms of system maintenance:
| Uptime | Time for offline maintenance, monthly |
| 99% | 7 hours, 12 minutes |
| 99.9% | 43 minutes |
| 99.99% | 4 minutes |
| 99.999% | 26 seconds |
The last number is the one we should pay attention to, it is the magic 5 nines that SLA often revolves around. Now, SLA often talks about unplanned downtime, and in many systems, you can safely take it down outside of business hours and tinker as much as you like with it. Those are not the kind of systems that I want to talk about today. The system that you can take down safely are fairly easy to upgrade in a safe manner, as was previously mentioned.
The systems that are more interesting are the ones that you want to be able to update on the fly, without a painfully long deployment cycle. This is directly related to the ability to meet required SLA, but it also has another critically important factor. Developer productivity. If making a change in the application is something that requires stopping the application, updating files, starting it up again and then being hit with the initial, it is painful, annoying and will lead developers to jump through all sorts of really nasty hops along the way.
So easy deployment is critical both for the developer and for production, but the needs of each are vastly different. For developers, having it work "most of the time" is fine, having it consume more memory is also fine, because the application is not going to run for days on end. For production, it must work all the time, and you must watch your resource consumption very carefully.
A typical hot deployment for production will usually look like this:
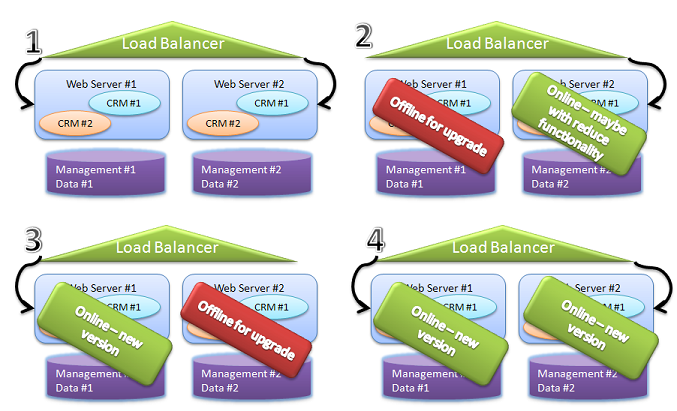
This assumes a typical production scenario in which you have duplicates of everything, for fail over and performance.
This is just an extension of the previous cold deployment, since we are taking servers down, just not the application as a whole.
This assumes that we actually can take vertical parts of the application down, which is not always the case, of course.
But, basically, we start with both servers operational, move all traffic to the second server, and then perform a cold deploy to the first set of servers.
Then we move all traffic to the new server and perform cold deployment on the second server.
In the end, this usually means that you can perform the entire thing upgrade without loss of service (although you may suffer loss of capacity.
As I said, this is probably the ideal scenario for perform hot deployments, but it makes quite a few assumptions that are not always valid. The main one is that the application is structured vertically in such a way that we can close and open parts of it and there are no critical points along the way.
I can think of one common scenario where this is not the case, several web servers sitting on top of the same database server, for instance. So, while this is a good approach, we probably want to consider others as well.
Another option is to design the system with multiply concurrent versions from the get go. This gives us the following diagram:
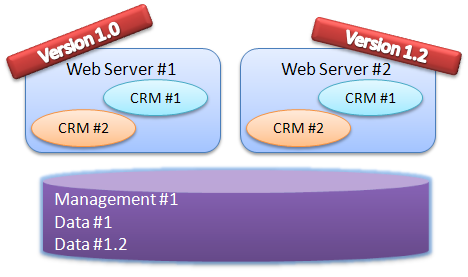
We have several versions running at the same time, and we can migrate users slowly from one version to the next. This also gives us a nice rollback strategy if we have a botched version.
The problem with this approach is that it is a complicated procedure. This is especially true if the application is composed of several independent services that needs to be upgraded separately. Again, database and web servers are common example, but even web services that needs to be upgraded requires some interesting mechanics when you have enough of them.
I am going to talk about multi versioned databases in the next post in the series, so let us just take as a given that this is possible, and consider the implications.
If I can run multiply versions at the same time, this means that I can probably propagate a change throughout a cluster of servers without having to worry about the change over semantics. (The time between the first server getting the change and the last one getting it).
Before we go on with production deployments, I want to talk a bit about developer deployments. What do I mean by that?
Well, deployment is probably the wrong term here, but this is the way most of the enterprise platforms make you go about it. And that is a problem. Deploying your changes just in order to run them is a problematic issue. It is problematic because it interferes with make-a-change/run approach, which is critically important for developer productivity.
As mentioned above, any multi step process is going to be painful as hell over any significant development. I often have to go through several dozens of change/run before I can say that I have finished with a particular feature.
There is a strong incentive to make it as easy as possible, and as it turns out, we actually have the tools in place to do it very easily indeed. I have produced a screen cast that talks about hot deployment of compiled code, and applying the same principals to code in its textual form is demonstrated here.

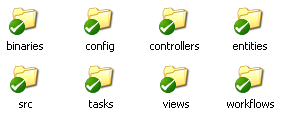 Here is the directory structure that I envisioned for the platform. As you can guess, this is backed by source control, but more importantly, it is alive (queue mad laugher here).
Here is the directory structure that I envisioned for the platform. As you can guess, this is backed by source control, but more importantly, it is alive (queue mad laugher here).
But what do I mean by that? I mean that any change whatsoever that is done to this directories will be automatically picked up and incorporated by the system as soon as the change is detected.
This supports very nicely the idea of change & run mentality. But what actually goes into these folders?
The parts that are important to us are the entities, controllers and views. For discussing those, we will take the Account entity as an example.
For the system, an Account entity is composed of the following files:
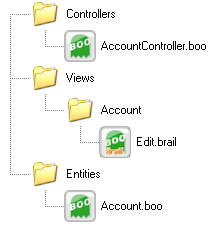
There is a reason why I choose to use boo as the primary language for extending the platform. Not just because of personal bias (which exists), but because it makes it so much easier to deal with quite a few issues.
One of them is the ability to define my own syntax, so the content of the Account.boo file would be similar to this:
entity Account:
AccountId as int
Name as string
The ability to define entity as a keyword means that I don't need to do anything more to define any persistence concerns, even though I intend to use this as an Active Record class, it is all handled by the framework.
I do intend to allow extension using compiled code, that is why the binaries folder is there for, and you can certainly define C# classes, but the main idea here is to allow easy editing of the whole thing, which means that compilation is not necessarily a good thing.
So, after this explanation, let us go back a bit and talk about what deployment means in this scenario? Well, the first thing that it means is that once a change is detected, you want to recompile the file and keep on moving without breaking your stride. Brail itself is a good example of it. Brail templates are instantly updated if changed, but they are usually compiled (thus supposedly faster). From the developer perspective, there isn't any difference between the two. It works very well in practice, and the productivity boost means that it is encourage the small steps approach. All in all, I am quite happy with it.
I am going to leave the technical details aside for now, let us just say that it is equally easy to do in both source and binary form, and you can either see the webcast or check the post about each one.
There are a few things that we should be worried about, however, mainly, recompiling files all over the place will cause an assembly leak, which can have an adverse affect on memory consumption. Here we get to the some interesting design decisions. Batching compilation will help greatly here, so we can grab all the controllers and compile them into a single assembly, then recompile the changes into separated assemblies. This is the solution used by Brail, for instance.
This seems like it can cause problems, and in theory, it will, but in practice, there are several mitigating factors:
- During development, we can expect the application lifetime to be short enough that assembly leakage is rarely an issue, if it is, there is a small cost to restarting the application.
- On production, we will rarely expect to have a lot of churn, so we can handle the extra memory requirement (in the order of a single megabyte or so, in most cases).
More advance scenarios calls for either AppDomain restart (the way ASP.Net does it) or a separate AppDomain that can be safely loaded. Personally, I think that this would make the situation much harder, and I would like to avoid it if possible. The simplest solution works, in my experience.
What this all means is that a developer can go and make a change to the Account controller, hit the page and immediately get the changes made. Deployment now means that we commit to the development branch, merge to the production branch, and then we request the production system to update itself from the source. A form of CI process is a valid idea in this scenario, and will probably be the default approach to updating changes in a single system scenario. We have to have a way to disable that, because we may want to upgrade only some of the servers at a time.
This leaves us with the following issues:
 Debugging - How can we debug scripts? Especially dynamically changing scripts? Despite what some of the Ruby guys say, I want to have the best debugger that I can available. A platform with no or poor debugging support has a distinct disadvantage.
Debugging - How can we debug scripts? Especially dynamically changing scripts? Despite what some of the Ruby guys say, I want to have the best debugger that I can available. A platform with no or poor debugging support has a distinct disadvantage.
As it turns out, the problem isn't that big. The Visual Studio debugger is a really smart one, and it is capable of handle this in most cases with aplomb. And since Boo code is compiled to IL, VS has few issues with debugging it. For the more complex scenarios, you can use C# and just direct the build path to the binaries folder.
In any case, debugging would usually involve "Attach to process" rather than "Start with debugger", but this is something that I can live with (Attach is faster anyway).
Database modifications - let us just hand wave the way we are going to handle that for a minute. We will just assume we can do something like UpdateSchema() and it will happen, we still need to think about the implications of that.
Now we need to think about how we are going to handle that when we update an entity. Do we want this update to the schema to be automatic, or do we want it to happen as a result of user input? Furthermore, changing the entity basically invalidate the ability to call the database, so how do we handle that?
Do we disable the usage of this entity until the DB is updated? Do we just let the user to run into errors? What do we do for production, for that matter? I definitely not going to let my system run with DDL permission for production, so that is another problem.
I can give arguments for each of those, but a decision still has to be reached. Right now I think that the following set of policies would serve well enough:
- For production, all database changes must be handled after an explicit user action. Probably by going to a page and entering the credentials of a user that can execute DDL statements on the database.
- For development, we will support the same manual approach, but we will also have a policy to auto update the database on entity change.
We are still in somewhat muddy water with regards to deploying to production with regards to changes that affects the entire system, to wit, breaking database changes. I am going to discuss that in the next installment, this one got just a tad out of hand, I am afraid.






 For some reason, the moment that peole start working on Enterprise Solutions, there is a... tendency to assume that because we are going to build a big and complex application, we can afford to ignore best practices and proven practices.
For some reason, the moment that peole start working on Enterprise Solutions, there is a... tendency to assume that because we are going to build a big and complex application, we can afford to ignore best practices and proven practices.
 We probably want the usual auditing suspects, such as Id, CreatedAt, ModifiedAt, CreatedBy, ModifiedBy, Owner, OrganizationUnit. Maybe a few more, if this makes sense. Probably not too much, because that can get to be a problem.
We probably want the usual auditing suspects, such as Id, CreatedAt, ModifiedAt, CreatedBy, ModifiedBy, Owner, OrganizationUnit. Maybe a few more, if this makes sense. Probably not too much, because that can get to be a problem.







