





RavenDB is moving at quite a pace, and there is actually more stuff happening than I can find the time to talk about. I usually talk about the big-ticket items, but today I wanted to discuss some of what we like to call Quality of Life features.
The sort of things that help smooth the entire process of using RavenDB - the difference between something that works and something polished. That is something I truly care about, so with a great sense of pride, let me walk you through some of the nicest things that you probably wouldn’t even notice that we are doing for you.
RavenDB Node.js Client - v7.0 released (with Vector Search)
We updated the RavenDB Node.js client to version 7.0, with the biggest item being explicit support for vector search queries from Node.js. You can now write queries like these:
const docs = session.query<Product>({collection: "Products"})
.vectorSearch(x => x.withText("Name"),
factory => factory.byText("italian food"))
.all();This is the famous example of using RavenDB’s vector search to find pizza and pasta in your product catalog, utilizing vector search and automatic data embeddings.
Converting automatic indexes to static indexes
RavenDB has auto indexes. Send a query, and if there is no existing index to run the query, the query optimizer will generate one for you. That works quite amazingly well, but sometimes you want to use this automatic index as the basis for a static (user-defined) index. Now you can do that directly from the RavenDB Studio, like so:
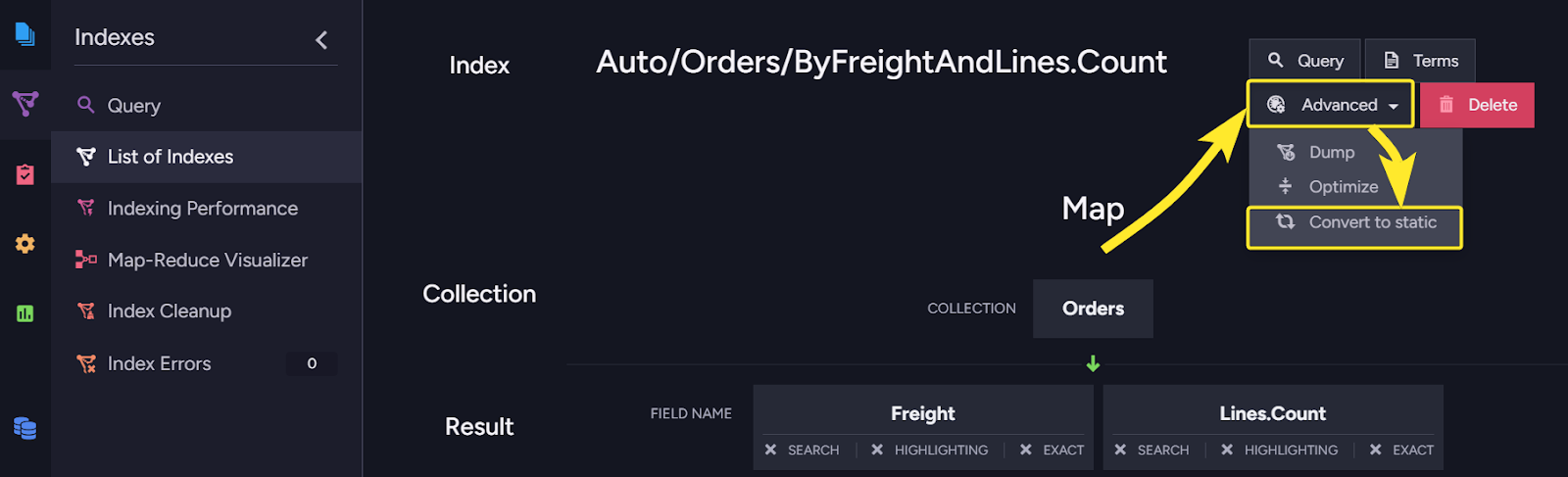
You can read the full details of the feature at the following link.
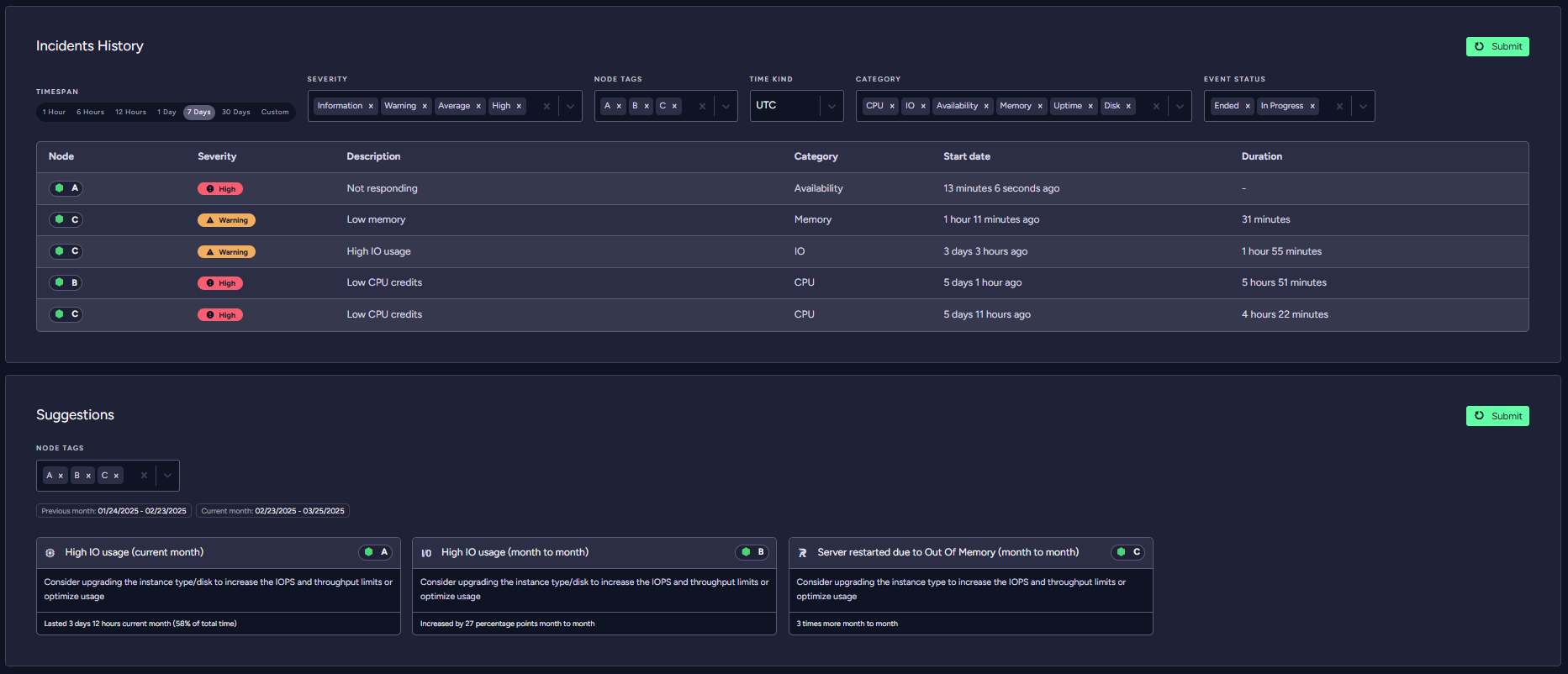
RavenDB Cloud - Incidents History & Operational Suggestions
We now expose the operational suggestions to you on the dashboard. The idea is that you can easily and proactively check the status of your instances and whether you need to take any action.
You can also see what happened to your system in the past, including things that RavenDB’s system automatically recovered from without you needing to lift a finger.
For example, take a look at this highly distressed system:
As usual, I would appreciate any feedback you have on the new features.


