





Fun with a non relational databases
My post showing a different approach for handling data got a lot of traffic, and a lot of good comments. But I think that there is some misunderstanding with regards to the capabilities of NoSQL databases, so I am going to try to expand on those capabilities in this post.
Instead of hand waving, and since I am thinking about this a lot lately, we will assume that we are talking about DivanDB (unreleased version), which has the following API:
- JsonDoc[] Get(params Id[] ids);
- Set(params JsonDoc[] docs);
- JsonDoc[] Query(string indexName, string query);
DivanDB is a simple Document database, storing documents as Json, and using Lucene as a indexer for the data. An index is defined by specifying a function that creates it:
var booksByAuthor = from doc in documents
where doc.type == “book”
from author in doc.authors
select new { author };
And the data looks like this:
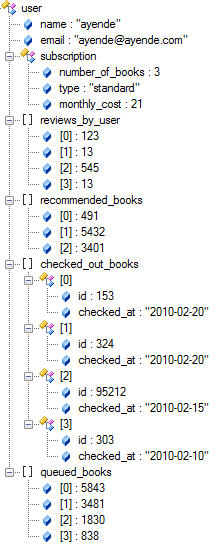
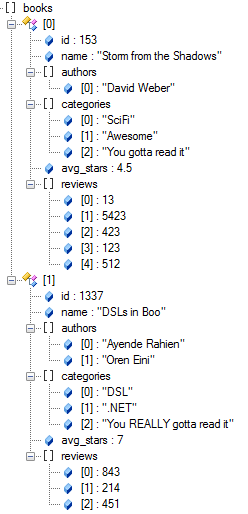
Indexing is done at write time, you can think about those indexes as materialized views.
It appears that people assumes that just because you aren’t using an RDBMS, you can’t use queries. Here are a few options to show how you can do so.
Books by author:
Query(“booksByAuthor”, “author:weber”);
Books by category:
Query(“booksByCategory”, “category:scifi”);
How is the books by category index defined? I think you can guess.
var booksByCategory = from doc in documents
where doc.type == “book”
from category in doc.categories
select new { category };
What other queries did people brought up?
Who has book X in their queue?
Query(“usersByQueuedBooks”, “book:41”);
And the view?
var usersByQueuedBooks = from doc in documents
where doc.type == "user"
from book in doc.queues_books
select new { book };
I’ll leave the implementation of Who has book X checked out as an exercise for the reader.
What about deletes?
Using this system, it looks like deletes might be really expensive, right? Well, that depends on what exactly you want here.
My default approach would be to consider exactly what you want, as Udi pointed out, in the real world, you don’t delete.
But it is actually fairly easy to support something like this cheaply. It is all about defining the association and letting the DB handle this (although I am not fond of the syntax I came up with):
var books = from book in documents
where book.type == "book"
select new { book = book.id };
var checkedOutBooks = from user in documents
where user.type = "user"
from book in user.checked_out
select new { book };var queuedBooks = from user in documents
where user.type = "user"
from book in user.queued_books
select new { book };
FK_DisallowDeletion(books, checkoutBooks);
FK_RemoveElement(books, queuedBooks);
Under the cover this creates indexers and can check out those at delete / insert time.
However, I would probably not implement this for Rhino DivanDB, mostly because I agree with Udi.
Comments
Comment preview