





Reading Eralng: CouchDB Streams
A question to my dear readers, do you find this series valuable? Do you consider it interesting? It is a significant departure from my usual set of topics.
In my recent post I wondered about the concept of summary streams, and how they related to the way CouchDB works. I couldn't figure out what they were doing. As it turn out, there is a good documentation for them in this post. There were two things that mislead me. The first was the notion of summary. I think that this is a misnomer, because this is the only place in CouchDB where that term is used. It is not a summary, it is the actual document. As a matter of fact, I think that it is a term that was carried over from Notes.
The second misleading clue was stream. I am used to think about streams in the classic sense, as a way to access a stream of bytes. The CouchDB notion of stream is quite different. It is a way to optimize disk access, it seems. I wondered about that, because the nature of CouchDB append only file seems certain to cause a lot of issues with regards to internal fragmentation in the file (which would require a lot of seeks, which are slow).
Let me see if I can deconstruct what is going on in couch_stream, first, we have the structure declaration:
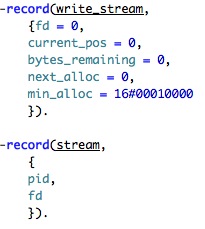
This seems to be pretty reasonable. The write_stream is defining a reserved space in the file, note the next_alloc field. It looks like we are allocating memory (or disk space). Should be interesting. The stream structure just hold the process and the file description, and isn't really interesting.
The initialization of a stream is interesting in itself:
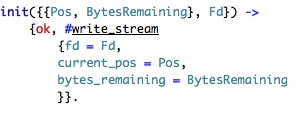
Here we just create a new write stream and copy the initialization values to the state. There seems to be a 1 to 1 mapping between a stream and an erlang process. Let us examine how we write the data. First, we have the stop condition of running out of data to write:
![]()
You can learn a lot about the a function in erlang just from its declaration. In this case, <<>> means a binary with no items in it, hence, we run out of things to write.
And now we come to the function clause that deals with the issue of running out of room to write it.
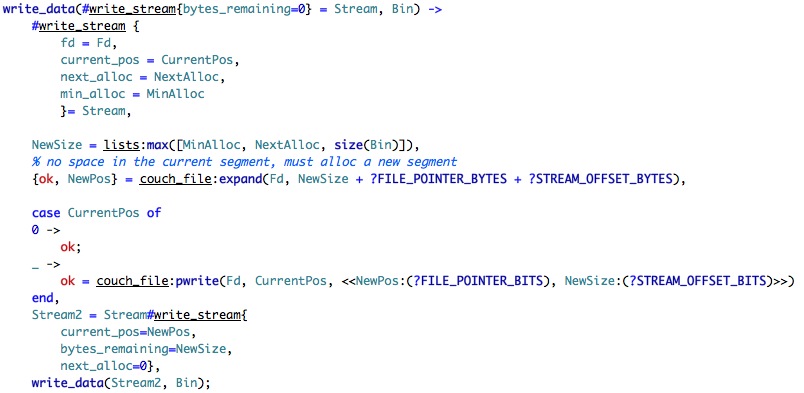
The first part of the function is using variable binding to extract the values out of the stream. It goes against the grain, I know, to see CurrentPos being "set" when it is on the right side of the assignment, but that how it works. (Well, actually it isn't being set, it is being matched, or bound, but that is another issue).
Next we find what is the next size that we have to allocate, and ask the file to expand. I don't think that I have seen this before, let us take a look:

We first get a the end of the file, and then we write a single byte at the end of the file plus the expansion value. In other words, we increase the length of the file by however big Num is. For .NET, this is the equivalent of the SetLength call, and it is important to create continuos files, with as little fragmentation as possible.
Going back to write_data, we have this line:
![]()
The syntax isn't really nice, in my opinion, but what we have here is basically: Write to the file Fd at position CurrentPos the value of NewPos (with pack to FILE_POINTER_BITS and then the value of NewSize (packed to STREAM_OFFSET_BITS).
It is important to note where this is written. Go and take a look at the case statement in which this expression is. First, we setup enough size for the data we want to write and for the next allocation. When we come to the end of the current chunk, we create a new one (by expanding the file) and then write the address of the new chunk into the end of the chunk, following that by a move to the new chunk.
The last part of write_data is very simple:
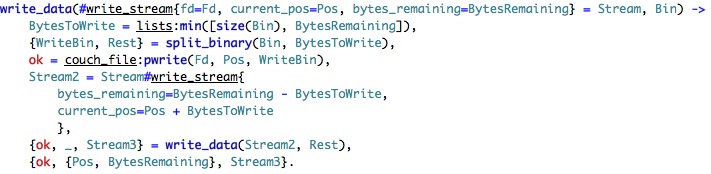
We start by figuring out how many bytes we have to write, and then split the binary data by that. We write what we can to the file, and then recursively call ourself (which will either exit (nothing to write) or create a new chunk of the file and continue writing it.
Elegant, short and to the point. It take more time to describe how it works than it is to write the code. The code for reading is just as sweet:
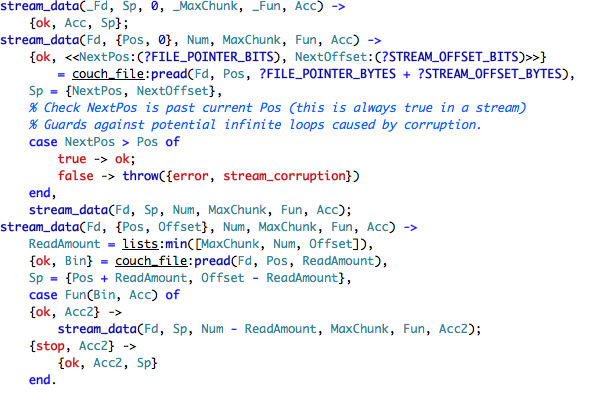
The stop condition is when we have no more data to read. The second clause is when we have run out of data to read in the current stream, and we need to read about the next one. Again, erlang's pattern matching is useful here, because it allow to easily unpack the values from the file to in memory representation.
The last clause is where things are actually happening. We select the number of bytes to read, offset is a really misleading term here, it is not the offset from the beginning of the chunk (like most of us would think), it is the amount of bytes remaining in the current chunk.
We read the data to memory, update the Sp (stream position?) and then call the function that we were passed, to find out if we should read more or stop.
Now, how are those streams used?
From reading the code, it looks like there are two streams used in CouchDB. The first is the document stream (called the summary_stream). And the second (actually, the seconds) is a stream for all the binary attachments for a document (a stream per a set of document attachments).
And with this, we conclude the reading of CouchDB persistence architecture. Next topic, views, and how they are used.
Comments
this topic is interesting but I'm overloaded with info right now. with regular work, pet projects, your book, and all the blogs I track.. it's hard to keep up. Still it is interesting; its a peek into Erlang and CouchDB.
It's gotten me back into your blog honestly. I find it way more educational and useful than the distributed hash series.
I find the series fascinating, as I've mentioned in my blog. See the Miscellaneous (WPF, WCF, MVC, Silverlight, etc.) section of
oakleafblog.blogspot.com/.../...-posts-for_02.html and
oakleafblog.blogspot.com/.../...-posts-for_24.html.
My interest in Erlang relates to its use by Amazon for SimpleDB.
--rj
I found these really interesting just for me over my head because I don't fully understand the syntax of erlang.
I'm always really interesting in what other languages can offer, if not by using them but patterns they focus on which can inspire work inside other languages.
ps, you have by far the most fascinating blog I've come across to date, please never stop!
Ok, I've made it through you posts on CouchDB to this point. Great stuff. Now I have to go back through them all again with all the source in front of me.
BTW, no flames, but VIM does nice syntax coloring of Erlang.
Also BTW, I'm going through this same exercise with YXA right now.
What is yxa?
Not that I know what it is but I think he is talking about this
http://www.stacken.kth.se/project/yxa/
I need to dig my paws into ErLang someday but I agree with Stephen, I love your blog.
Comment preview