





Code base size, complexity and language choice
Via Frans, I got into these two blog posts:
- Steve Yegge - Code's Worst Enemy
- Jeff Atwwok - Size Is The Enemy
In both posts, Steve & Jeff attack code size as the #1 issue that they have with projects. I read the posts with more or less disbelieving eyes. Some choice quotes from them are:
Steve: If you have a million lines of code, at 50 lines per "page", that's 20,000 pages of code. How long would it take you to read a 20,000-page instruction manual?
Steve: We know this because twenty-million line code bases are already moving beyond the grasp of modern IDEs on modern machines.
Jeff: If you personally write 500,000 lines of code in any language, you are so totally screwed.
I strongly suggest that you'll go over them (Steve's posts is long, mind you), and then return here to my conclusions.
Frans did a good job discussing why he doesn't believe this to be the case, he takes a different tack than mine, however, but that is mostly business in usual between us. I think that the difference is more a matter of semantics and overall approach than the big gulf it appears at time.
I want to focus on Steve's assertion that at some point, code size makes project exponentially harder. 500,000 LOC is the number he quotes for the sample project that he is talking about. Jeff took that number and asserted that at that point you are "totally screwed".
Here are a few numbers to go around:
- Castle: 386,754
- NHibernate: 245,749
- Boo: 212,425
- Rhino Tools: 142,679
Total LOC: 987,607
I think that this is close enough to one million lines of code to make no difference.
This is the stack on top of which I am building my projects. I am often in & out of those projects.
1 million lines of code.
I am often jumping into those projects to add a feature or fix a bug.
1 million lines of code.
I somehow manage to avoid getting "totally screwed", interesting, that.
Having said that, let us take a look at the details of Steve's post. As it turn out, I fully agree with a lot of the underlying principals that he base his conclusion on.
Duplication patterns - Java/C# doesn't have the facilities to avoid duplication that other languages do. Let us take the following trivial example. I run into it a few days ago, I couldn't find a way to remove the duplication without significantly complicating the code.
DateTime start = DateTime.Now; // Do some lengthy operation DateTime duration = DateTime.Now - start; if (duration > MaxAllowedDuration) { SlaViolations.Add(duration, MaxAllowedDuration, "When performing XYZ with A,B,C as parameters"); }
I took this example to Boo and extended the language to understand what SLA violation means. Then I could just put the semantics of the operations, without having to copy/paste this code.
Design patterns are a sign of language weakness - Indeed, a design pattern is, most of the time, just a structured way to handle duplication. Boo's [Singleton] attribute demonstrate well how I would like to treat such needs. Write it once and apply it everywhere. Do not force me to write it over and over again, then call it a best practice.
There is value in design patterns, most assuredly. Communication is a big deal, and having a structured way to go about solving a problem is important. That doesn't excuse code duplication, however.
Cyclomatic complexity is not a good measure of the complexity of a system - I agree with this as well. I have seen unmaintainable systems with very low CC scores. It was just that changing anything in the system require a bulldozer to move the mountains of code required. I have seen very maintainable systems that had a high degree of complexity at parts. CC is not a good indication.
Let us go back to Steve's quotes above. It takes too long to read a million lines of code. IDE breaks down at 20 millions lines of code.
Well, of the code bases above, I can clearly and readily point outs many sections that I have never read, have no idea about how they are written or what they are doing. I never read those million lines of code.
As for putting 20 millions lines of code in the IDE...
Why would I want to do that?
The secret art of having to deal with large code bases is...
To avoid dealing with large code bases.
Wait, did I just agree with Steve? No, I still strongly disagree with his conclusions. It is just that I have a very different approach than he seems to have for this.
Let us look at a typical project structure that I would have:
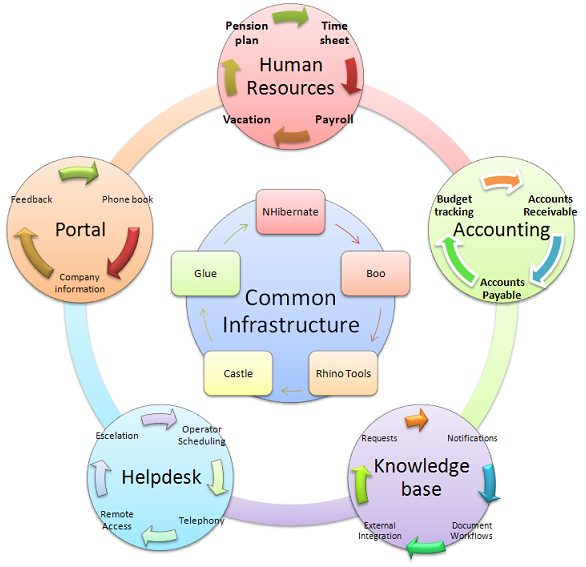
Now, I don't have the patience (or the space) to do it in a true recursive manner, but imagine that each of those items is also composed of smaller pieces, and each of those are composed of smaller parts, etc.
The key hole is that you only need to understand a single part of the system at a time. You will probably need to know some of the infrastructure, obviously, but you don't have to deal with it.
Separation of concerns is the only way to create maintainable software. If your code base doesn't have SoC, it is not going to scale. What I think that Steve has found was simply the scaling limit of his approach in a particular scenario. That approach, in another language, may increase the amount of time it takes to hit that limit, but it is there nevertheless.
Consider it the inverse of the usual "switch the language for performance" scenario, you move languages to reduce the amount of things you need to handle, but that scalability limit is there, waiting. And a language choice is only going to matter about when you'll hit it.
I am not even sure that the assertion that 150,000 lines of dynamic language code would be that much better than the 500,000 lines of Java code. I think that this is utterly the wrong way to look at it.
Features means code, no way around it. If you state that code size is your problem, you also state that you cannot meet the features that the customer will eventually want.
My current project is ~170,000 LOC, and it keeps growing as we add more features. We haven't even had a hitch in our stride so far in terms of the project complexity. I can go in and figure out what each part of the system does in isolation. If I can't see this in isolation, it is time to refactor it out.
On another project, we have about 30,000 LOC, and I don't want to ever touch it again.
Both projects, to be clear, uses NHiberante, IoC, DDD (to a point). The smaller project has much higher test coverage as well and much higher degree of reuse.
The bigger project is much more maintainable (as a direct result of learning what made the previous one hard to maintain).
To conclude, I agree with many of the assertions that Steve makes. I agree that C#/Java encourage duplication, because there is no way around it. I even agree that having to deal with a large amount of code at a time is bad. What I don't agree is saying that the problem is with the code. The problem is not with the code, the problem is with the architecture. That much code has no business being in your face.
Break it up to manageable pieces and work from there. Hm... I think I have heard that one before...
Comments
As you said, the key here is separation of concerns.
However, you shouldn't include the LOCs of the libraries you use because they are well-enough separated to not be a concern of your project.
If you really want to go that way, you may as well add the LOCs of the BCL. :)
By the way, do you know where I could read some details about one of these beasts with millions of LOCs?
Pierre Henri,
I am including the libraries because I am not treating them just as a user, I am also a developer for all of them.
What I meant is that they are "separated" from the actual (business) projects.
Although they have a direct impact on the projects (+ may require development time), translating that into lines of code is a subjective topic without any context.
Well, I do the same for the project itself, forcing separation until I can deal with each piece in isolation
The 500kloc project is a game that he was working on singlehandedly, the projects you mentioned are for the most part are open source, which i think is a totally different thing.
I think the point he's trying to make is that for one person handling a project alone code size does matter because you can keep track of more at a single time. Especially when it is feature complete and all the work left to do is bug fixing, it can make solving these issues easier and quicker.
Ayende, I am surprised by these numbers How do you count your number of LOC? As I commented on the Jeff and Frans blog:
"Developpers always claim that they are maintaining much more lines of code than they actually do. Recently I was consulting on a large project, they said 4M LOC, but it was actually 700K LOC (measured with NDepend). The difference comes from the way you're measuring LOC and I detailled here how you should do in the .NET world:"
codebetter.com/.../how-do-you-count-your-number-of-lines-of-code-loc.aspx
When NDepend measure the number of LOC of NDepend it says 53K LOC by now and it contains a CQL compiler and editor, an IL analyzer, and a lot of WinForm GDI stuff. It might sounds ridiculously small, but still, I consider it as a huge and complex project!
.
Patrick,
I measured line count the simplest way:
for file in GetFiles():
Not really nice, but it is quick & dirty solution
Ayende,
A couple points. First, I think they are discussing lines of code as it relates to operations, not really the comments and other fill which isn't code. Counting lines of code the way you provided will obviously lead to inflated numbers. Without a clear understanding of what each person is counting it becomes very difficult to compare.
Second, I think the original articles were talking about one person maintaining a project of that size. Jeff alluded to the fact that developers working on a project of this size usually work on a team or as he put it open source it to receive help from the community. More people certainly makes the task more manageable.
Lastly, this is just a side point, but I would recommend against using the DateTime class for your max duration testing. If you are testing for long durations that should be fine, but DateTime is extremely inaccurate. I disccovered this myself earlier and wrote the following blog post about it:
http://jaychapman.blogspot.com/2007/11/datetimenow-precision.html
I then found the StopWatch class which solved my timing issues. If you want accurate time testing use that class instead.
http://jaychapman.blogspot.com/2007/12/datetimenow-precision-issues-enter.html
I realize that you are probably just showing an example here, but it may be helpful for other people who do not know of the StopWatch class. I know I didn't when I started my duration testing.
I built revision 3192 of NHibernate's trunk, and let NDepend analyze it (NHibernate.**.dll and Iesi.Collections.Test.dll). The result* was as follows:
Application Metrics
Number of IL instructions: 474318
Number of lines of code: 73035
Number of lines of comment: 41303
Percentage comment: 36%
Number of assemblies: 26
Number of classes: 2192
Number of types: 2489
Number of abstract classes: 106
Number of interfaces: 211
Number of value types: 86
Number of exception classes: 42
Number of attribute classes: 96
Number of delegate classes: 15
Number of enumerations classes: 76
Number of generic type definitions: 35
Number of generic method definitions: 90
Percentage of public types: 93.61%
Percentage of public methods: 85.28%
Percentage of classes with at least one public field: 5.79%
*) For those who don't know about it already, NDepend is an incredibly useful tool that does a lot more than provide you with statistics. Give it a try, you won't regret it!
I'm glad I'm not the only one with this reaction, great post Ayende.
The thing that gets me is this whole "no code is the best code" school of thought. Because "no code" doesn't mean "no code, it means "someone else's code". And while that may get you to 80% or even out the door faster, it is going to make customization and maintenance much more difficult.
And the notion of quoting those codebase sizes blew my mind as well. One of the central tenets of coding in particular and life in general is decomposing the problem into smaller digestable chunks.
Merry Christmas!
John,
I am aware of the accuracy issue with date.Now
The timespan that I am testing right now is 10 seconds, which is long enough to make accuracy pretty much non relevant.
About the line count, I am trying to hit ballpark numbers here, obviously comments, linebreaks etc are adding to the score, but it is also the simplest way to get it checked.
Great post, Oren. I like hearing from you and Frans because you both regularly work on huge code bases and can speak from first-hand experience.
I liked Frans's response, but I think yours nails it even better. I think Steve and Jeff are confusing capacity with scalability [1]. As you note, scalability has to do with the architecture, not the language. The architecture impacts whether the scalability curve goes up, down, or is linear. The benefits of a dynamic language only help with the steepness of the line, or the "capacity" of the language to express things concisely.
[1] http://www.pervasivecode.com/blog/2007/11/13/capacity-vs-scalability/
"The key hole is that you only need to understand a single part of the system at a time. You will probably need to know some of the infrastructure, obviously, but you don't have to deal with it."
I call this partitioned or compartmentalized complexity. It's not new with you or I. I could find a few references I could quote.
It's hard concept to grasp until you've either experienced it (and noticed) or studied design or architecture (ie.. book knowledge). A lot of people have neither.
http://tech.groups.yahoo.com/group/altnetconf/message/6490
Roger Sessions has some interesting work in the EA space on this same topic (where he approaches it mathematically).
That is a beautiful diagram.
Without NDepend, and at least for your "framework" code, you can see what Ohloh thinks of your codebases. Just a random example - you said Boo was 212KLOC. Ohloh says between 100K and 120K, depending on comments and whitespace: http://www.ohloh.net/projects/3515/analyses/latest
I agree with your points but I don't agree they address Steve's concern.
Steve spends a large part of his post arguing that if you have a mountain of dirt (code), big bulldozers and other machines (architecture and IDEs) is what will allow you to work with this mountain at all. But Steve's suggestion is to try to avoid having a mountain of dirt, thus avoiding (to some extent) the need for heavy machinery (architecture/IDEs) to move it around.
When you (Ayende) describe how you relatively effortlessly jump around in your fairly massive code base, looking at cohesive modules which are easily grasped in isolation, you are not describing the scenario that Steve forgot about - you're describing the same scenario he is, only he doesn't consider it a rosy picture, he thinks you and I are in denial about how hard it really is.
In Steve's post, he expresses the point of view that a large code base is not the inevitable result of a large set of requirements. It seems he thinks dynamic languages offer a way out.
I don't agree with Steve at all, but the points he invites to discussion around is whether static typing blows up your code base with additional lines of code that can't be motivated by the added safety offered by compile time type checking, given that they also (hypothetically) add substantially to the " mountain of dirt". While he doesn't make the point explicitly, I suspect that he leans to some degree on the idea that unit tests relieves the compiler of a lot of its type checking duties.
Personally I can't write three lines of code without the compiler letting me know about some mistakes I've made, and realizing how that holds just as true when I'm writing my unit tests, I'm all for static type checking.
/Mats
Mats,
What Steve is saying, repeatedly, is that the existence of those lines of code bothers him.
What I am saying is that if you need to deal with all of them at once, you are in a bad shape not because of the language, but because of your project structure.
If you need to move mountains of code, you lost. Trying to run to a dynamic language to reduce your line count is just postponing the inevitable.
Good structure makes the difference, not the language.
Yes I agree with your point that good structure makes the difference, not the language.
But,
"What Steve is saying, repeatedly, is that the existence of those lines of code bothers him.
What I am saying is that if you need to deal with all of them at once,..."
Exactly - and Steve never talks about how all these lines of code would be bad only if you had to deal with them all at once. He never assumes anyone would have to do that. Just as you say, it is the existence of all those lines of code that bothers him, even after they have been properly architected along your suggestions so that you never have to deal with it all at once.
The argument is about whether a dynamic language will really dramatically reduce your LoC (I doubt that) and whether giving up compile time type checking to potentially reduce LoC is a good idea (I seriously doubt that).
Regarding dealing with all the lines of code at once,
We have to be careful to distinguish between when the IDE would need to deal with all the LoC at once - such as during a project wide refactoring - and when the developer has to (which should be, hopefully, never)
Just to be clear, I think your discussion - architecture is more important than language choice - is a better one than Steve's. Much more interesting and better potential to yield useful results, if you ask me. So I'm all for it. I just don't think it is necessarily the same discussion that Steve is holding.
/Mats
Long time has passed since LOC is not considered a metric for code complexity anyway.
One way to handle complexity is to break it in smaller pieces by using packages or namespaces ( ir fyou preffer ) to organize your classes according to the role they assume in your system.
http://hcmarchezi.blogspot.com/2007/08/packages-tool-to-organize-classes.html
Even when I think that LOC can indicate complexity I'm afraid to put a number of when the code is reaching some type of maintainability barrier.
There is countless examples of code (small code) that is totally screw and work on it can be your worst nightmare. At the end architecture of the solution is what will make your code scalable and maintainable at the same time.
The concepts are the same and have been the same for a long time, make small methods that do one thing and one thing only, separate concerns, divide your code in namescape/classes/libraries in logical ways. (ex: don't put a file handling class in the same namespace of your business rules for creating a member).
Avoid circular references,etc. Some of this practices will make your code smaller, but also some of them may create more lines of code.
Good post.
Ayende,
Just one brief point. There is a huge difference between Steve Yegge's scenario and yours. Namely that Steve wrote and maintains every one of those half-million of his lines of code all by himself. If I'm understanding you correctly, this is definitely not the case for you with Castle, NHibernate, Boo, and Rhino Tools.
You can argue that if Steve was a better programmer it wouldn't have taken him half a million lines of code to write his app the first time, regardless of language choice. But without an intimate familiarity with the source code, I think that's an unfair, maybe even naive, criticism for you to make.
Comment preview