





The cost of select count(*) from tbl
I was always somewhat baffled that something that was so obviously required so often can be so expensive with RDBMSes. When diving deep into B-Tree implementation I suddenly found it obvious why that is the case.
Let us look at the following B-Tree:
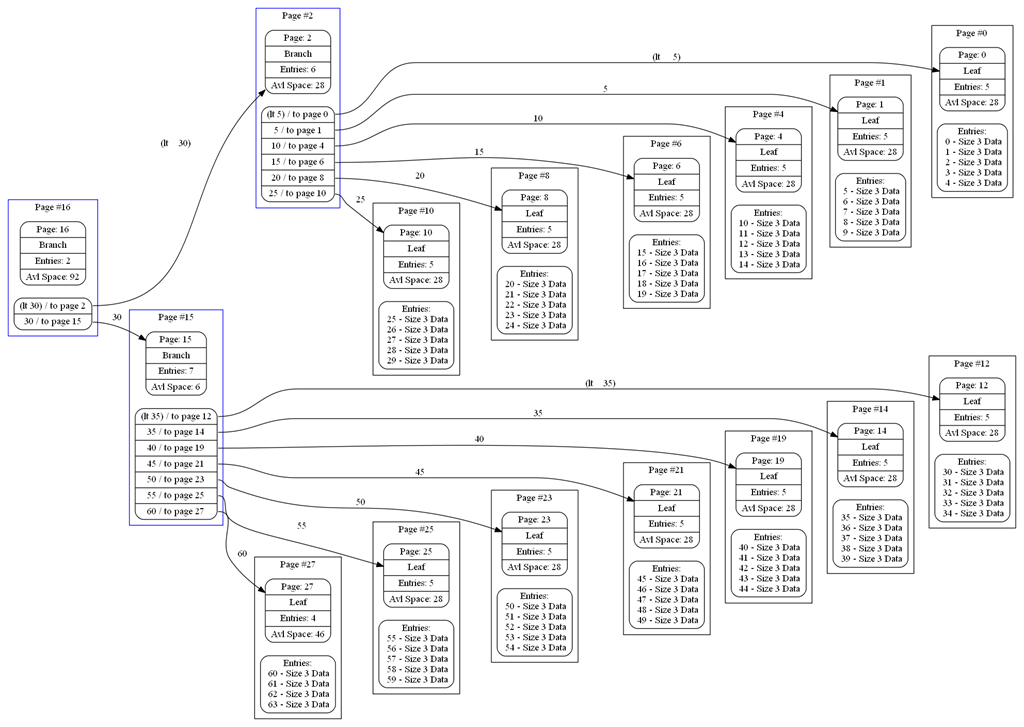
Now, if I asked you how many entries you had in this tree, you would have to visit each and every page. And that can be very expensive when you have large number of items.
But why can’t we just keep track of the total number ourselves? There is counting B-Trees that we can use that will give us the answer in O(1) time.
The answer to that is that it is too expensive to maintain this. Imagine a big tree, with 10 million records, and a fan out of 16 keys per page. That means that it has a depth of 6. Let us say that we want to add a new record. We can do that by modifying and saving the page. That would cost us 4KB of writes.
However, if we use a counting B-Tree, we have to update all of the parent pages. With a depth of 6, that means that instead of writing 4KB to disk we will have to write 24KB to disk. And probably have to do multiple seeks to actually do the write properly. That is an unacceptable performance cost, and the reason why you have to manually check all the pages when you want the full count.
Comments
Eh? LMDB tracks total number of entries and it's O(1).
We don't track number of children in a subtree but we could, since every page from leaf to parent has to be updated anyway...
Howard,
Yes, sure. Because LMDB needs to update all the parents in the tree.
For LMDB there is no difference in the cost. But if you aren't using COW in the same manner as LMDB, you incur quite an overhead for this feature.
Howard,
In other words, the minimum cost of an update with a tree with a depth of 6 in LMDB is 24KB anyway
Every transaction can have a different result for count(*) because it will see different writes than other concurrent transactions. That's why it is not possible to have one cached value. Also, as soon as you add an IsDeleted column (or similar) and filter on that, the optimization is no longer possible.
tobi: LMDB is MVCC, every transaction has a complete snapshot of the DB, including the counters.
But yes, as soon as you add a filter, you're forced to enumerate all the items.
Howard, that's a cool feature. It is enabled by the immutable B-trees. SQL Server can't easily offer that.
Howard,
If you have counting B-Trees, that would still be fairly cheap to do, even with a filter.
That's probably very stupid question but why can't we just store counter in root page or somewhere else?
An even more naive question, why not have 1 counter (anywhere) and increment/decrement it at the moment of insertion/deletion in the tree, respectively? Should this not yield correct count of records in the tree at any moment with next to no effort?
Ayende: true, it would allow you to tally up whole pages at a time if they're included in the filter range, without needing to count the individual nodes on the page. O(logN), instead of O(N).
tobi: Indeed. We learned a lot from 12+ years of working with BerkeleyDB. We made sure that everything we needed BDB to do was fast and robust in LMDB. Learning from others' mistakes is often the fastest possible teacher. (Faster even than learning from your own mistakes, because it's harder to see your own.)
Hmm: yes, effectively that's what LMDB does. But as mentioned before, every transaction sees the DB in a different state, so every transaction needs its own private view of the counter.
Alexei: that could work if you protect the counter with the transaction lock. Otherwise, since incrementing the counter is a separate operation from actually inserting into the tree, there is a window of time where the counter and reality disagree. I.e., you can't do both atomically. But if you protect the counter with the transaction lock, it becomes very expensive to query it.
(that is: transaction lock is expensive if you're not using MVCC.)
Alexei,
That would only hold true if you are not doing it with any sort of filter.
For fun, it would also need to be transactionally correct, which is also hard.
@Ayende, but you are changing the question now. The original question was to count * from table. If you want filtering, then the cost of filtering is your cost and count is free. You just count++ as your filter matches, there is no extra cost versus just filtering to get data and not counting.
Alexei,
The question isn't free floating. You actually need to handle this on a reasonable basis.
And it would be a pure PITA to have completely different performance profiles for: select count() from foo vs. select count() from foo where is_deleted = 0
Comment preview