





reWhy You Should Never Use MongoDB
I was pointed at this blog post, and I thought that I would comment, from a RavenDB perspective.
TL;DR summary:
If you don’t know what how to tie your shoes, don’t run.
The actual details in the posts are fascinating, I’ve never heard about this Diaspora project. But to be perfectly honest, the problems that they run into has nothing to do with MongoDB or its features. They have a lot to do with a fundamental lack of understanding on how to model using a document database.
In particular, I actually winced in sympathetic pain when the author explained how they modeled a TV show.
They store the entire thing as a single document:
Hell, the author even talks about General Hospital, a show that has 50+ sessions and 12,000 episodes in the blog post. And at no point did they stop to think that this might not be such a good idea?
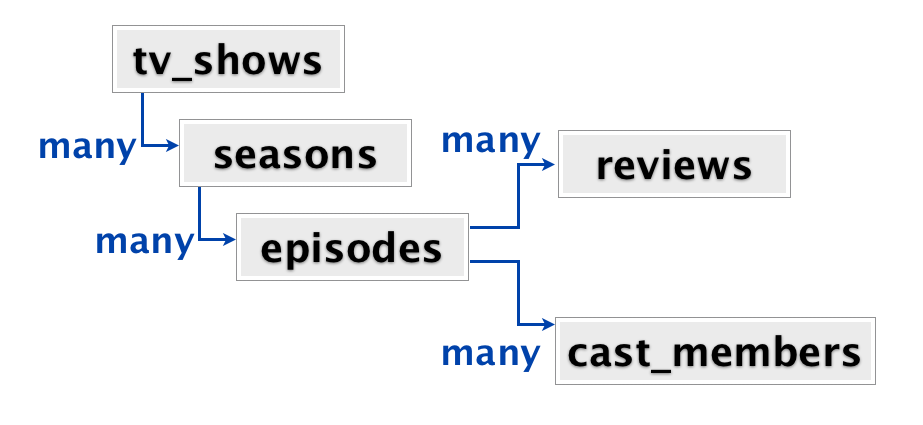
A much better model would be something like this:
- Actors
- [episode ids]
- TV shows
- [seasons ids]
- Seasons
- [review ids]
- [episode ids]
- Episodes
- [actor ids]
Now, I am not settled in my own mind if it would be better to have a single season document per season, containing all episodes, reviews, etc. Or if it would be better to have separate episode documents.
What I do know is that having a single document that large is something that I want to avoid. And yes, this is a somewhat relational model. That is because what you are looking at is a list of independent aggregates that have different reasons to change.
Later on in the post the author talks about the problem when they wanted to show “all episodes by actor”, and they had to move to a relational database to do that. But that is like saying that if you stored all your actors information as plain names (without any ids), you would have hard time to handle them in a relational database.
Well, duh!
Now, as for the Disapora project issues. They appear to have been doing some really silly things there. In particular, let us store store the all information multiple times:

You can see for example all the user information being duplicated all over the place. Now, this is a distributed social network, but that doesn’t call for it to be stupid about it. They should have used references instead of copying the data.
Now, to be fair, there are very good reasons why you’ll want to duplicate the data, when you want a point in time view of it. For example, if I commented on a post, I probably want my name in that post to remain frozen. It would certainly make things much easier all around. But if changing my email now requires that we’ll run some sort of a huge update operation on the entire database… well, it ain’t the db fault. You are doing it wrong.
Now, when you store references to other documents, you have a few options. If you are using RavenDB, you have Include support, so you can get the associated documents easily enough. If you are using mongo, you have an additional step in that you have to call $in(the ids), but that is about it.
I am sorry, but this is blaming the dancer blaming the floor.
More posts in "re" series:
- (05 Dec 2025) Build AI that understands your business
- (02 Dec 2025) From CRUD TO AI – building an intelligent Telegram bot in < 200 lines of code with RavenDB
- (29 Sep 2025) How To Run AI Agents Natively In Your Database
- (22 Sep 2025) How To Create Powerful and Secure AI Agents with RavenDB
- (29 May 2025) RavenDB's Upcoming Optimizations Deep Dive
- (30 Apr 2025) Practical AI Integration with RavenDB
- (19 Jun 2024) Building a Database Engine in C# & .NET
- (05 Mar 2024) Technology & Friends - Oren Eini on the Corax Search Engine
- (15 Jan 2024) S06E09 - From Code Generation to Revolutionary RavenDB
- (02 Jan 2024) .NET Rocks Data Sharding with Oren Eini
- (01 Jan 2024) .NET Core podcast on RavenDB, performance and .NET
- (28 Aug 2023) RavenDB and High Performance with Oren Eini
- (17 Feb 2023) RavenDB Usage Patterns
- (12 Dec 2022) Software architecture with Oren Eini
- (17 Nov 2022) RavenDB in a Distributed Cloud Environment
- (25 Jul 2022) Build your own database at Cloud Lunch & Learn
- (15 Jul 2022) Non relational data modeling & Database engine internals
- (11 Apr 2022) Clean Architecture with RavenDB
- (14 Mar 2022) Database Security in a Hostile World
- (02 Mar 2022) RavenDB–a really boring database
Comments
Comment preview