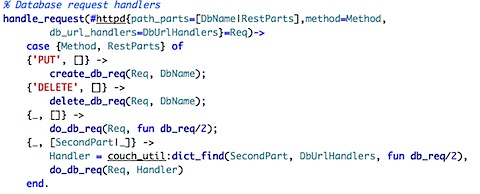
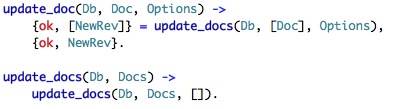
Jan has corrected a misconception that I had here, where I assumed that PUT was create and POST was update. Apparently this is not quite correct. A PUT request will update/create a new document with a user supplied name, while a POST request will create a new document with a server generated name.
That narrows down my search for "create new document" code path again. Here is the method in couch_httpd_db that handles a POST request on a document.

It parse the form, get the revision of the document, and then it calls to open_doc_revs, which we haven't explored so far. I feel confident that I understand what this is doing, however:

I'll not show the open_doc_revs_int, because it is too big, but it contains some references that so far I haven't encountered. Specifically, couch_key_tree, which I don't think that I seen before, and to get_full_doc_infos, which looks like this:

Oh, now we are on a more familiar territory. Lookup performs a search on a binary tree, and we have gone over it in depth before. However, we can now see that the we pass to it a fulldocinfo_by_id_tree... I don't think we have explored how CouchDB make use of the btree, so let us head to the db structure and see what else we have there.

Here is what I know about this structure at the moment. db_header container the data that is actually written to the file, while db is the in memory structure. Not sure what write_version is all about, update_seq looks like the the internal sequence number for CouchDB. I don't think that I have even seen the concept of stream before, but it is there, and look like most stream implementations that I am already familiar with.
get_state on that returns a {Position, BytesRemaining}, since I don't understand how this is used at the moment, I don't understand why this is important. fulldocsinfo_by_id_btree_state contains the root of the btree, and the same holds for docinfo_by_seq_btree_state, I assume that local_docs_btree_state is also the same.
purge_seq is a counter for the last purge (physical delete), and it is used in conjunction with the views in order to ensure that there are no purged documents in the view. purged_docs keeps track of the documents that were last purged.
db, the runtime structure, is considerably more interesting. It took me a while to figure out where it is created, but I finally found the init_db function in couch_db_updater:

The first part is to open the summary_state stream, still not sure what this is about, though. We then define a comparison function for use when opening the fulldocsinfo btree, and we pass several additional functions when we create the btree. Reduce is usually used when we compact the tree, and to get information about the btree (such as count of documents). The join and split also prepare the data to be written to disk in a consistent fashion.
I don't like the name join/split. The internal names, assemble and extract seems to be much more accurate.
Finally, we get to the actual creation of the db structure itself. An interesting thing to note is that only the update_pid is filled. Since CouchDB implements the many readers / single writer, I assume that this is how we ensure the single reader, because only a single process ever handle writes to the DB. I am assuming for now that main_pid is for readers, and compactor_pid if for compacting (obviously). I'll track them next.
Well, that took some doing, the main_pid is set in the couch_db_updater:init (the same function that calls the init_db function):
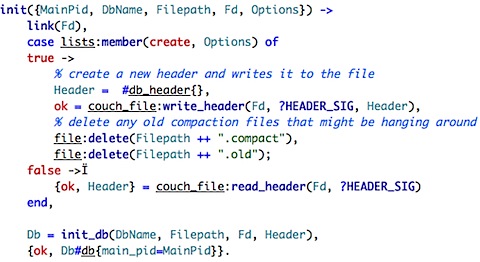
I had hard time tracking this because I couldn't figure out what who was calling couch_db_updater:init (and what is the MainPid). Usually, in gen_server processes, there is a start_link function that you call, but in this case, there wasn't. Some digging revealed that the couch_db process is the one that actually call start_link on the couch_db_updater. I wonder if this is a common pattern in erlang, because it sure did caught me by surprise.
So main_pid is the couch_db process, and update_pid is the couch_db_updater. It actually goes a lot further than that. couch_db_updater doesn't actually have a public interface. It looks like couch_db is the one that exposes the interface, and send synchronous messages to the couch_db_updater process:

That is the way in which CouchDB ensures that we have only a single write, I presume. Compaction is handled in couch_db_updater as well, the implementation is interesting:
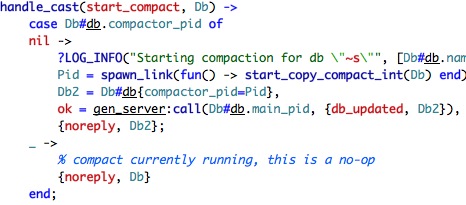
We create a new process and return before we finish compacting. It is interesting because it is the first example of explicit concurrency that I saw. Let us dig a bit better into start_copy_compact_int, which is pretty straight forward:
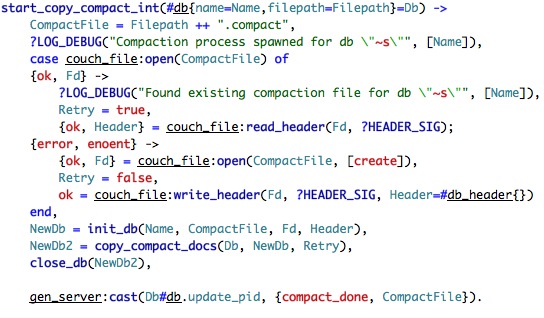
This just create a new file, init a database and call_compact_docs, finishing by notifying the updater that it finished compacting. copy_compact_docs is interesting in itself:
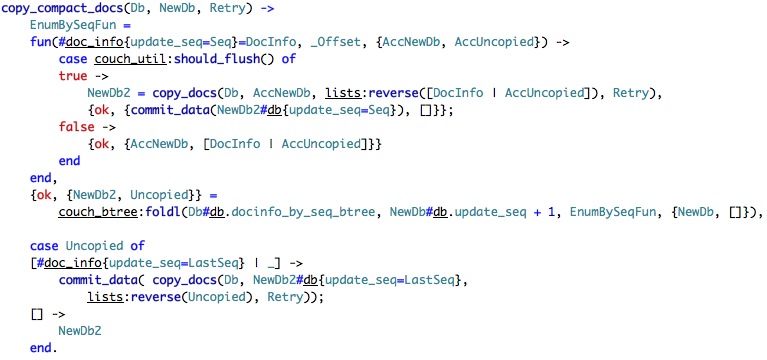
We start by defining the EnumBySeqFun, which batches documents to write to disk until should_flush returns true. should_flush is funny, it check memory thresholds and flush to disk whenever there is about 10 MB of data ready to be flushed.
The usage of foldl here is a good reason to go back and examine it in more details:

And fold is defined as:

So we have this stream_node, whatever that is, let us take an additional look.
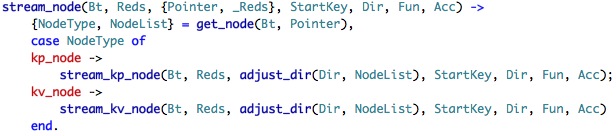
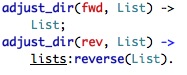
We are already familiar with get_node(), but adjust_dir and stream_kp_node and stream_kv_node are new. The first is easy:
Let us explore stream_kv_node, which is likely to be easier than stream_kp_node.

This is slightly complex. We start by defining the drop off point (smaller / greater from the current key). The important bit is in the last function, the call to our function and the recursion back into the function. As a reminder, here is the function that we pass:
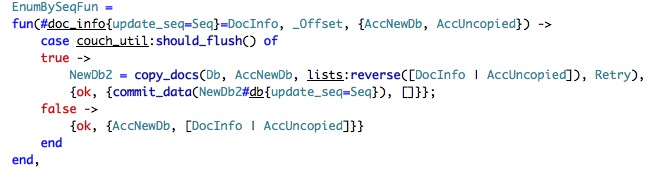
I hope that this make it clear how this works. We simply stream all the items to the function, and it copies it. Note that an important subtlety is that we have several btree over the same data (we will touch down in a bit) and in this case we are only copying the items that are greater than the update_seq in the current DB. Still not sure what this update_seq is all about. We will go all the way back to copy_compact_docs_int's last line, where it notify the updater that it finished the current compaction. This message arrive to this method:

This looks complex, but it really isn't. It is simply opening the new database, and checking if the current update_seq equal to the latest in the new database. If it isn't, we restart the process. If it is, then we copy the local documents (not sure why they get special treatment, and it looks like it is expected to have very few of them), move the files and move on with our lives.
Now, it looks like update_seq is updated whenever someone make a change to the database, but let us verify this, shall we?
Looking at couch_db_updater:update_docs_int, we can see that the update_seq is updated for each new document that is modified (see merge_rev_trees).
Okay, that was interesting. But I still don't know how we save a document to disk. Let us go back to couch_db:update_docs, and see what is going on here. This is pretty complex, so we will break it apart to discrete pieces.
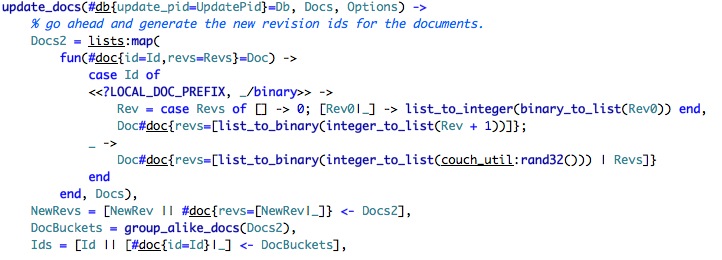
We start by generating a new revision for the documents. Note that in the case local revisions, we just increment the revision, if it is a standard document, we generate a random revision number. I think that this is done in order to support farm wide revisions, so if I update document #1 in server A and in server B, I get two different revisions, which would be detected as conflicts.
We extract all the new revisions, group all the documents by id and extract all the ids. So far, so good. Let us see the rest of the function:
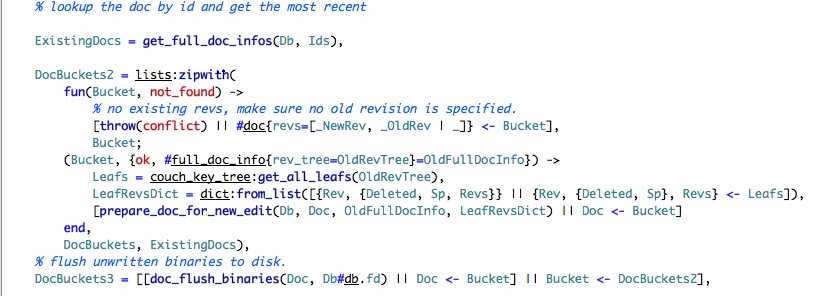
We get the current existing documents, and then we merge the existing with the new bucket. That requires some explanation.
The first function clause uses list comprehensions in order to ensure that if we couldn't find a document in the DB, we didn't specify a previous version. The second is more complex and require us to understand about key trees. CouchDB defines them as:

Based on that and the dict:from_list arguments, we can deduct what the structure of a revision is. It should be noted that it looks like there is an expectation that the number of revisions wouldn't be too big. This make sense, CouchDB does keep previous versions, but it make no guarantees about their life spans. Also, we should note that we have both revs and rev_tree, I am not quite sure why.
The last line in the zipwith function is prepare_doc_for_new_edit, which is called for each document, let us take a look at it.
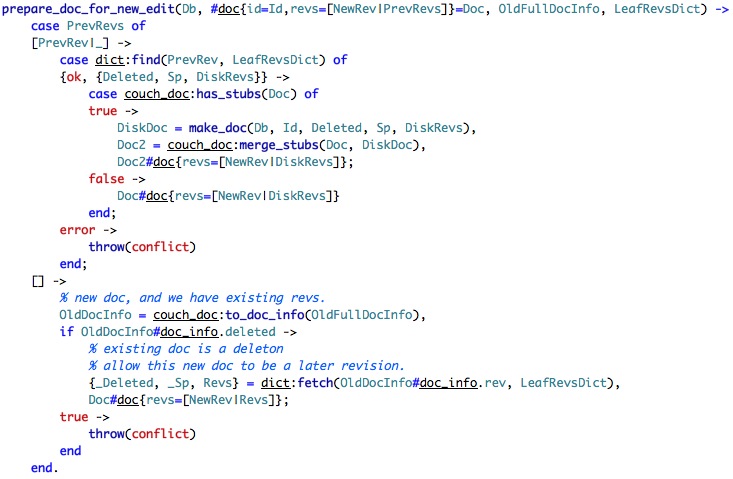
This is an example of how condense functional code can get. Let us see what it does:
- Get the new revisions and all the previous revisions
- If the previous revisions has a value, it perform a lookup based on the revision to the revision tree, to get the revision information. (Which answers the question of why we need both revs and rev_tree. revs is an ordered list of revision keys. rev_tree is apparently the metadata).
- Now, the LeafRevsDict contains only the most recent one, so failing to find it in the dictionary means that we trying to update a non current version, so we error.
- I am not sure what a stub is, but the rest of it seems pretty simple.
The last part is interesting, however, we check that we aren't trying to create a new document with the same id as existing one (although we allow it if that document is deleted).
After the call to zipwith(), we have a call to doc_flush_binaries, which we totally ignored so far. It flushes all the documents to disk, it is not really interesting, it is dealing with writing the attachments to disk. I am not quite sure what is going on (it is complex), mostly because I don't follow to which file it is writing. Or, to be rather more exact, I am not following how the attachment can be written to a different file, which is what the code seems to imply.
Anyway, the code there is pretty clear about what is going on, we append to the current file (except if we write to a different file, again, not following that) and update the in memory structure of the document to point to the range of data that each attachment contains.
Let us look at the last part of the couch_db:update_docs:
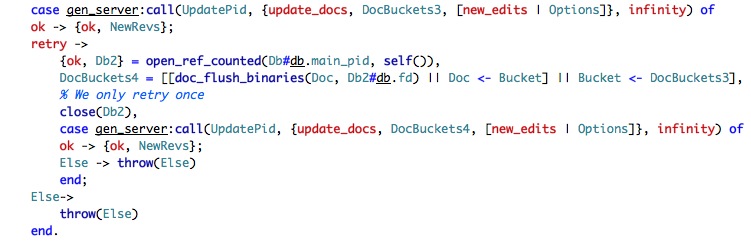
And is looks like we have hit the place where it is actually happening. We call to the couch_db_updater in order to do the actual update, and we make be asked to retry (this will require more study), in which case we do try.
Let us look at update_docs at the couch_db_updater.
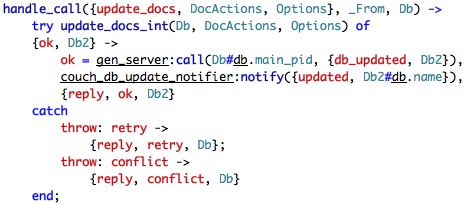
Sigh, I can feel it in my waters, update_docs_int is going to be complex... once more, we will try to divide and conquer.
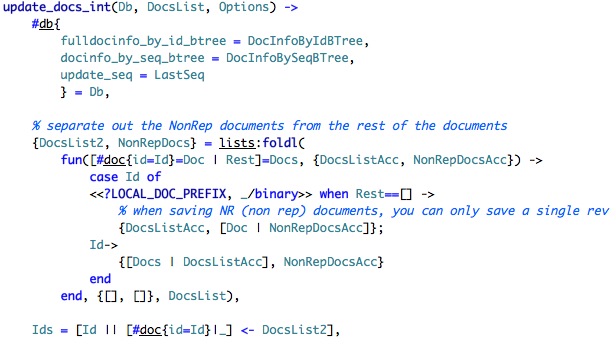
We start by extracting variable from the Db, then we split the list based on whatever this is local or not. NonRep documents (local) are not replicated, have only a single version and are expected to have very few of them. I still don't know what is the use case for those, however. It looks like DocsList is a list of lists of docs, probably this is the buckets that we had to deal with earlier.
We finish the snipper by extracting the ids from the documents, what comes next?
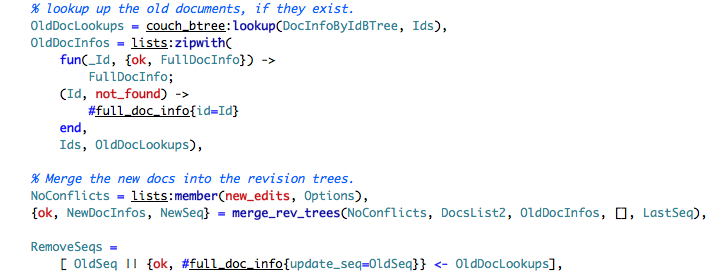
We lookup the existing documents, and then we merge them into a file info (note that we create a new full_doc_info with just the id if this is a new file). We then create the new doc infos by calling merge_rev_trees. We will ignore the implementation for now.
Finally, we gather all the sequences that we would like to remove. Moving on, we see that we start by updating the local docs and then flushing the trees. Both of which looks promising for my quest to understand how the data is stored on the disk:

update_local_docs just modify the in memory btree, so I am not going to show it, flush_trees should be more interesting, based on just the comment.
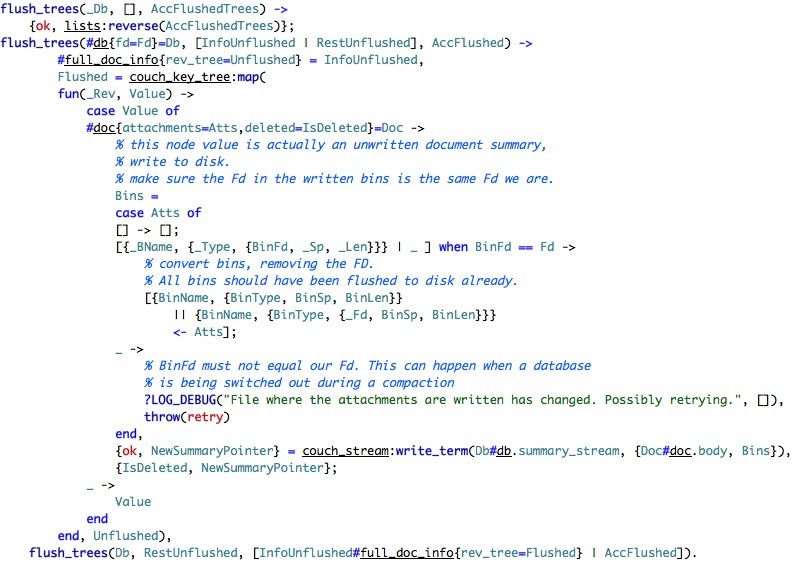
This is interesting. What we see here is that we write the attachment references and the document body to the summary stream. That is interesting, because I am still not sure what the summary stream is. Note that here we have the issue of writing to a file during compaction, so we ask the higher level code to retry that again.
We still have to see how the indexes are maintained, but that just update the in memory structure, the real bit happens next:
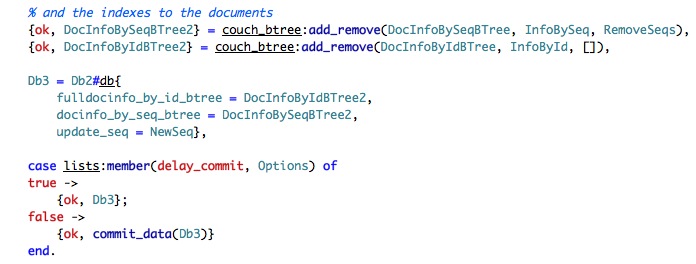
Here we see our good old friend the btree, and we add/remove the new index to the file. We have seen how this works here. We finish by updating the Db structure with the new values and committing the data.
I now feel that I have a much better understanding on how CouchDB file handling works. Except that I still don't know what this summary stream is. That is a topic for later, though.